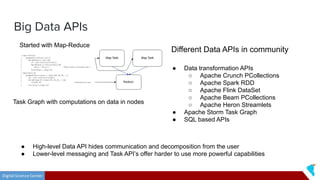
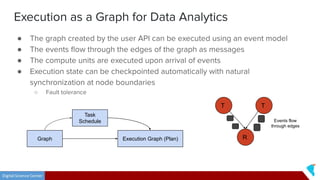
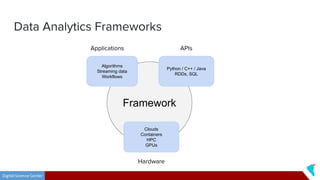
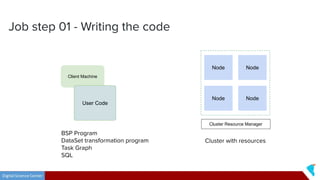
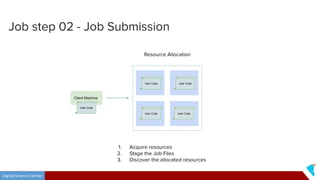
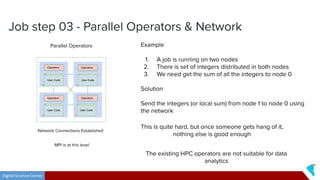
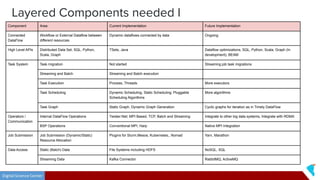
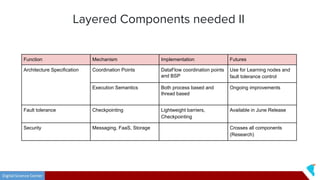
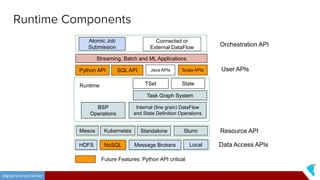
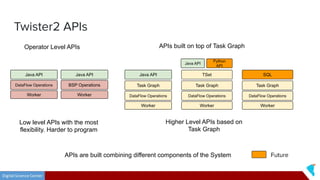
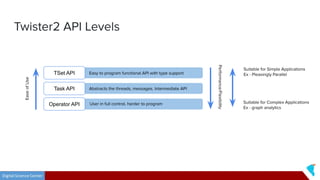
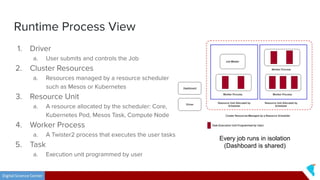
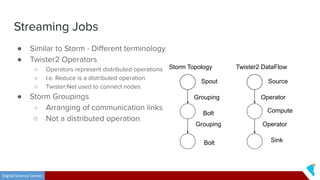
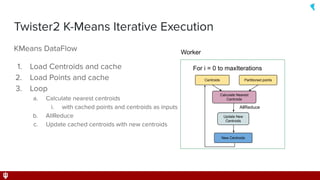
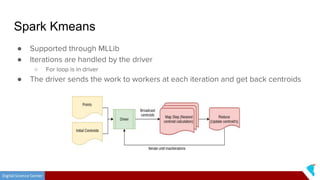
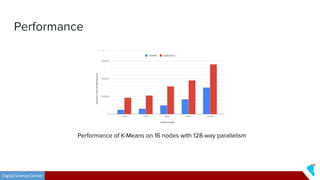
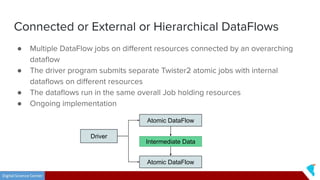
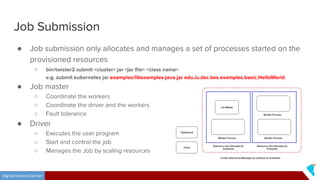
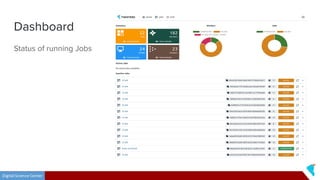
This document discusses Twister2, an open source dataflow system for batch and streaming data processing. It provides high-level and lower-level APIs and can execute tasks on HPC clusters, clouds, and containers. The document outlines Twister2's components like its task graph system, data access APIs, and programming models. It also provides examples of how batch and streaming jobs are configured and run on Twister2.