Download as PDF, PPTX



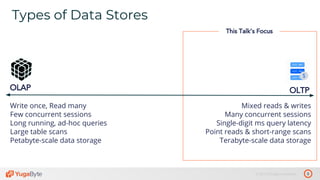
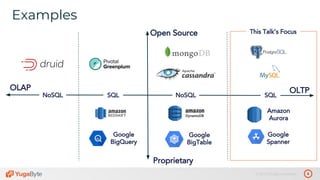



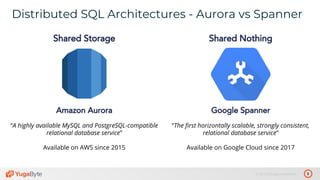


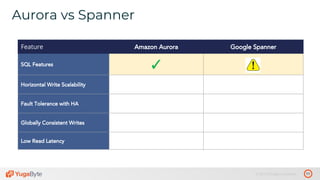

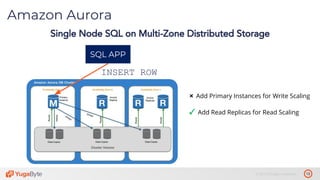
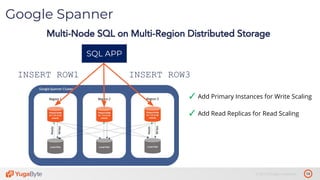
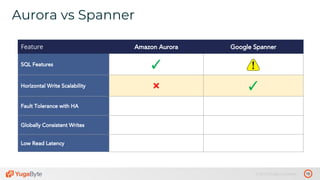

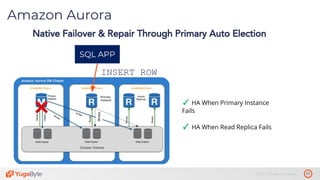
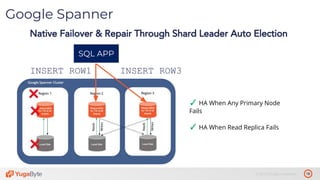
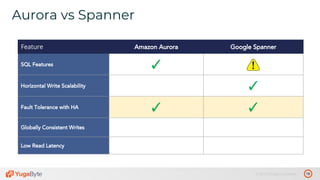

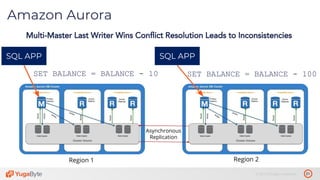
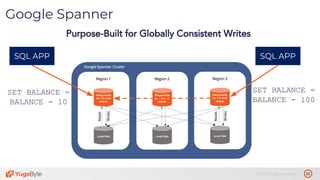
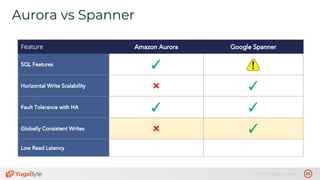

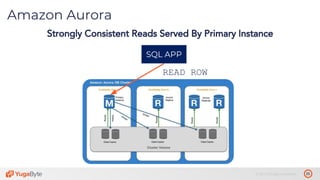
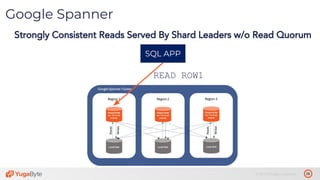
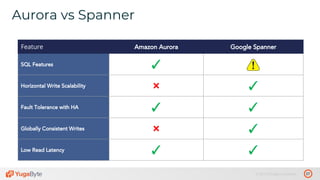






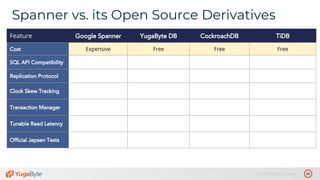

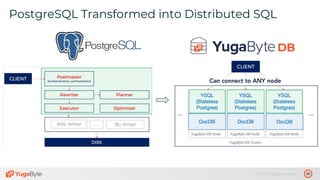

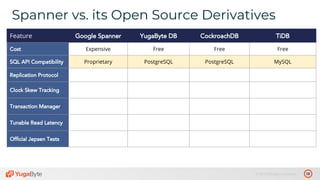

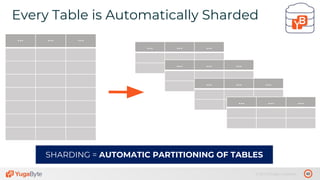
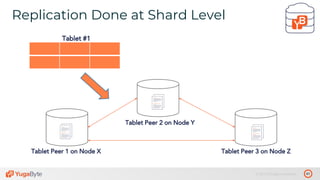
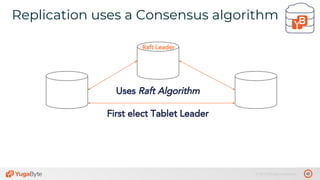
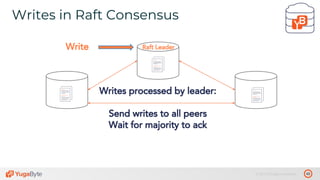
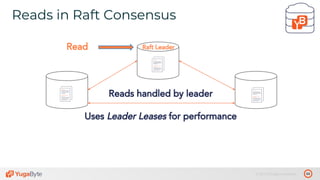
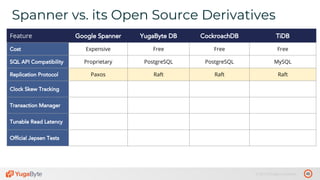


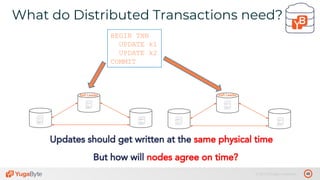


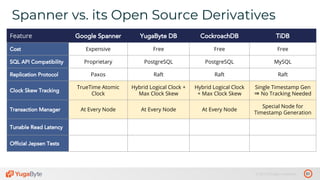





The document discusses the differences between distributed SQL databases, specifically Amazon Aurora and Google Spanner, highlighting features such as SQL support, horizontal scalability, fault tolerance, and low read latency. It compares the architectures and functionalities of these databases while also mentioning open-source derivatives inspired by Spanner. The presentation emphasizes the advantages of distributed SQL systems in terms of scalability and consistency for modern applications.

















































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)

















