Download as PDF, PPTX


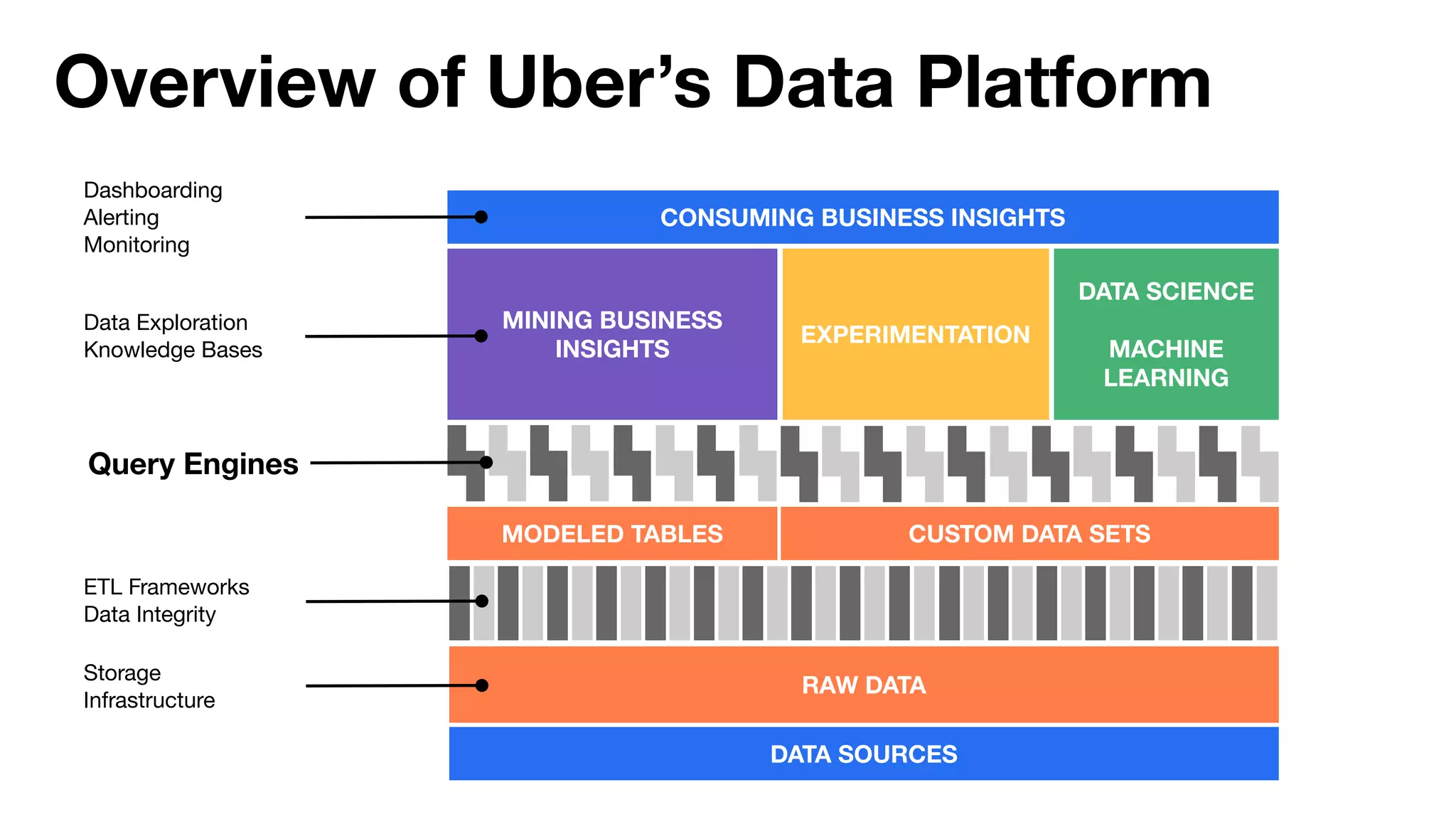
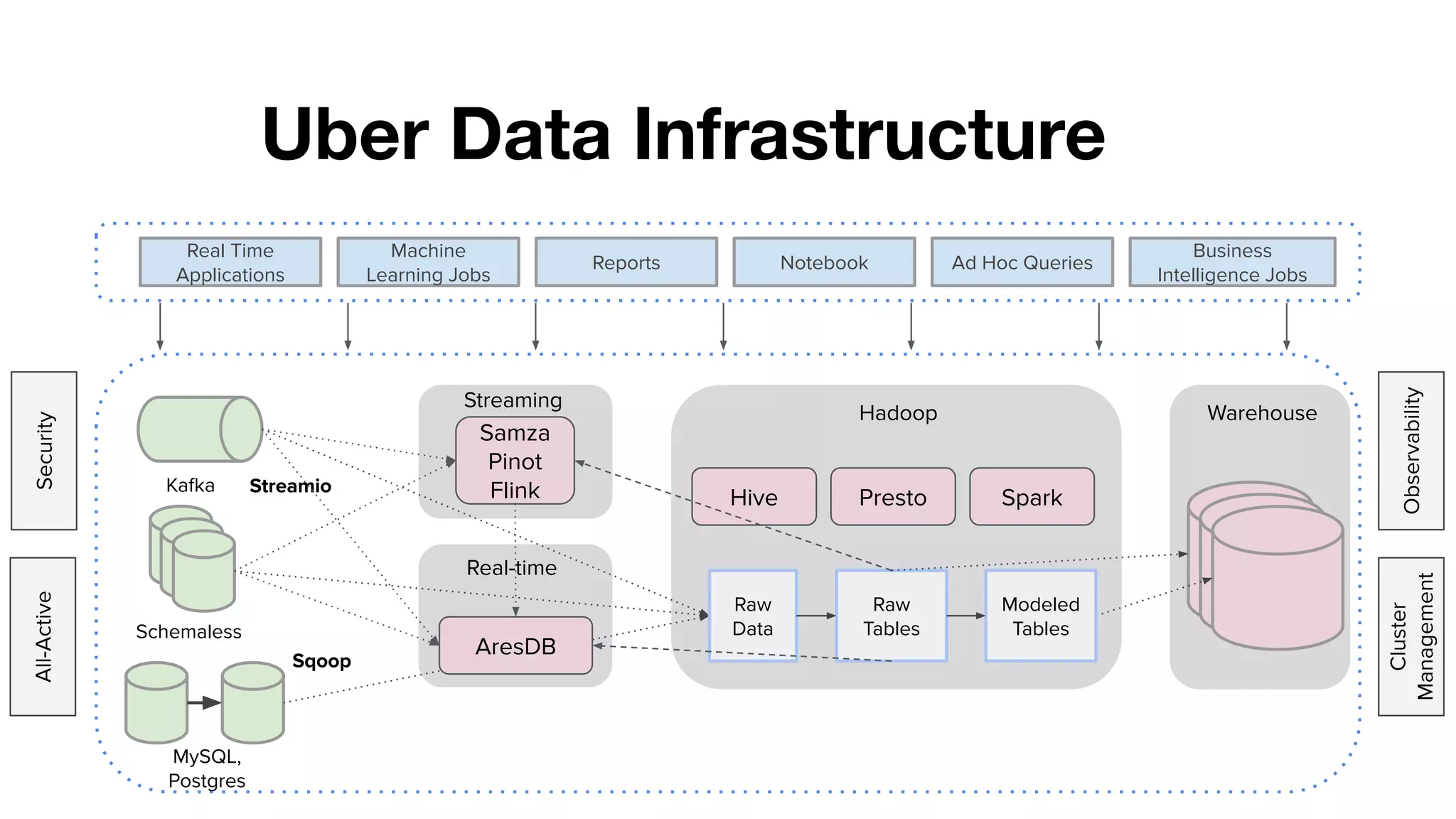

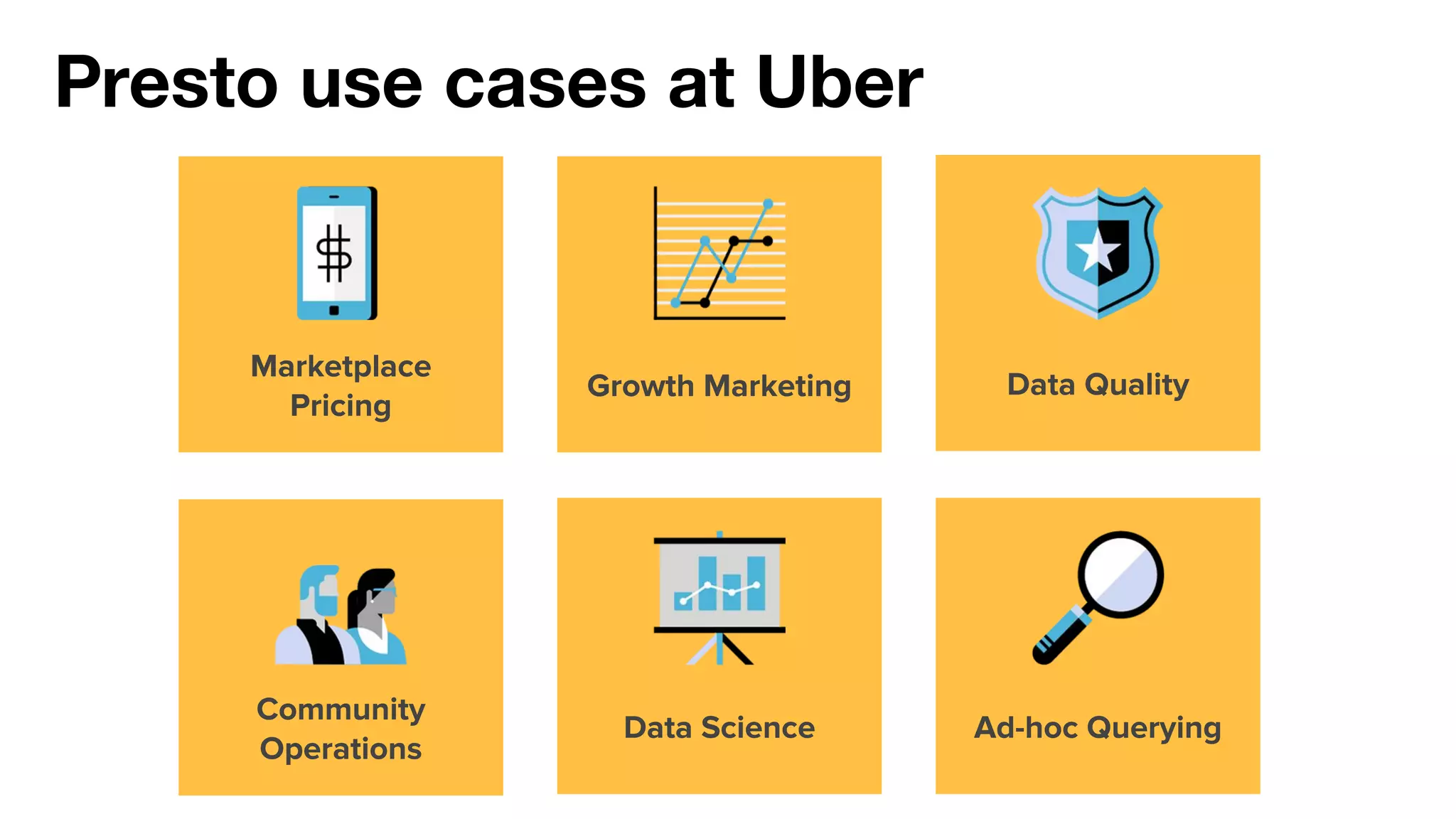





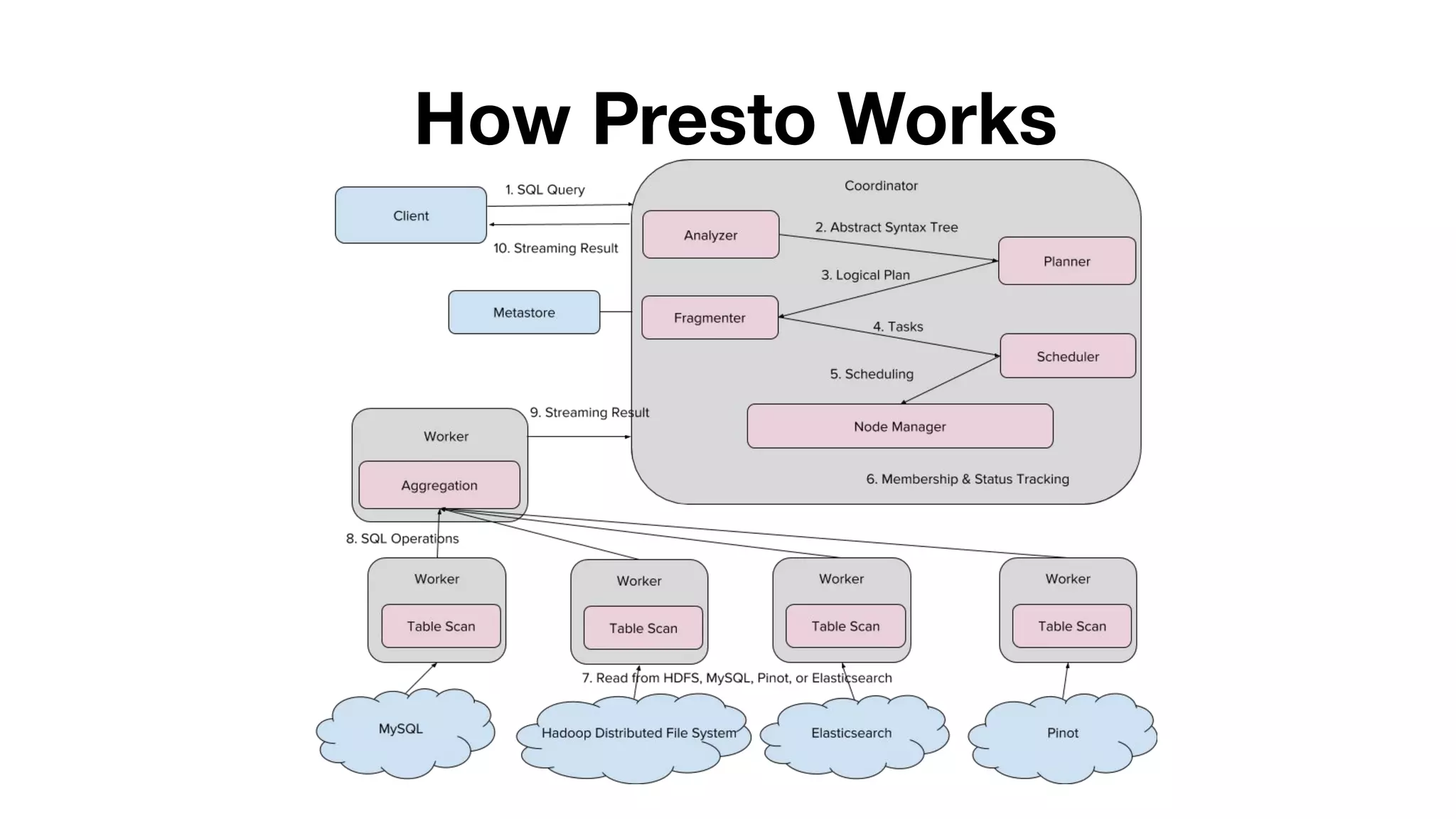






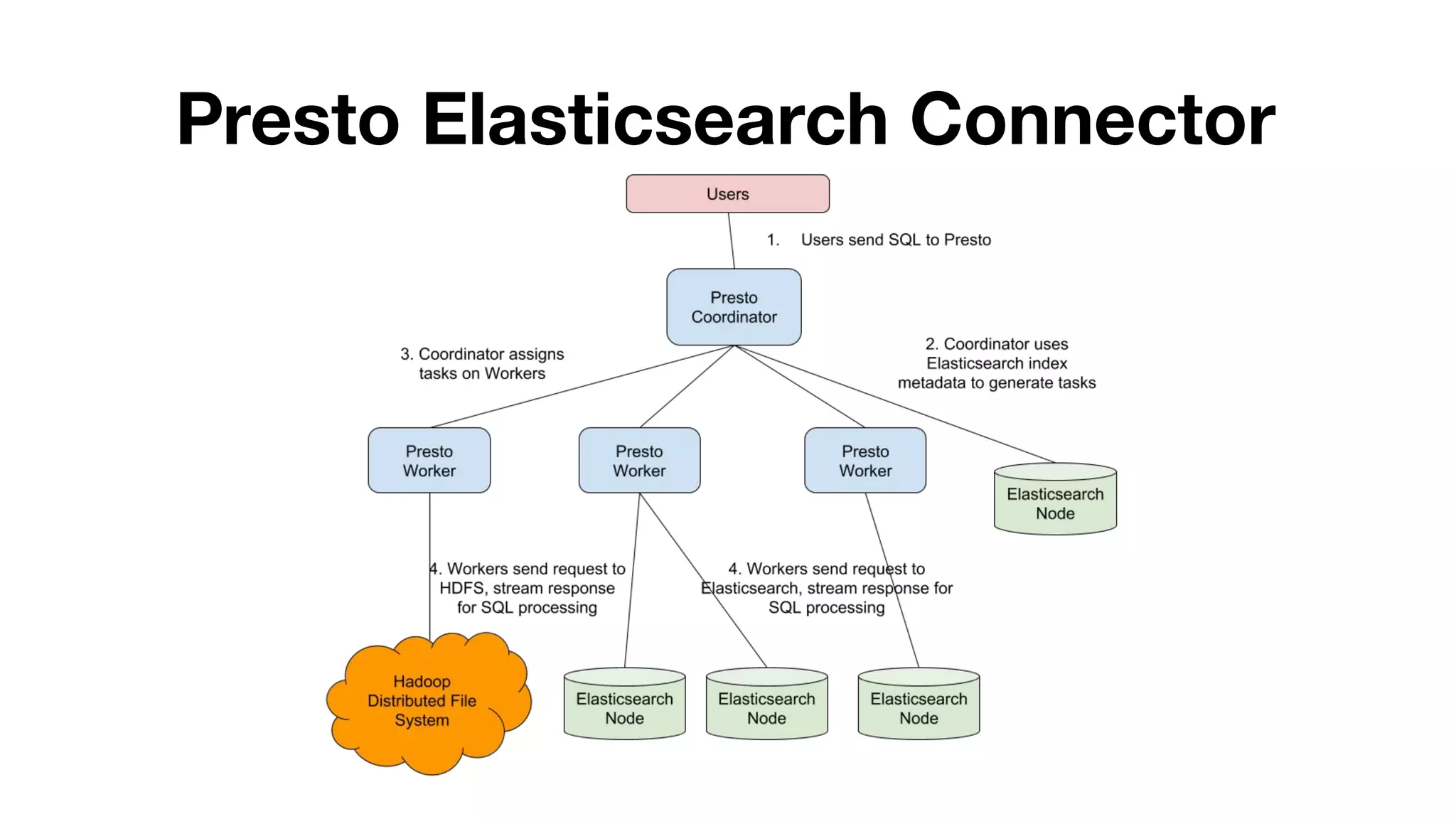

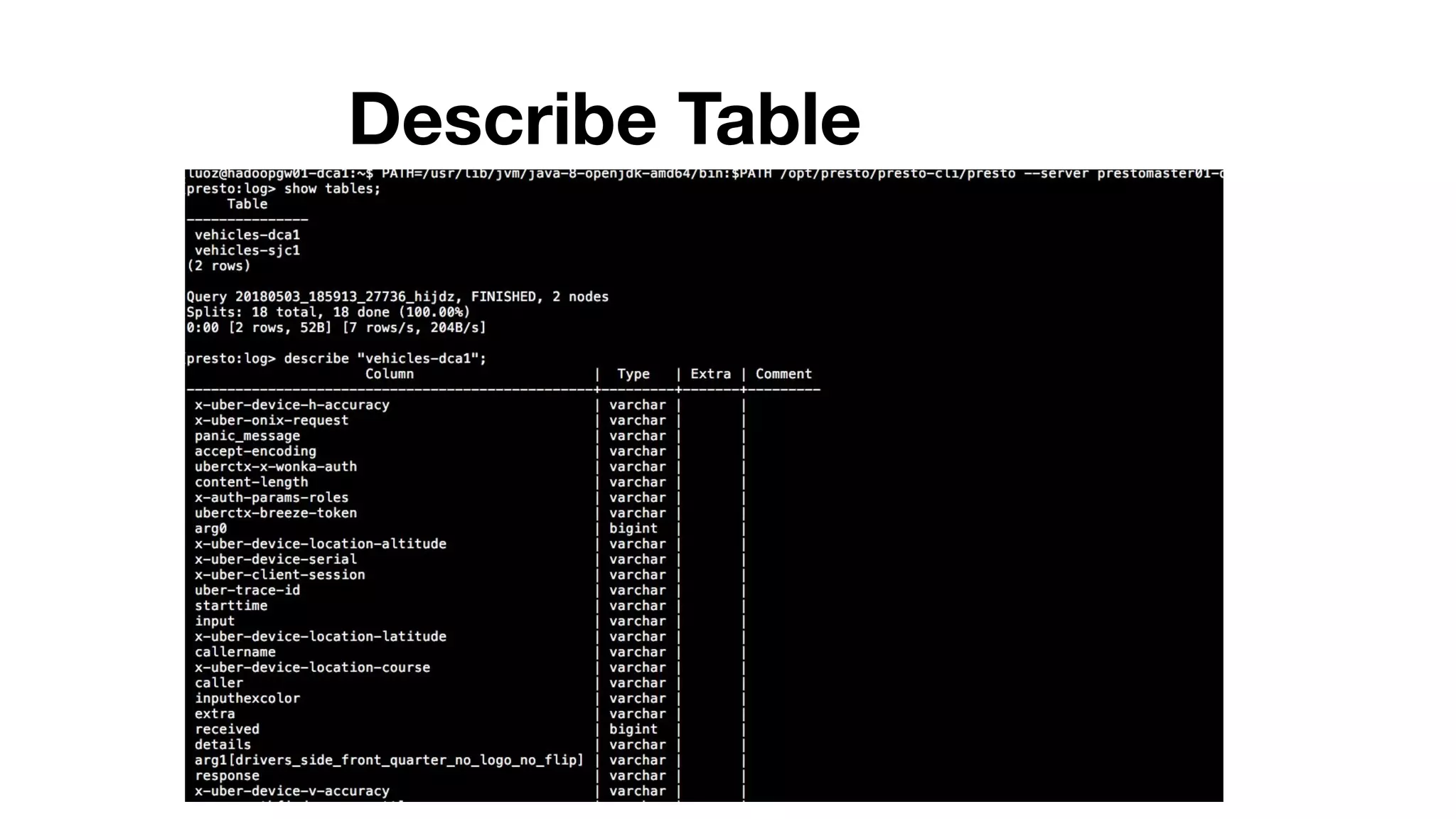
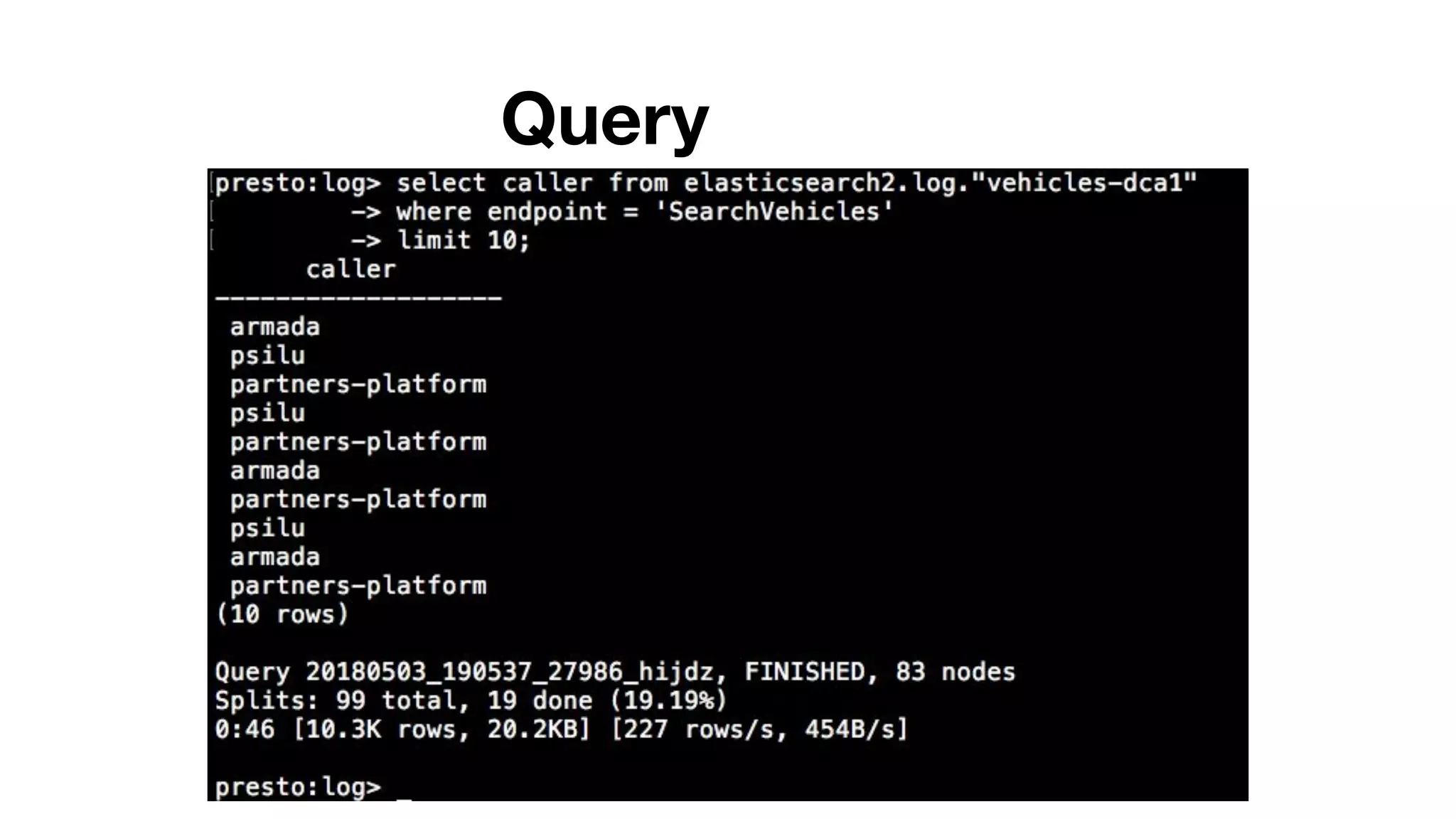



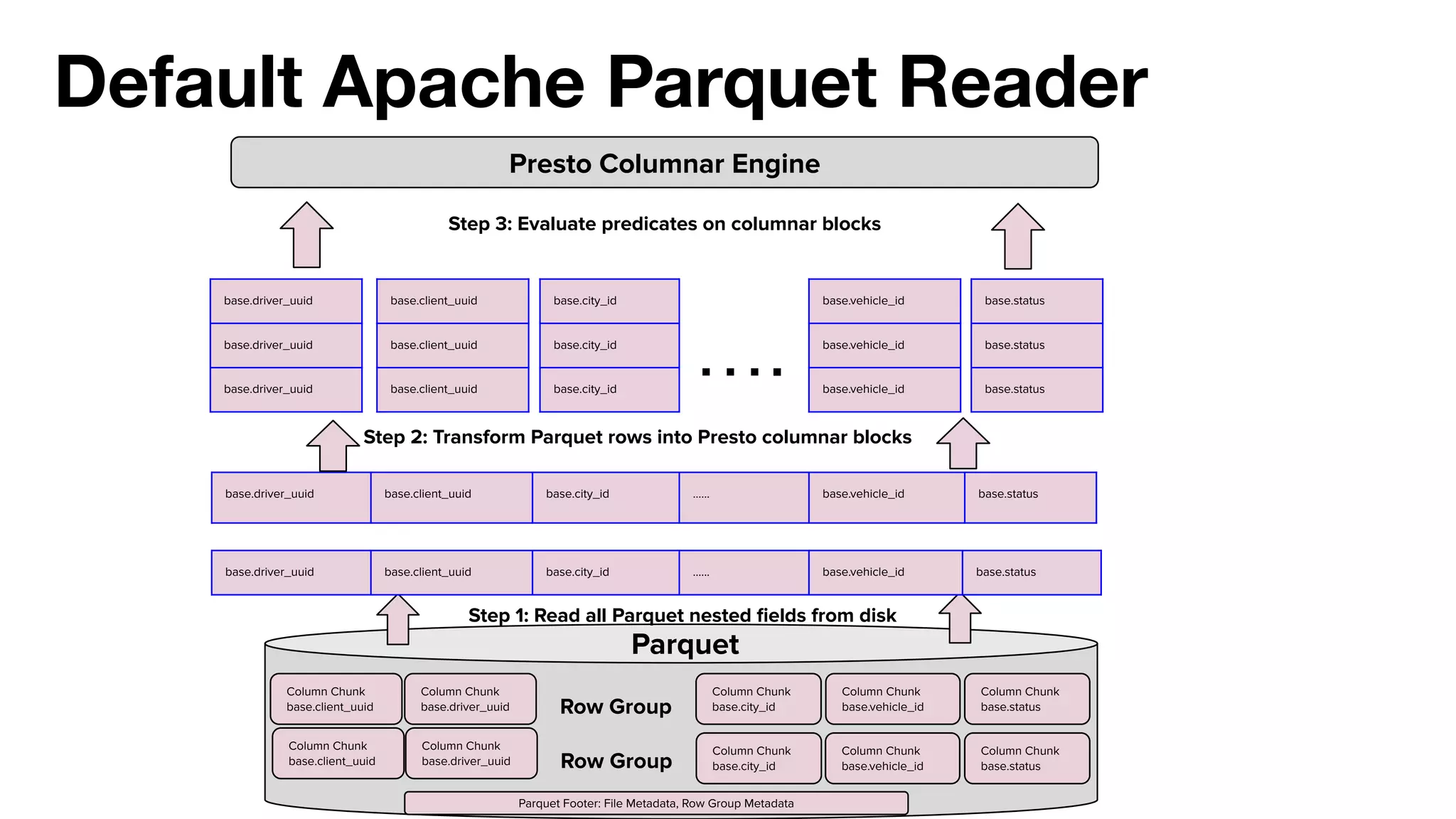
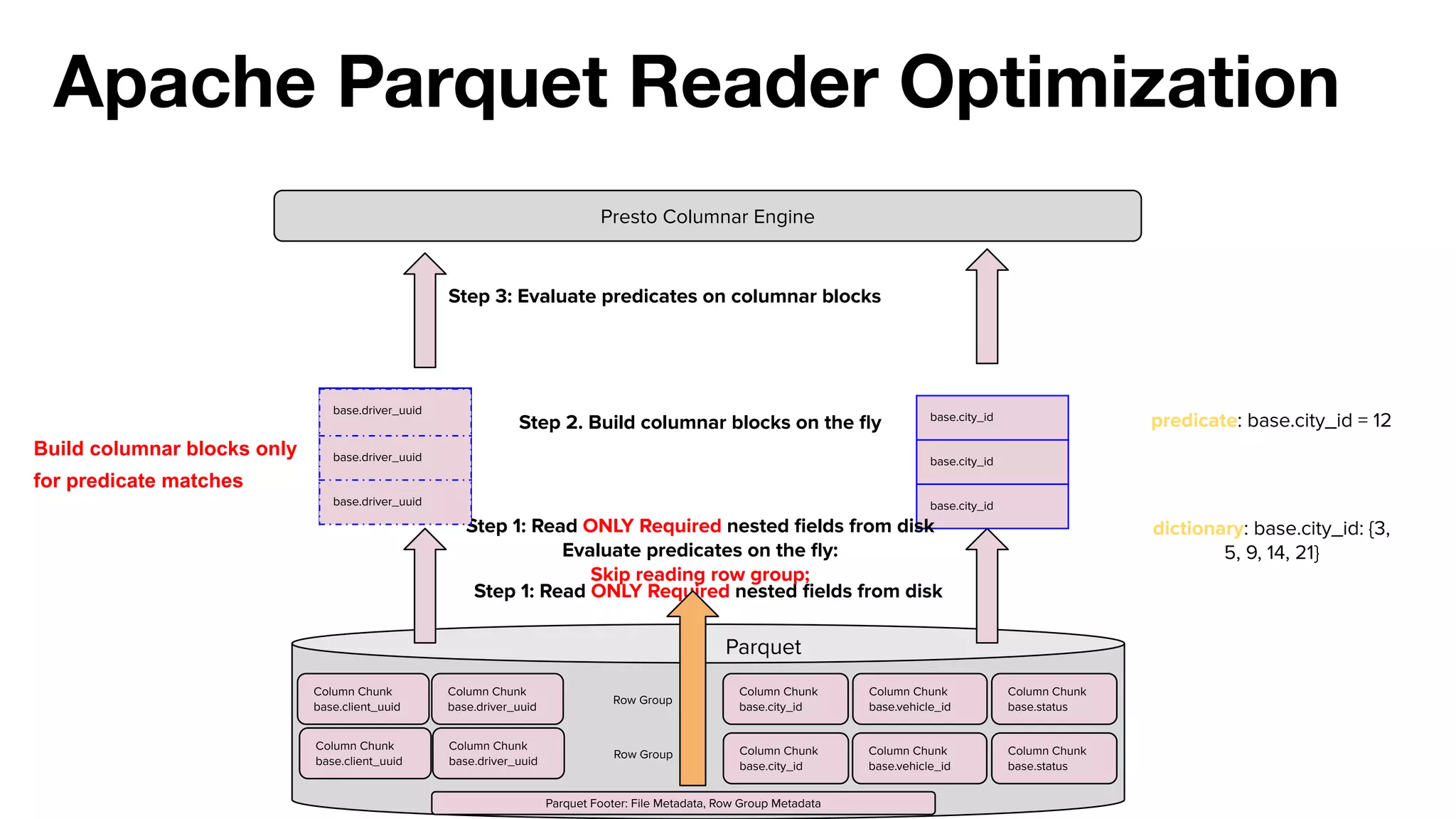
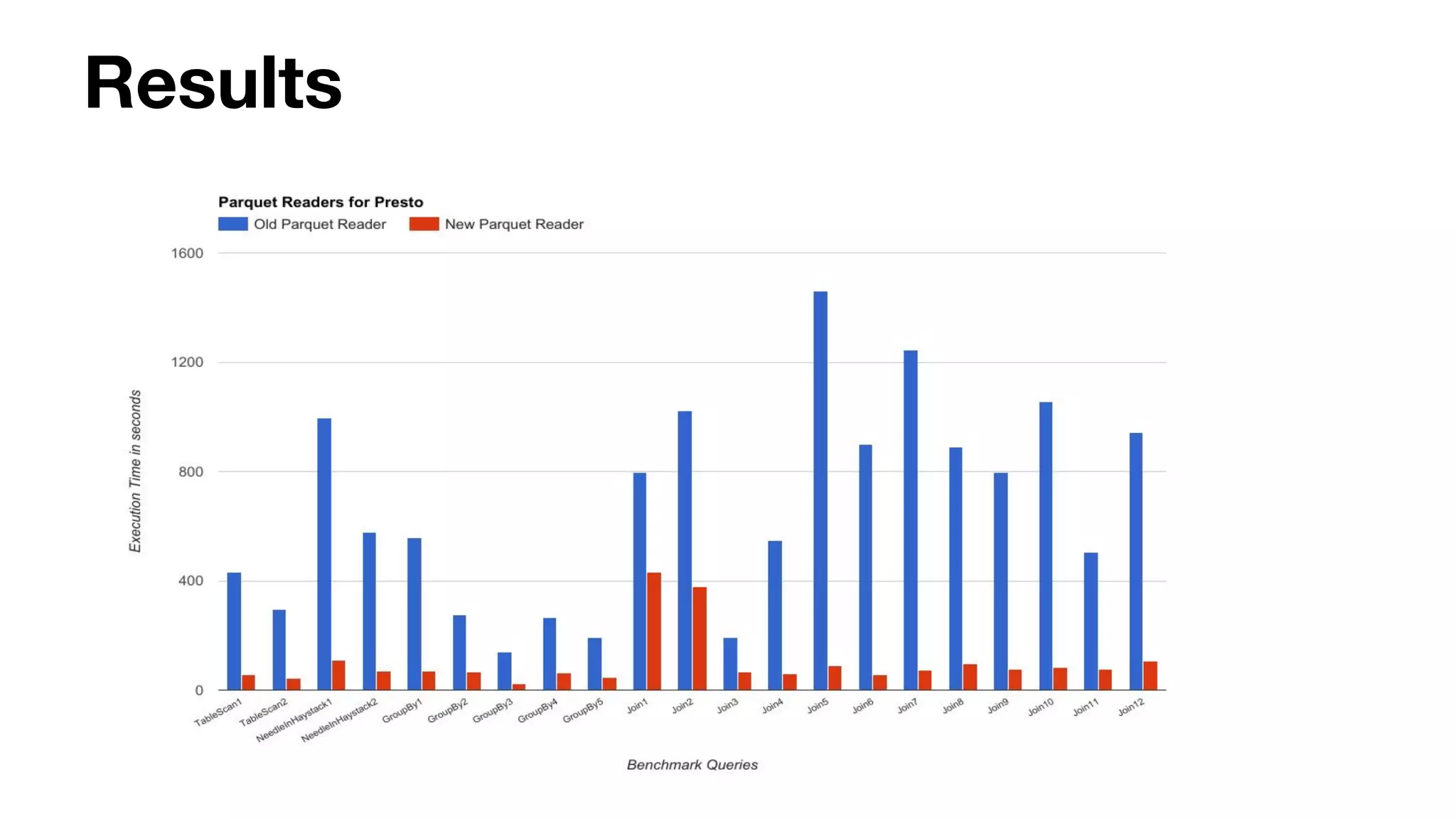

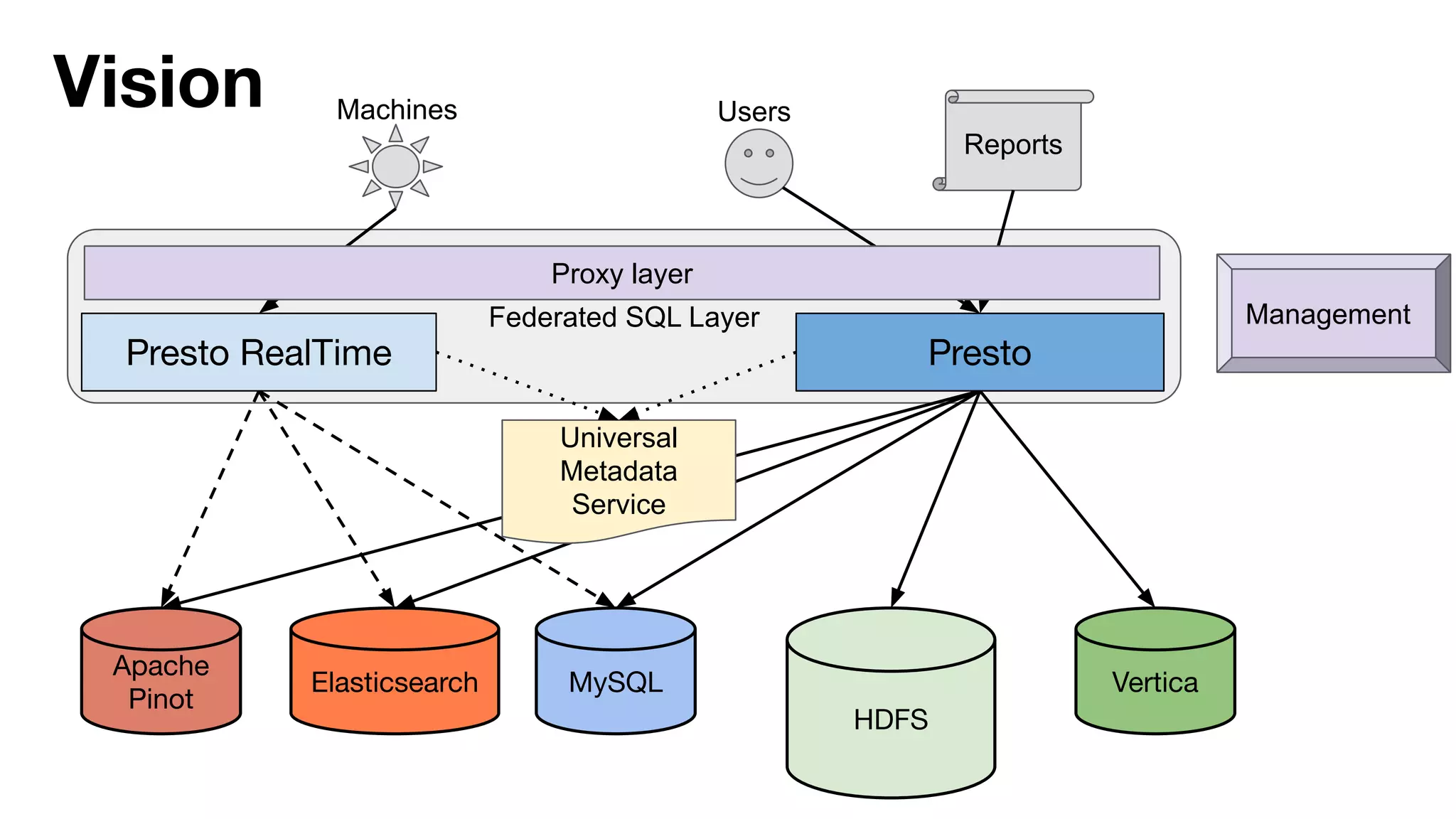



This document summarizes Uber's use of Presto, an open source distributed SQL query engine, for real-time analytics and business intelligence. Presto allows Uber to query petabytes of data across different data sources like HDFS, Elasticsearch, Pinot and databases in seconds. Uber has optimized Presto for its scale with contributions like geospatial support, security features and connectors. Presto is critical for Uber's data scientists, analysts and operations to power applications, machine learning and business decisions.
![[236] 카카오의데이터파이프라인 윤도영](https://cdn.slidesharecdn.com/ss_thumbnails/236-161025031702-thumbnail.jpg?width=640&height=640&fit=bounds)

![[KAIST 채용설명회] 데이터 엔지니어는 무슨 일을 하나요?](https://cdn.slidesharecdn.com/ss_thumbnails/temp-180502031907-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-1-180430181759-thumbnail.jpg?width=640&height=640&fit=bounds)

![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유 (2부)](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-2-180430180517-thumbnail.jpg?width=640&height=640&fit=bounds)



![[NDC16] (애드브릭스) 라이브마이그레이션 분투기 - 달리는 분석 툴의 바퀴를 갈아 끼워보자!](https://cdn.slidesharecdn.com/ss_thumbnails/ndc16-160427135233-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Play.node] node.js 를 사용한 대규모 글로벌(+중국) 서비스](https://cdn.slidesharecdn.com/ss_thumbnails/playnode20161123slideshare-161125153022-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NDC 2018] Spark, Flintrock, Airflow 로 구현하는 탄력적이고 유연한 데이터 분산처리 자동화 인프라 구축](https://cdn.slidesharecdn.com/ss_thumbnails/jparktemp-180424105624-thumbnail.jpg?width=640&height=640&fit=bounds)

![Naver속도의, 속도에 의한, 속도를 위한 몽고DB (네이버 컨텐츠검색과 몽고DB) [Naver]](https://cdn.slidesharecdn.com/ss_thumbnails/naver-190916181334-thumbnail.jpg?width=640&height=640&fit=bounds)







































![Number_Guessing_Game_Dsbsbssbzboc[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/numberguessinggamedoc1-251206215042-a076fc05-thumbnail.jpg?width=640&height=640&fit=bounds)







