Downloaded 17 times





![My Background
Playtika, VP of Big Data
Flume, Kafka, Spark, ZK, Yarn, Vertica. [Jay Kreps (Kafka), Michael Armbrust (Spark SQL),
Chris Bowden (Dev Demigod)]
MIS Director of several start-up companies
Dataflex a 4GL RDBMS. [E.F. Codd]
Self-employed Consultant
Intercept Dataflex db calls to store and retrieve data to/from Btrieve and IBM DB2
Mainframe
FoxPro, Sybase, MSSQL Server beta
Design Patterns: Elements of Reusable Object-Oriented Software [The Gang of Four]
Microsoft; Dev Manager, Architect CLR/.Net Framework,
Product Unit Manager Technical Strategy Group
Inventor of “Shuttle”, a Microsoft product in use since 1999
A distributed ETL based on MSMQ which influenced MSSQL DTS (SQL SSIS)
[Joe Celko, Ralph Kimball, Steve Butler (Microsoft Architect)]
Twitter, Manager of Analytics Data Warehouse
Core Storage; Hadoop, HBase, Cassandra, Blob Store
Analytics Infra; MySQL, PIG, Vertica (n-Petabyte capacity with Multi-DC DR)
[Prof. Michael Stonebraker, Ron Cormier (Vertica Internals)]
https://www.linkedin.com/in/jackglinkedin
5](https://image.slidesharecdn.com/jackgsparkug201512077-151208203407-lva1-app6891/85/Jack-Gudenkauf-sparkug_20151207_7-5-320.jpg)





![Real-Time
Messaging
Apache
Kafka™
Analytics of [semi]Structured [non]Relational Data Stores
Real-Time Streaming ✓Machine Learning
✓ Semi-Structured Raw JSON Data
✖Structured (non)relational Parquet Data
Structured Relational and Aggregated Data
Resilient Distributed
Datasets
Apache Spark™ Hadoop™
Parquet™ ✓ ✓ ✖
REST API
Or Local
Kafka
Application
Application
Game
Applications
Unified
Schema
JSON
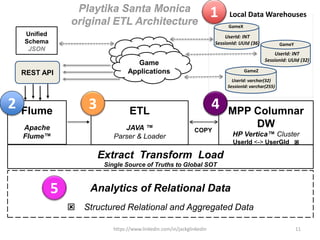
Local Data Warehouses
MPP Columnar DW
HP Vertica™
MPP
1 2
3
P a r a l l e l i z e d S t r e a m i n g
T r a n s f o r m a t i o n
L o a d e r
4
5
New PSTL
Architecture
New PSTL
Architecture
https://www.linkedin.com/in/jackglinkedin
13
Bingo Blitz
UserId: INT
SessionId: UUId (36) Slotomania
UserId: INT
SessionId: UUId (32)
WSOP
UserId: varchar(32)
SessionId: varchar(255)](https://image.slidesharecdn.com/jackgsparkug201512077-151208203407-lva1-app6891/85/Jack-Gudenkauf-sparkug_20151207_7-13-320.jpg)

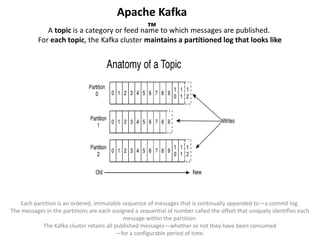
![Spark RDD
A Resilient Distributed Dataset [in Memory]
Represents an immutable, partitioned collection of elements that can be operated on in parallel
Node 1 Node 2 Node 3 Node…
RDD 1
RDD 1
Partition 1
RDD 1
Partition 2
RDD 3 RDD 3
Partition 2
RDD 3
Partition 3
RDD 3
Partition 1
RDD 2
RDD 2
Partition
1 to 64
RDD 2
Partition
65 to 128
RDD 2
Partition
193 to 256
RDD 2
Partition
129 to 192
RDD 1
Partition 3](https://image.slidesharecdn.com/jackgsparkug201512077-151208203407-lva1-app6891/85/Jack-Gudenkauf-sparkug_20151207_7-17-320.jpg)
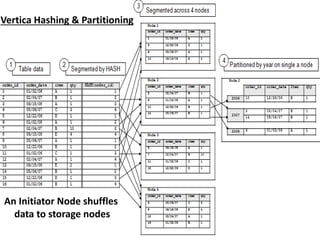

![{"appId": 3, "sessionId": ”7”,
"userId": ”42” }
{"appId": 3, "sessionId": ”6”,
"userId": ”42” }
Node 1 Node 2 Node 3 Node 4
3 Import recent Sessions
Apache Kafka Cluster
Topic: “appId_1” Topic: “appId_2” Topic: “appId_3”
old new
Kafka Table
appId,
TopicOffsetRange,
Batch_Id
SessionMax Table
sessionGIdMax Int
UserMax Table
userGIdMax Int
appSessionMap_RDD
appId: Int
sessionId: String
sessionGId: Int
appUserMap_RDD
appId: Int
userId: String
userGId: Int
appSession
appId: Int
sessionId:
varchar(255)
sessionGId: Int
appUser
appId: Int
userId:
varchar(255)
userGId: Int
1 Start a Spark Driver
per APP
Node 1 Node 2 Node 3
4 Spark Kafka [non]Streaming job per APP
(read partition/offset range)
5 select for
update;
update max
GId
5 Assign userGIds To
userId
sessionGIds To
sessionId
6 Hash(userGId) to
RDD partitions with
affinity
To Vertica Node(s)
7
userGIdRDD.foreachPartition
{…stream.writeTo(socket)...}
8 Idempotent: Write
Raw JSON to hdfs
9 Idempotent: Write
Parsed JSON to .ORC
hdfs
10 Update
MySQL
Kafka Offsets
{"appId": 2, "sessionId": ”4”,
"userId": ”KA” }
{"appId": 2, "sessionId": ”3”,
"userId": ”KY” }{"appId": 1, "sessionId": ”2”,
"userId": ”CB” }
{"appId": 1, "sessionId": "1”,
"userId": ”JG” }
4 appId {Game events, Users, Sessions,…}
Partition 1..n RDDs
5 appId Users & Sessions
Partition 1..n RDDs
5 appId
appUserMap_RDD.union(assignedID_RDD)
6 appId Users & Sessions
Partition 1..n RDDs
7 copy jackg.DIM_USER
with source SPARK(port='12345’,
nodes=‘node0001:4, node0002:4,
node0003:4’) direct;
2 Import Users
Apache Hadoop™
Spark™ Cluster
HPE Vertica™ Cluster](https://image.slidesharecdn.com/jackgsparkug201512077-151208203407-lva1-app6891/85/Jack-Gudenkauf-sparkug_20151207_7-20-320.jpg)

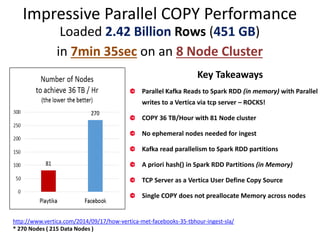


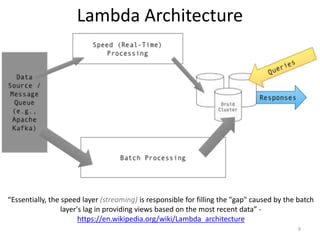
This document describes a Parallel Streaming Transformation Loader (PSTL) that uses Kafka, Spark, and Vertica for real-time data ingestion and analytics. It summarizes the PSTL as follows: 1. The PSTL ingests streaming data from Kafka into Spark RDDs in parallel. 2. Spark is used to transform the data, including assigning IDs and hashing records to partitions. 3. The transformed data is written in parallel from the Spark partitions directly to Vertica for analytics and querying. 4. Vertica demonstrated impressive parallel copy performance of 2.42 billion rows in under 8 minutes using this approach.