Downloaded 284 times



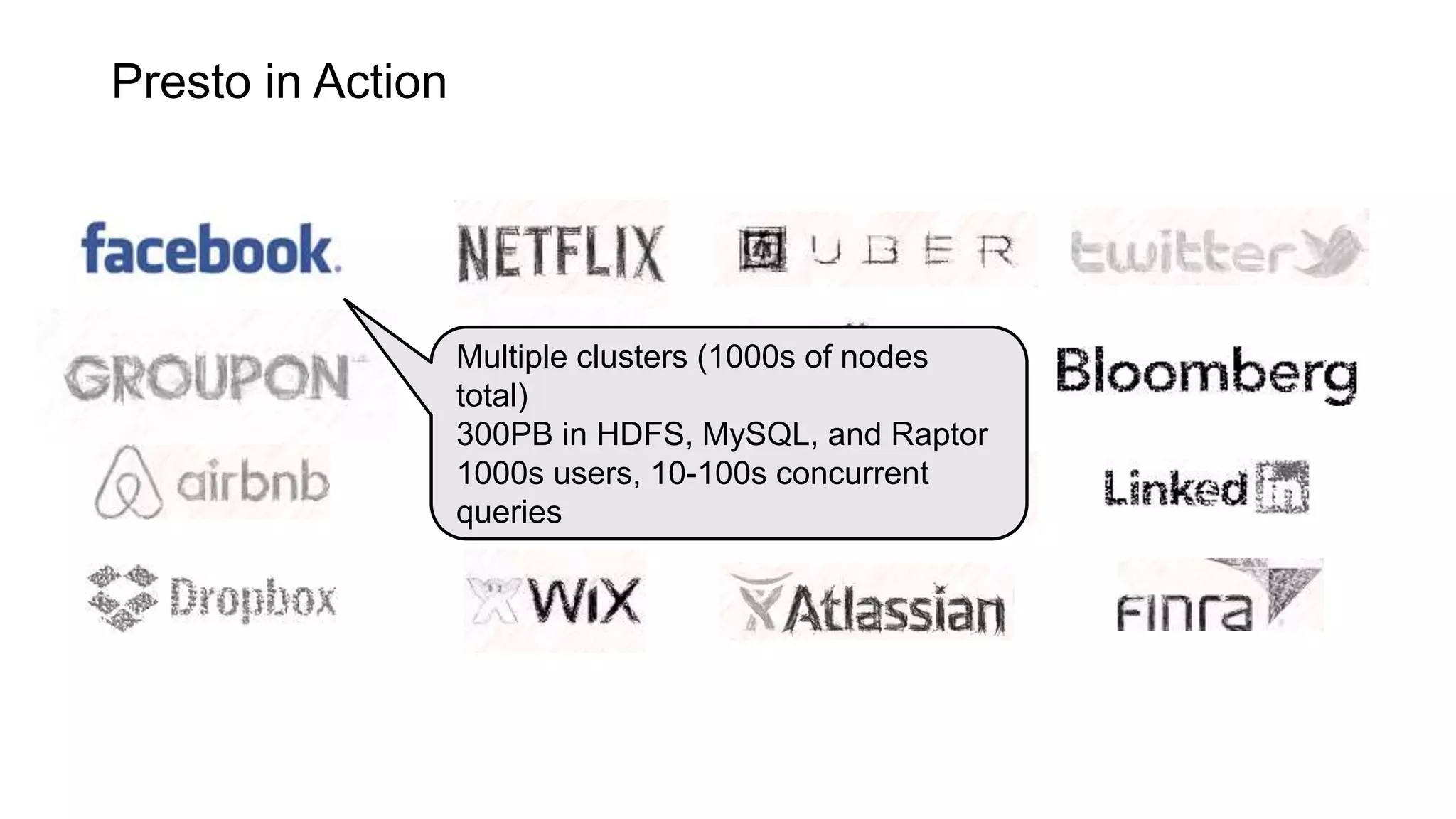



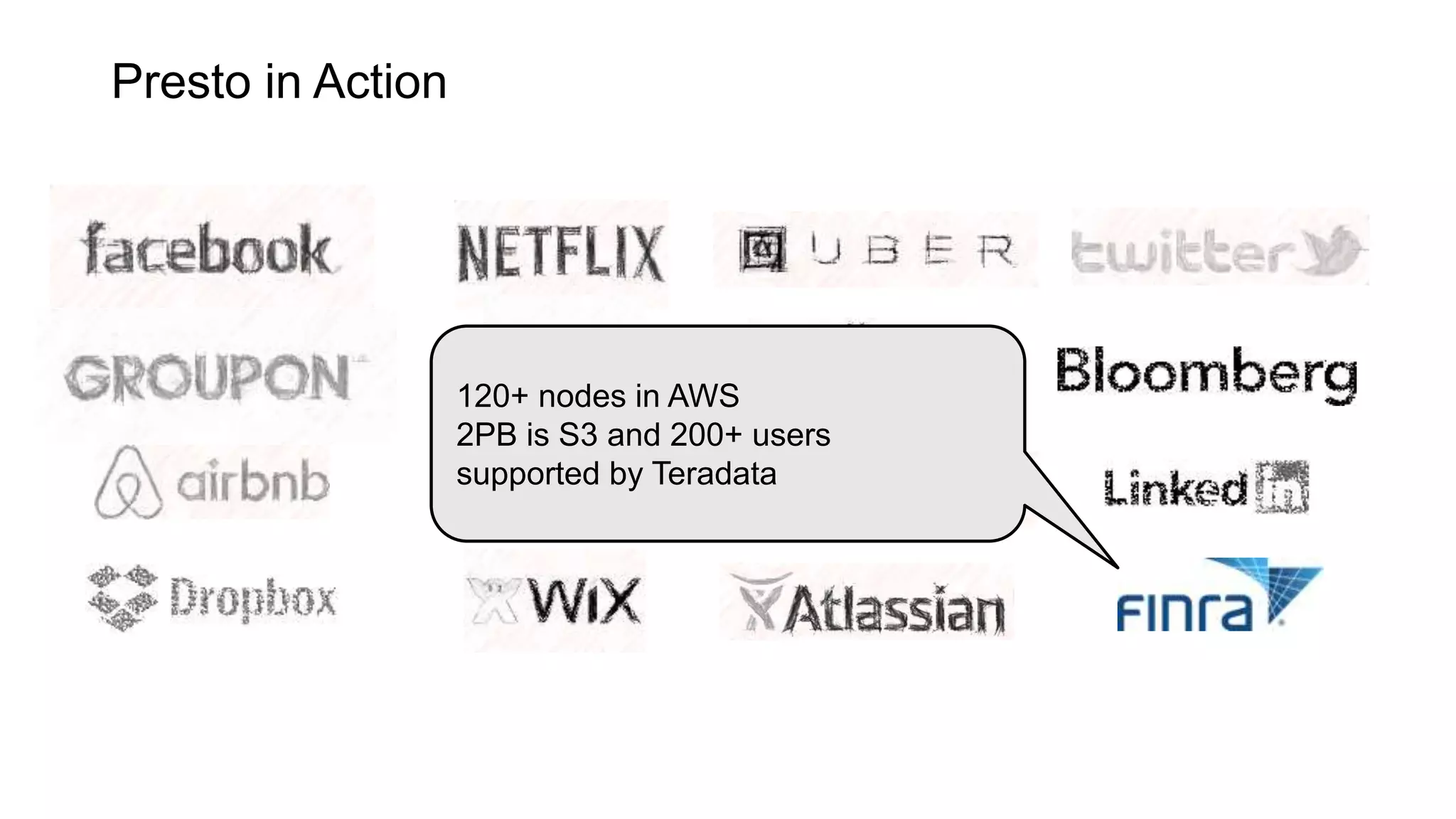
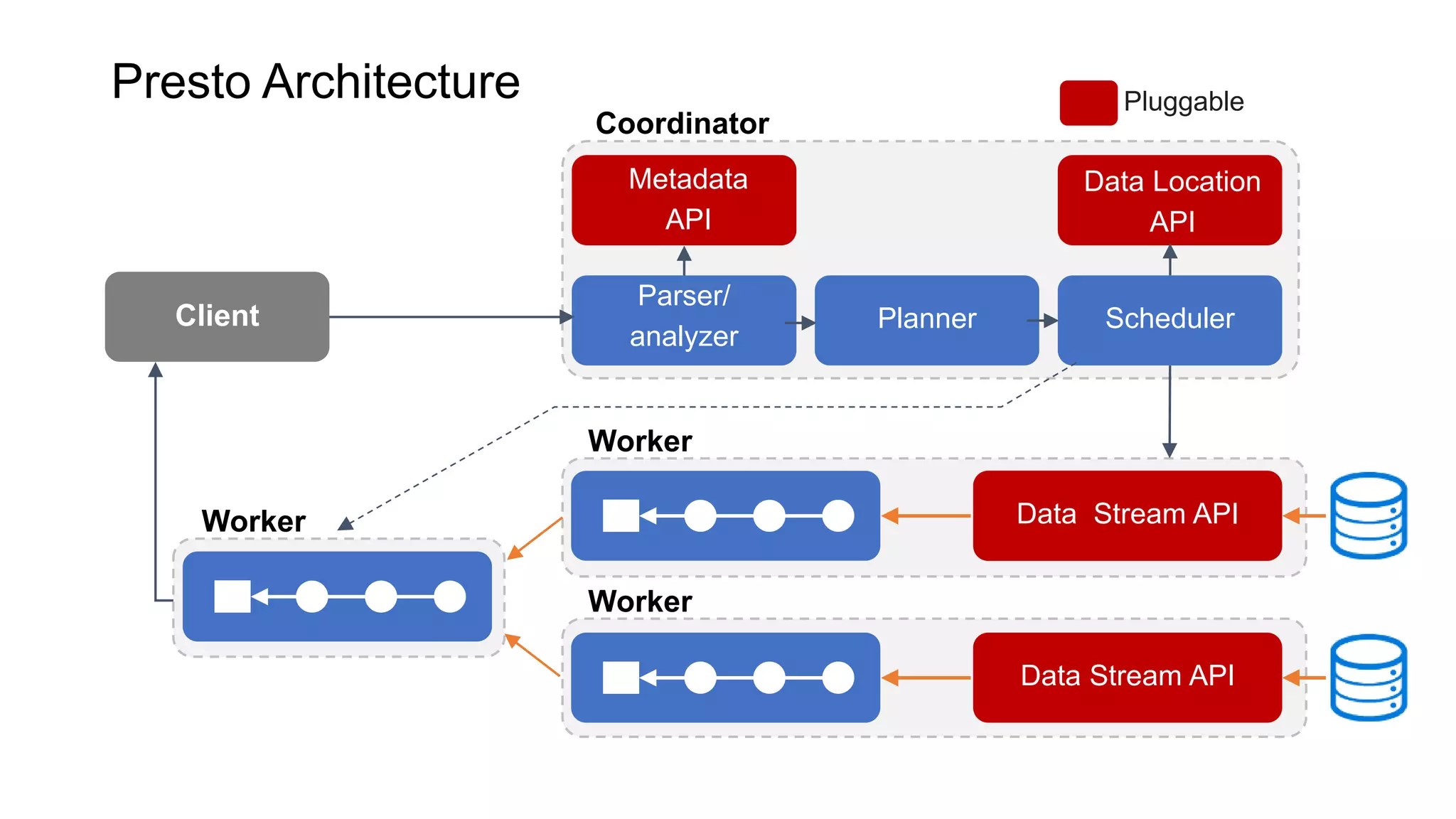

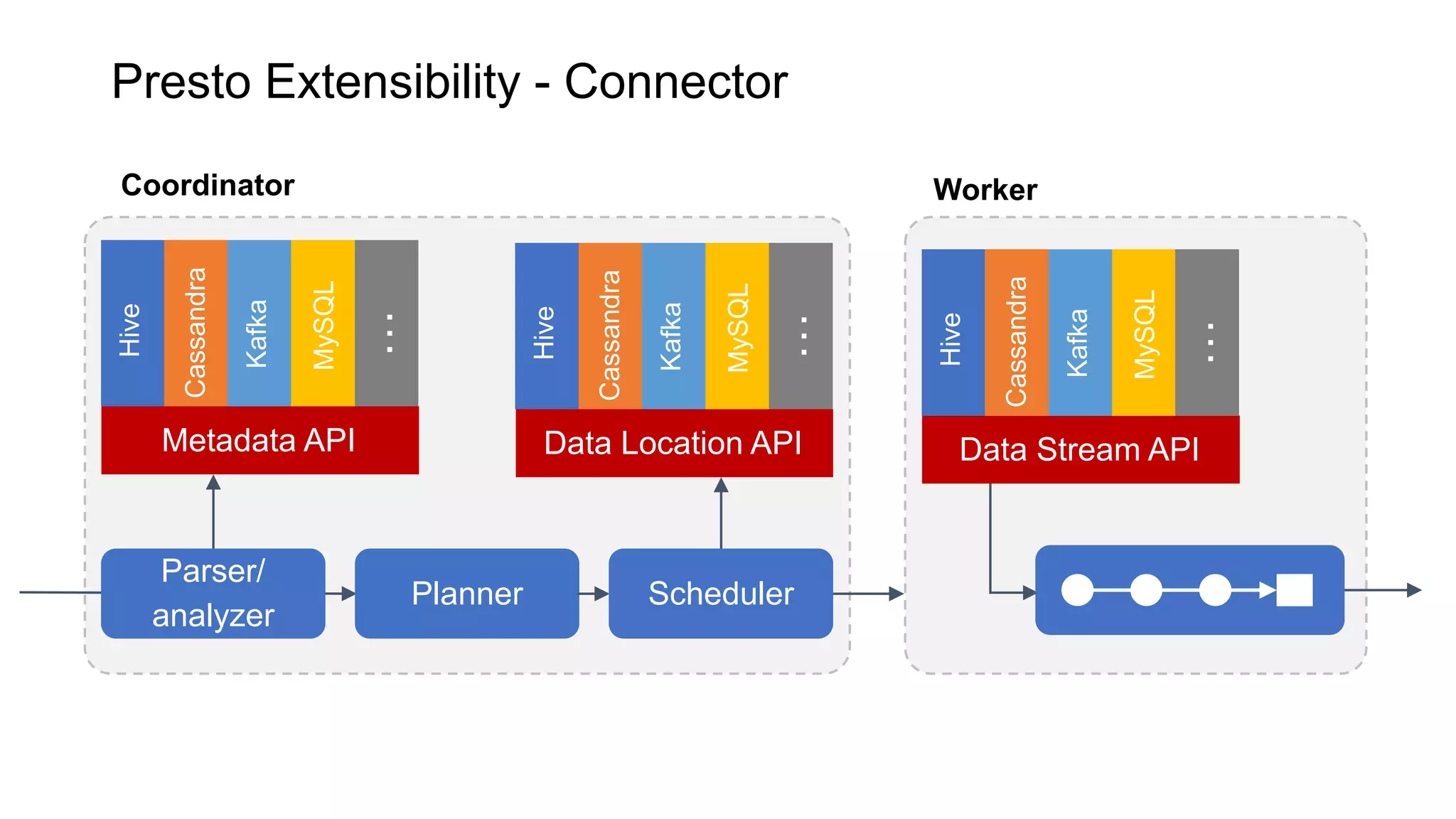

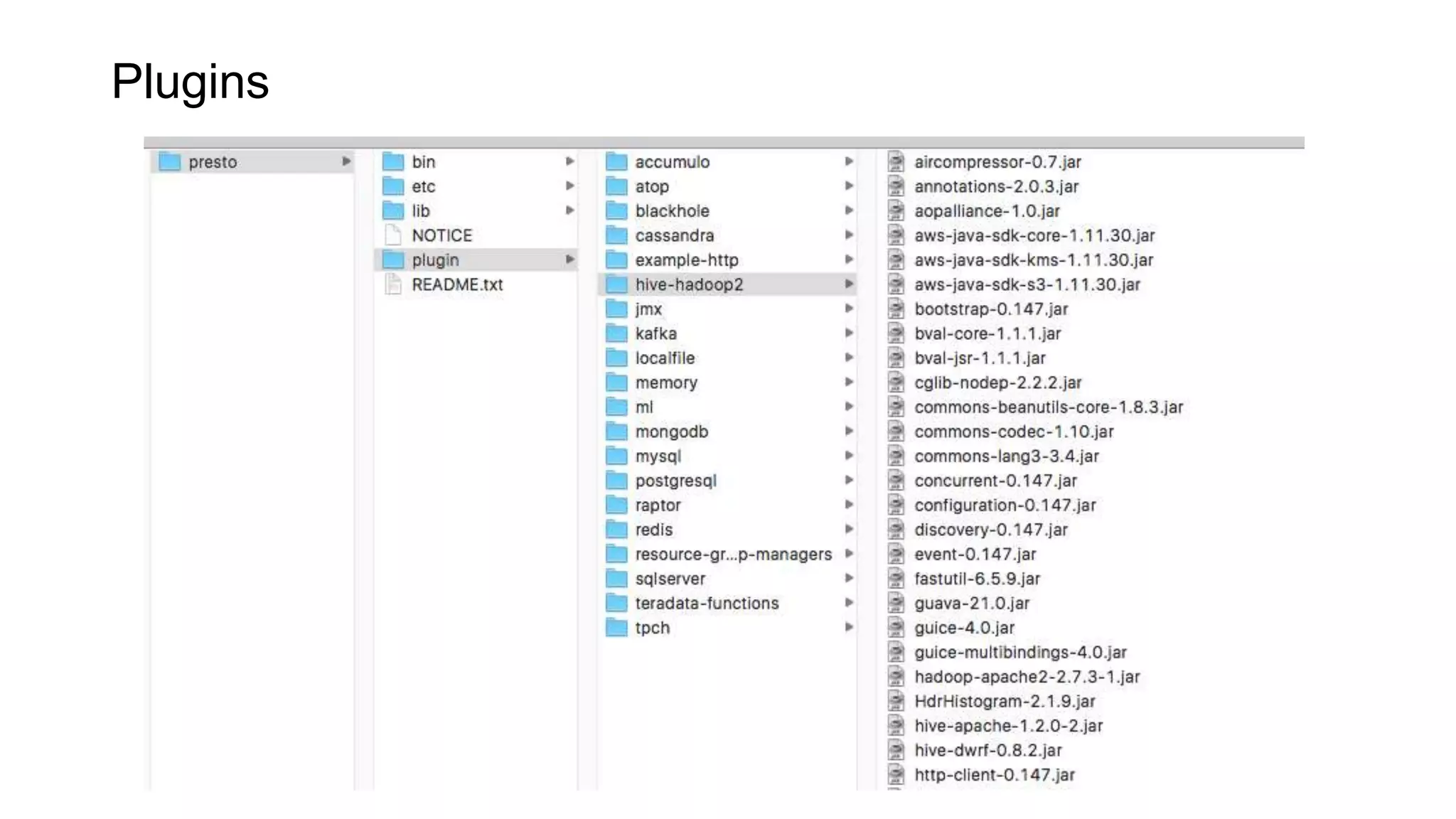
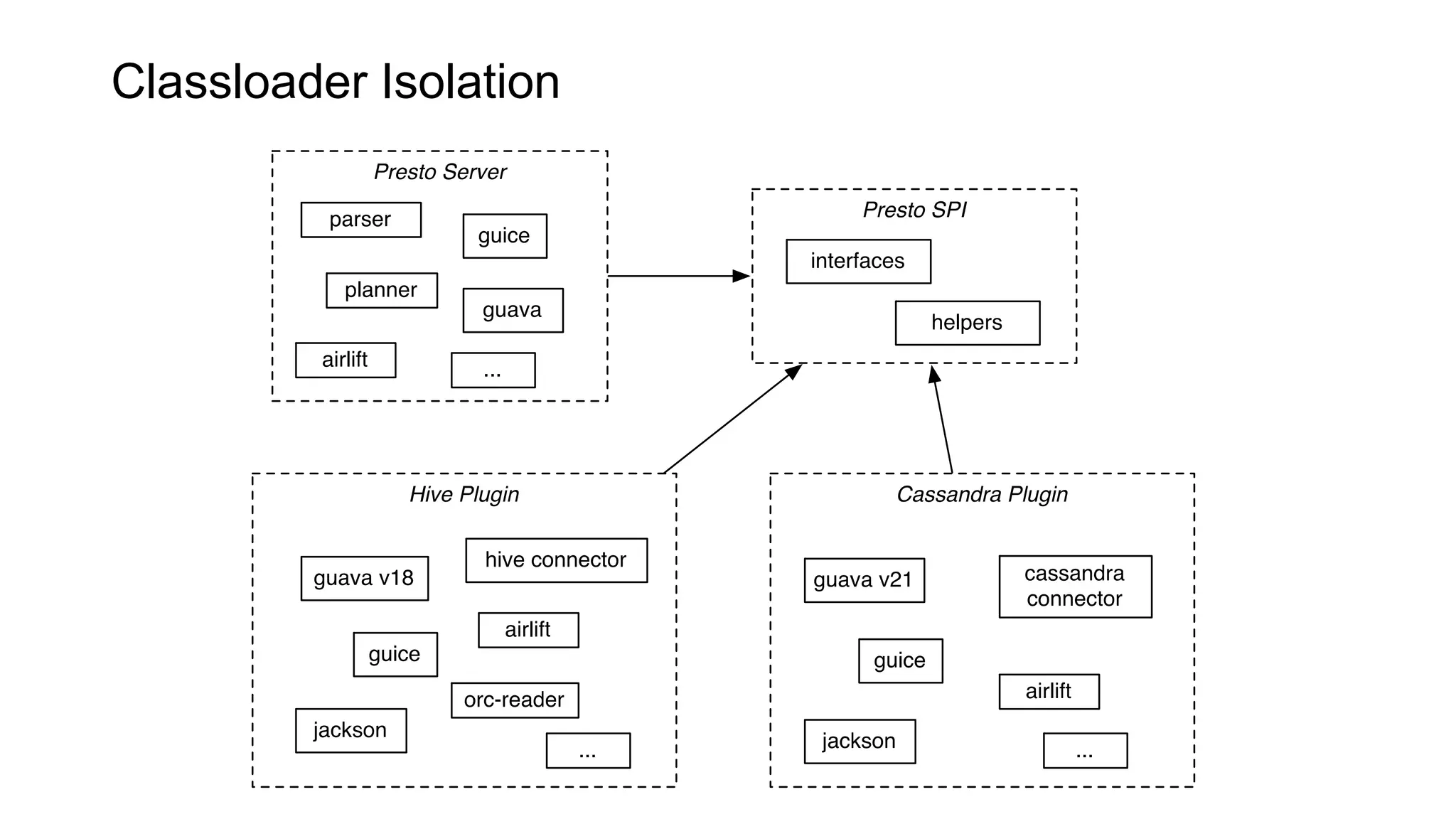
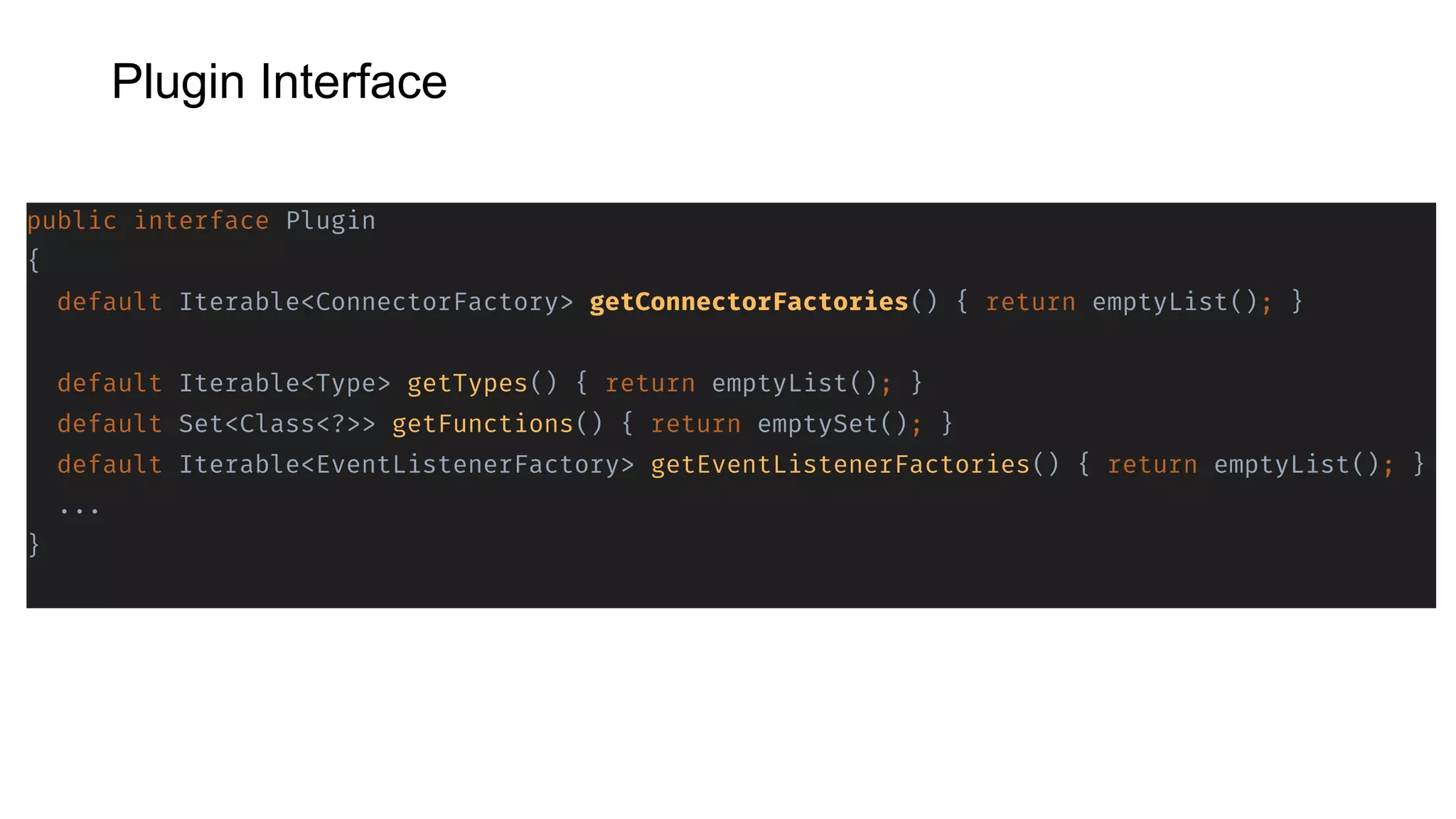
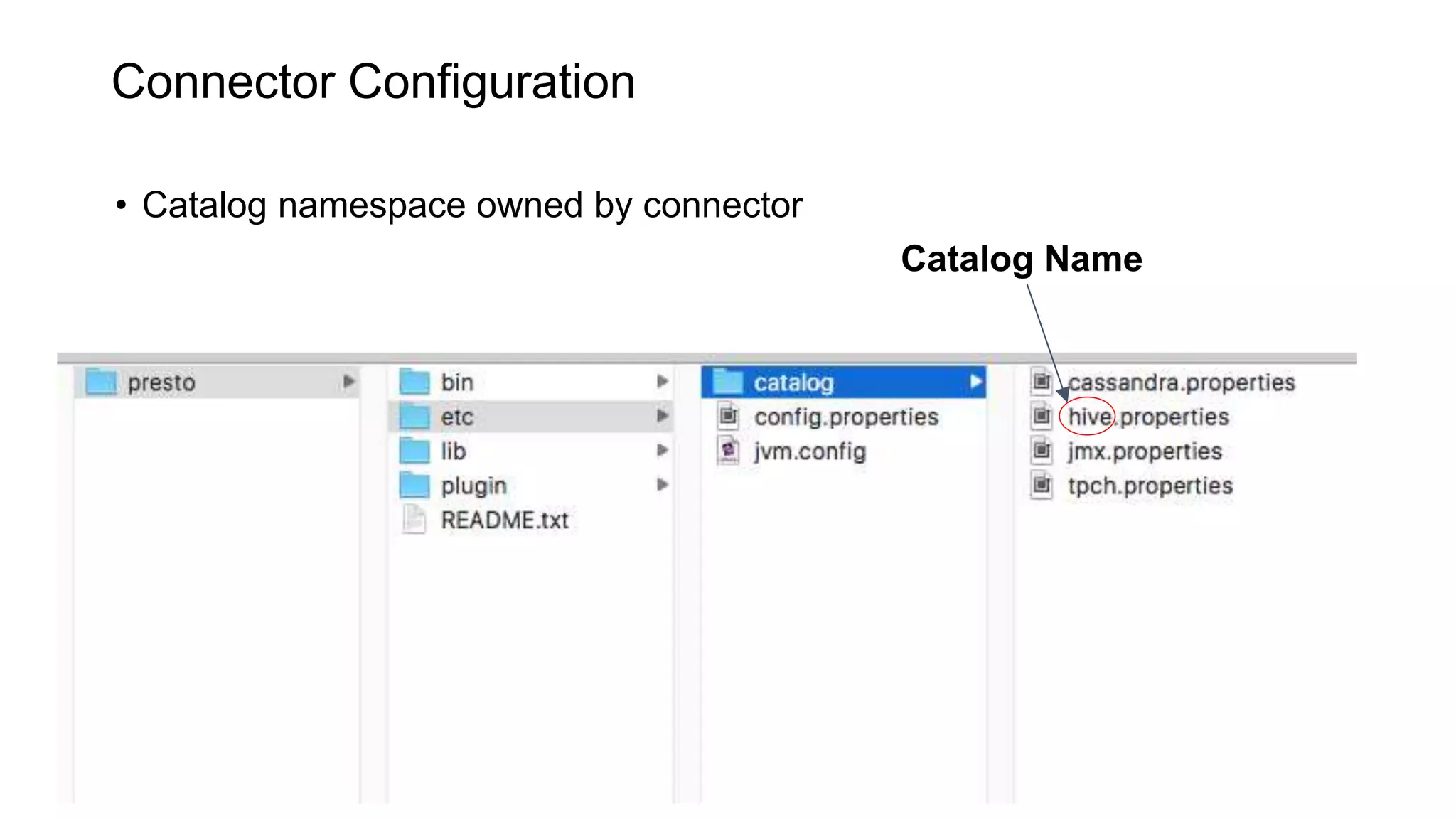
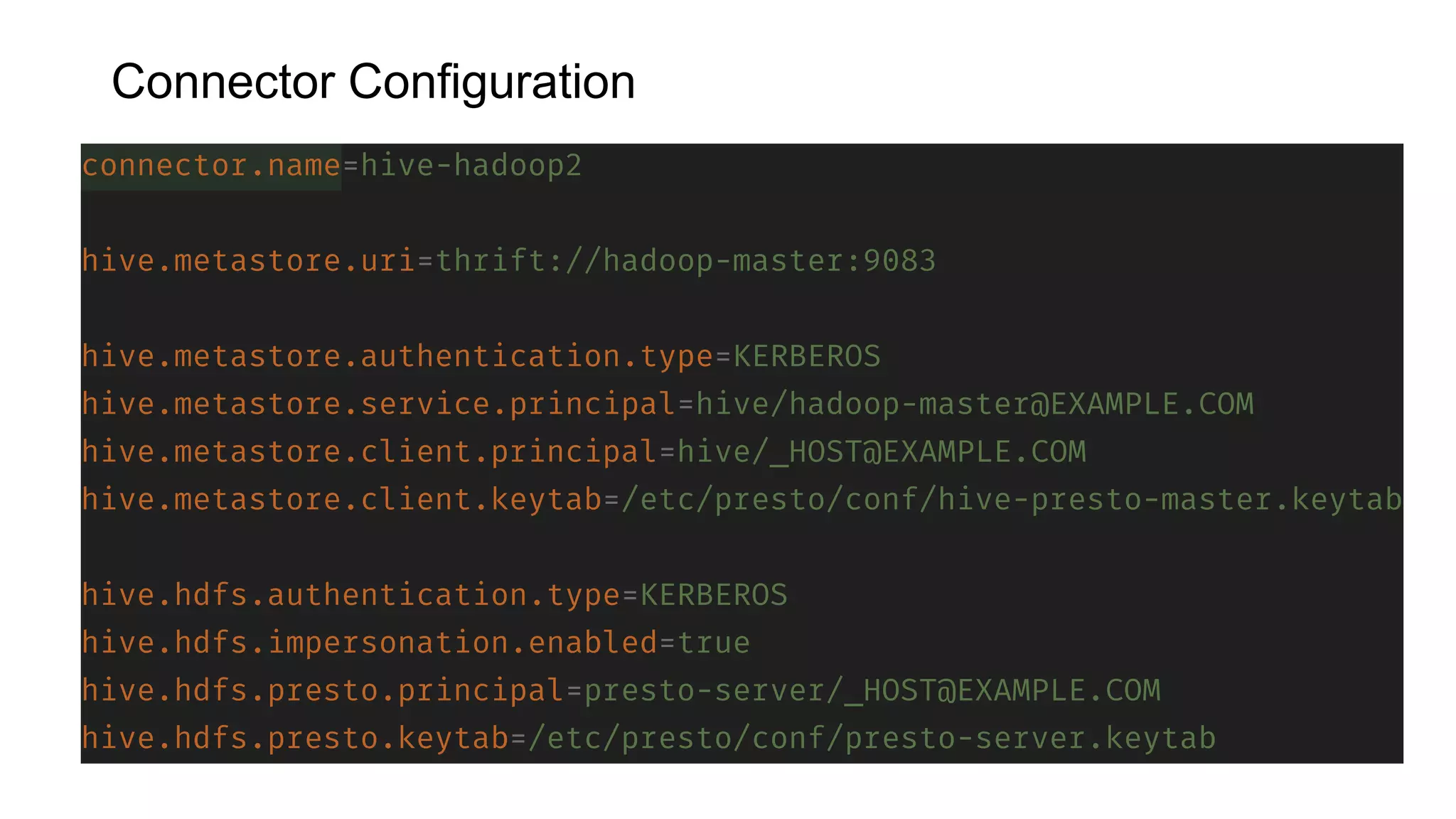
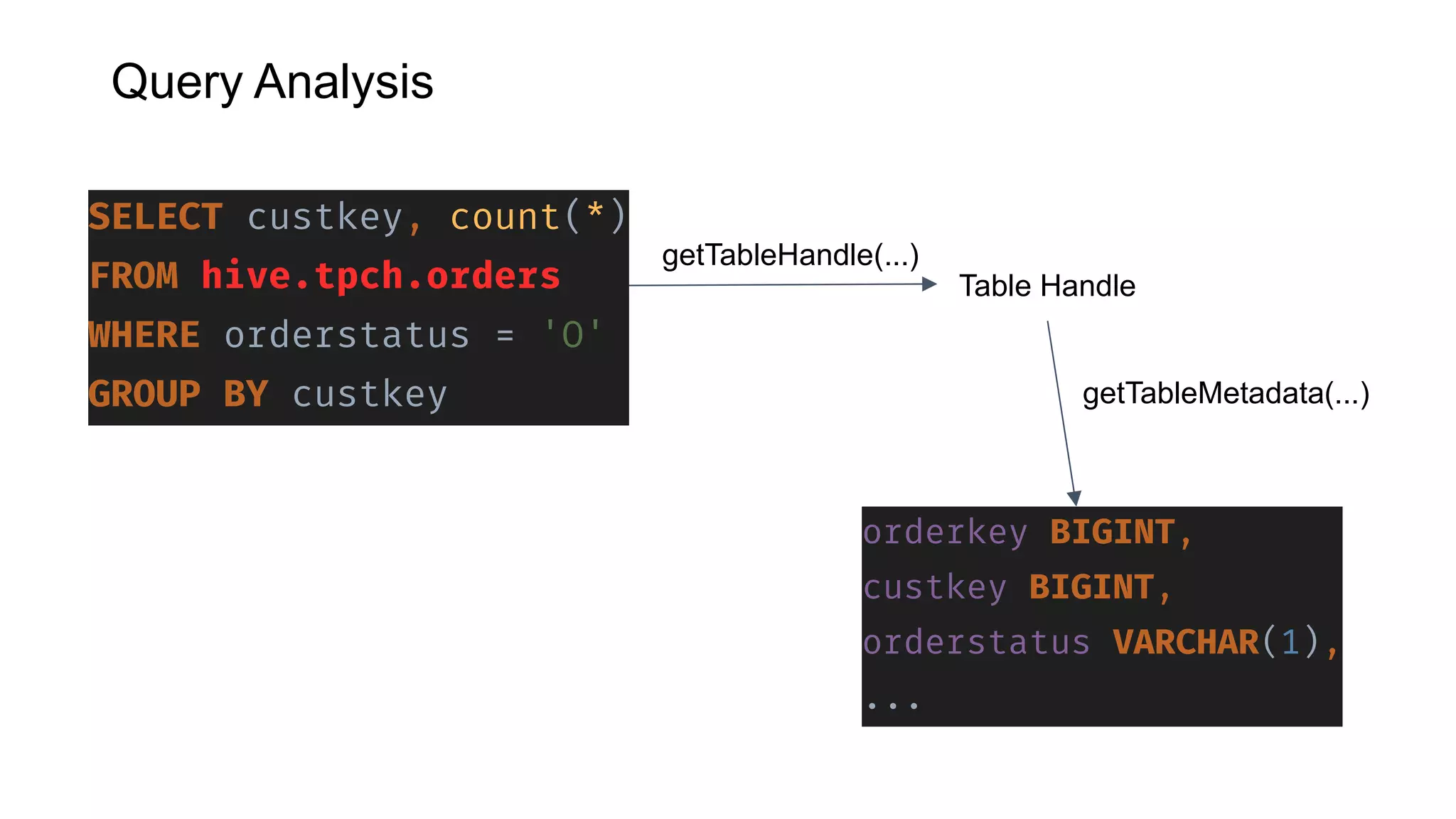
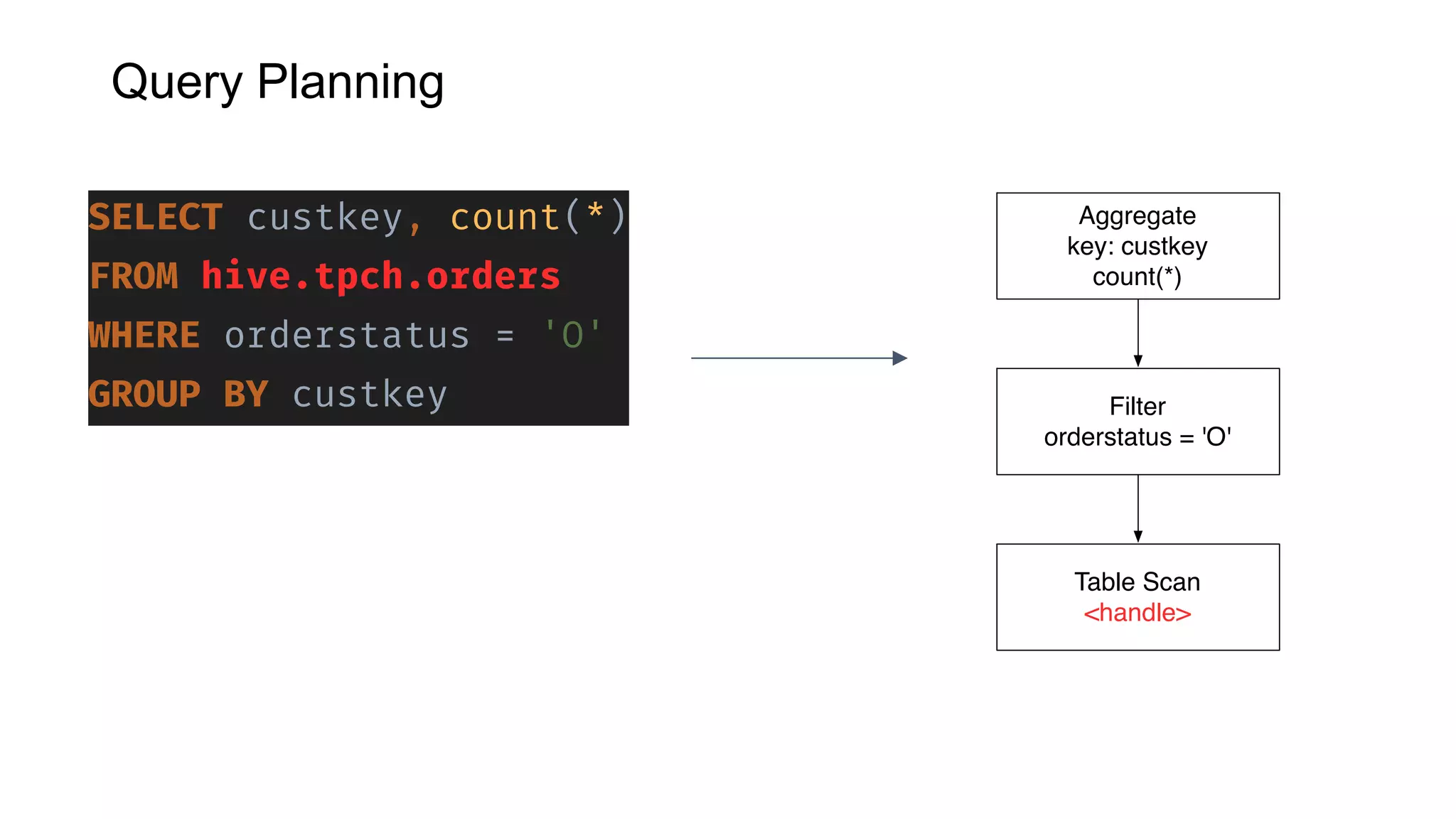
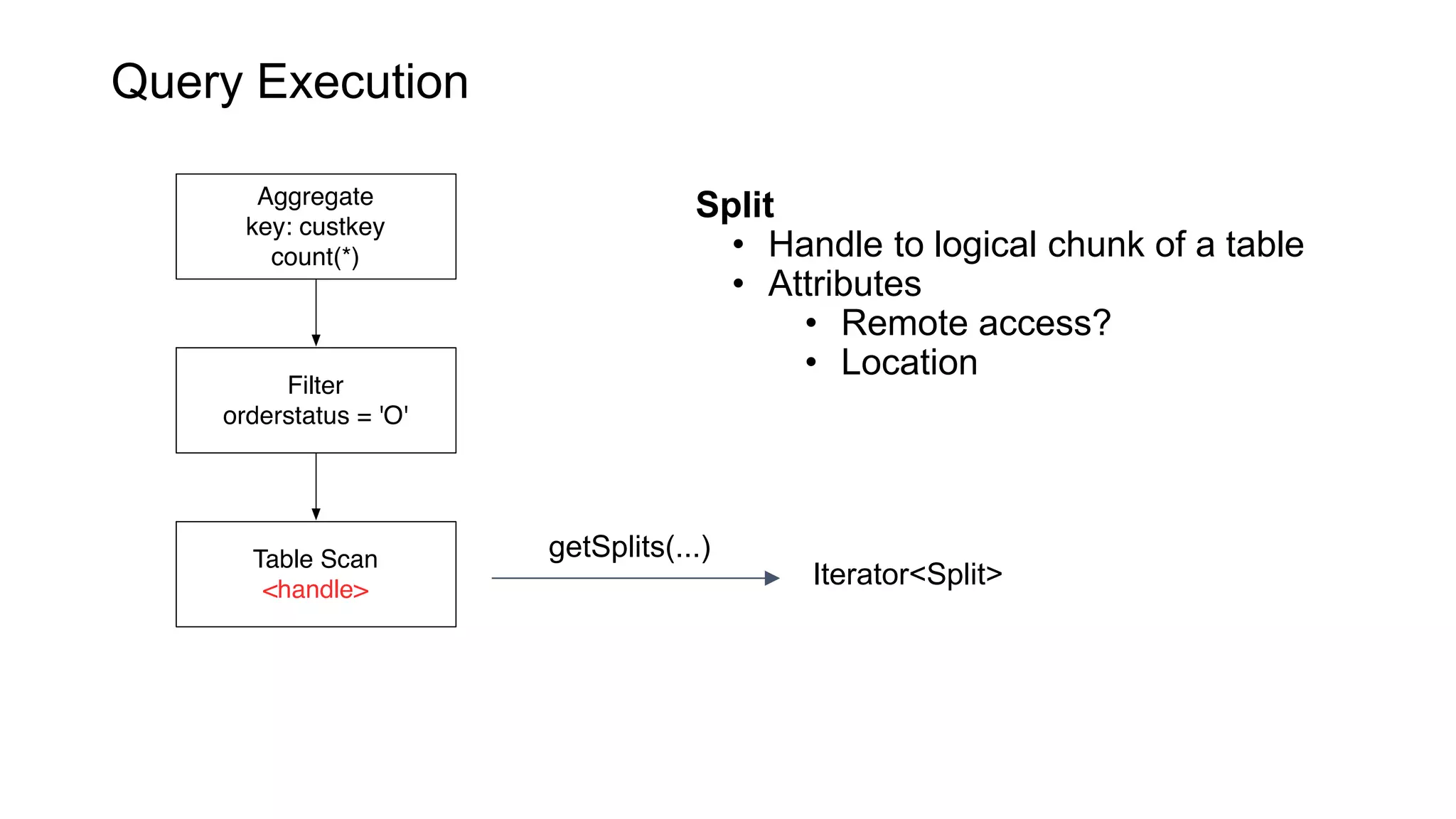
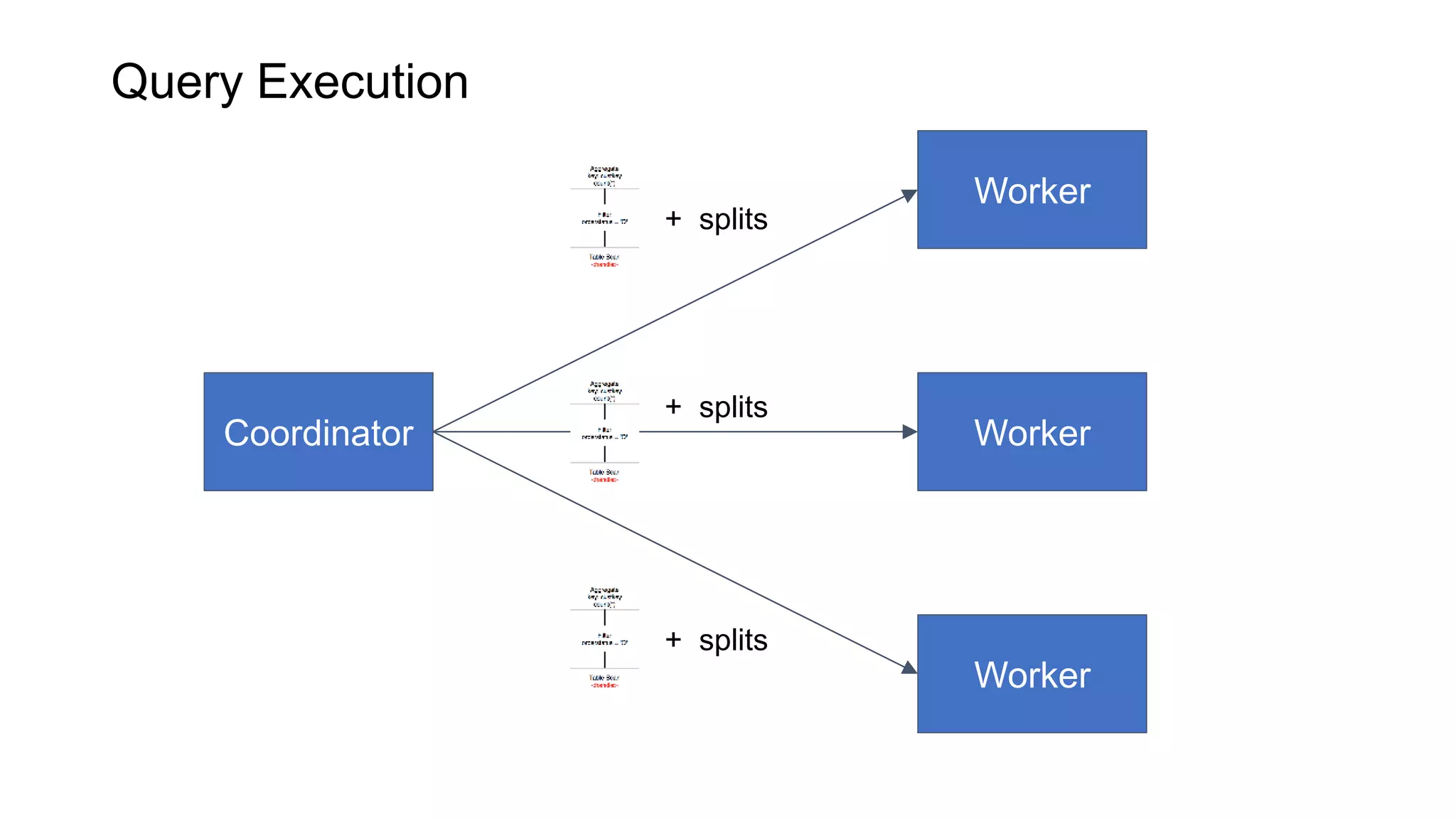
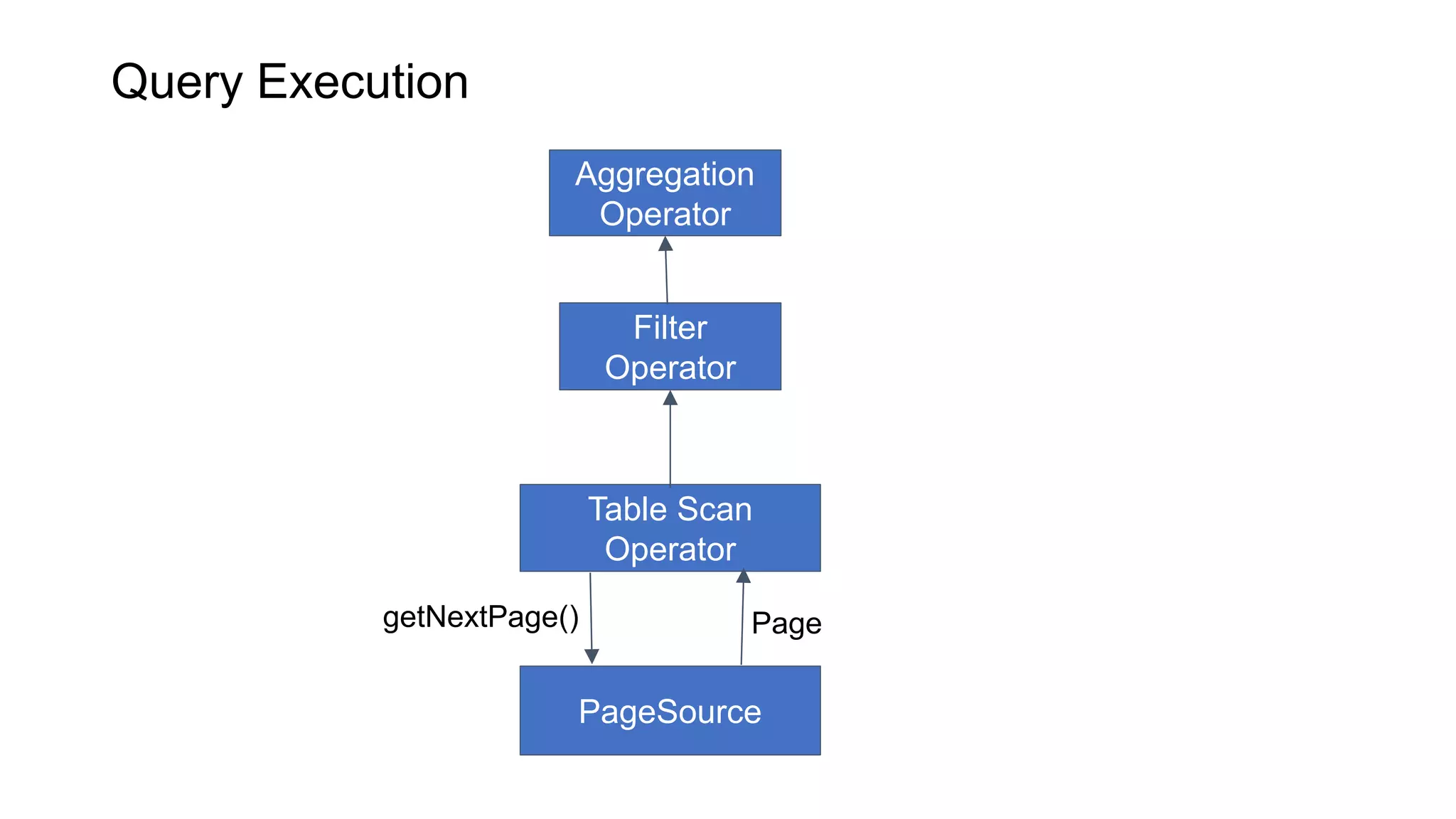


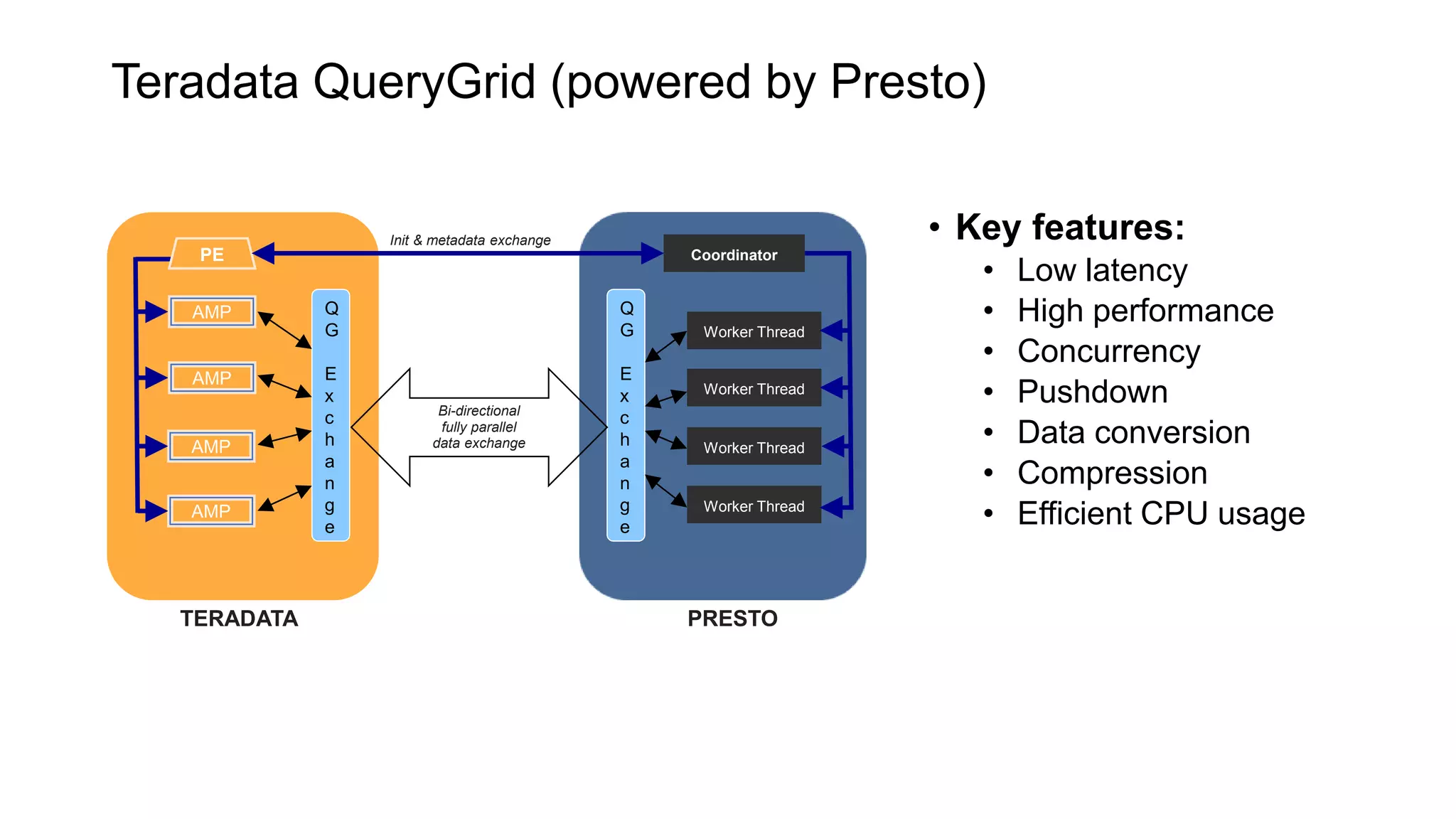


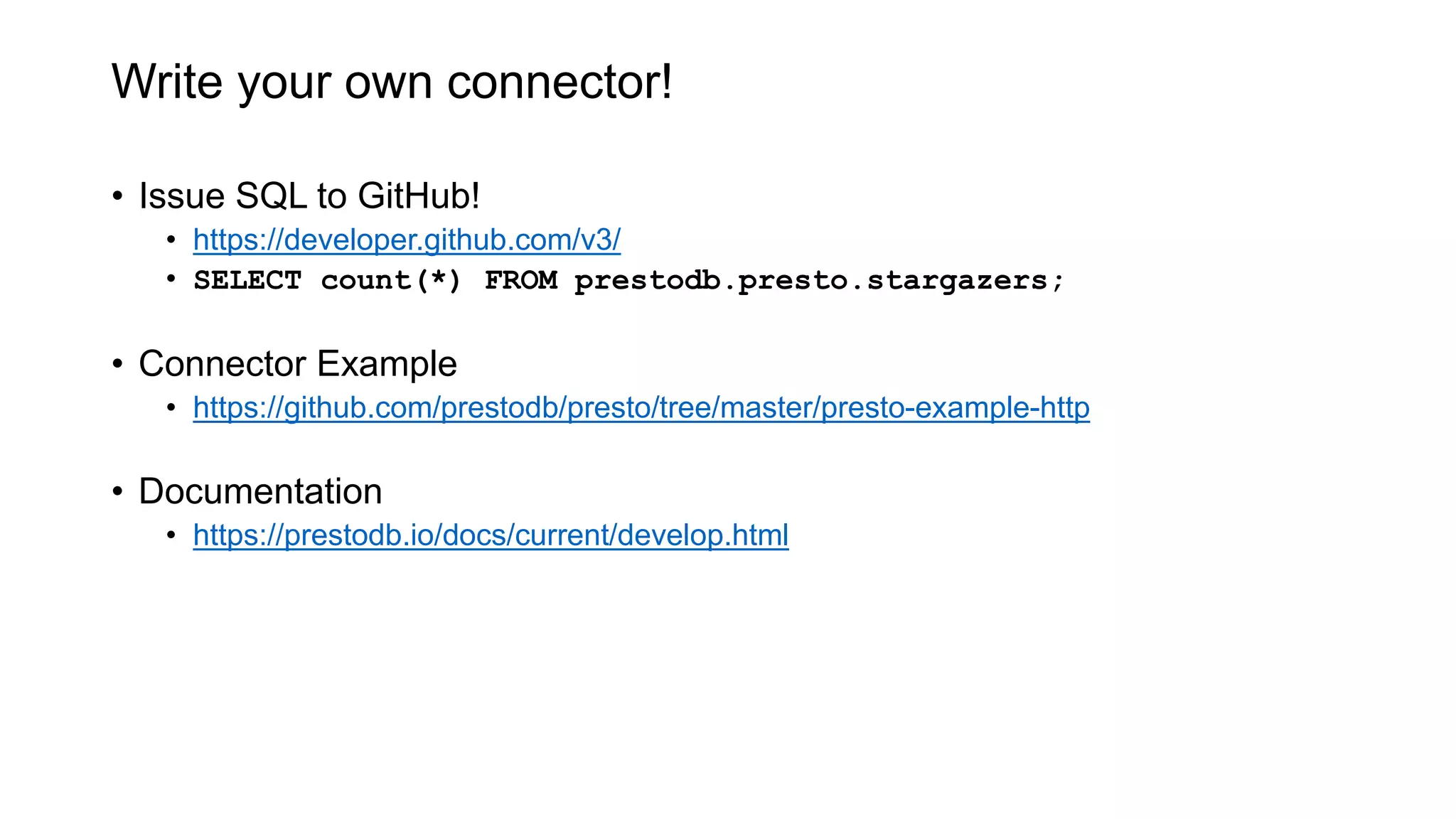



Presto is an open source distributed SQL query engine that allows querying of data across different data sources. It was originally developed by Facebook and is now used by many companies. Presto uses connectors to query various data sources like HDFS, S3, Cassandra, MySQL, etc. through a single SQL interface. Companies like Facebook and Teradata use Presto in production environments to query large datasets across different data platforms.


























![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=640&height=640&fit=bounds)

















































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


















