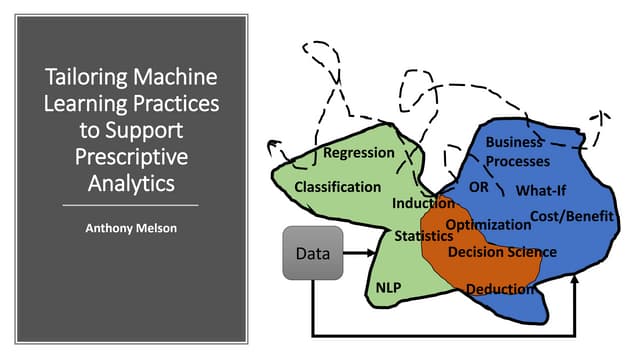
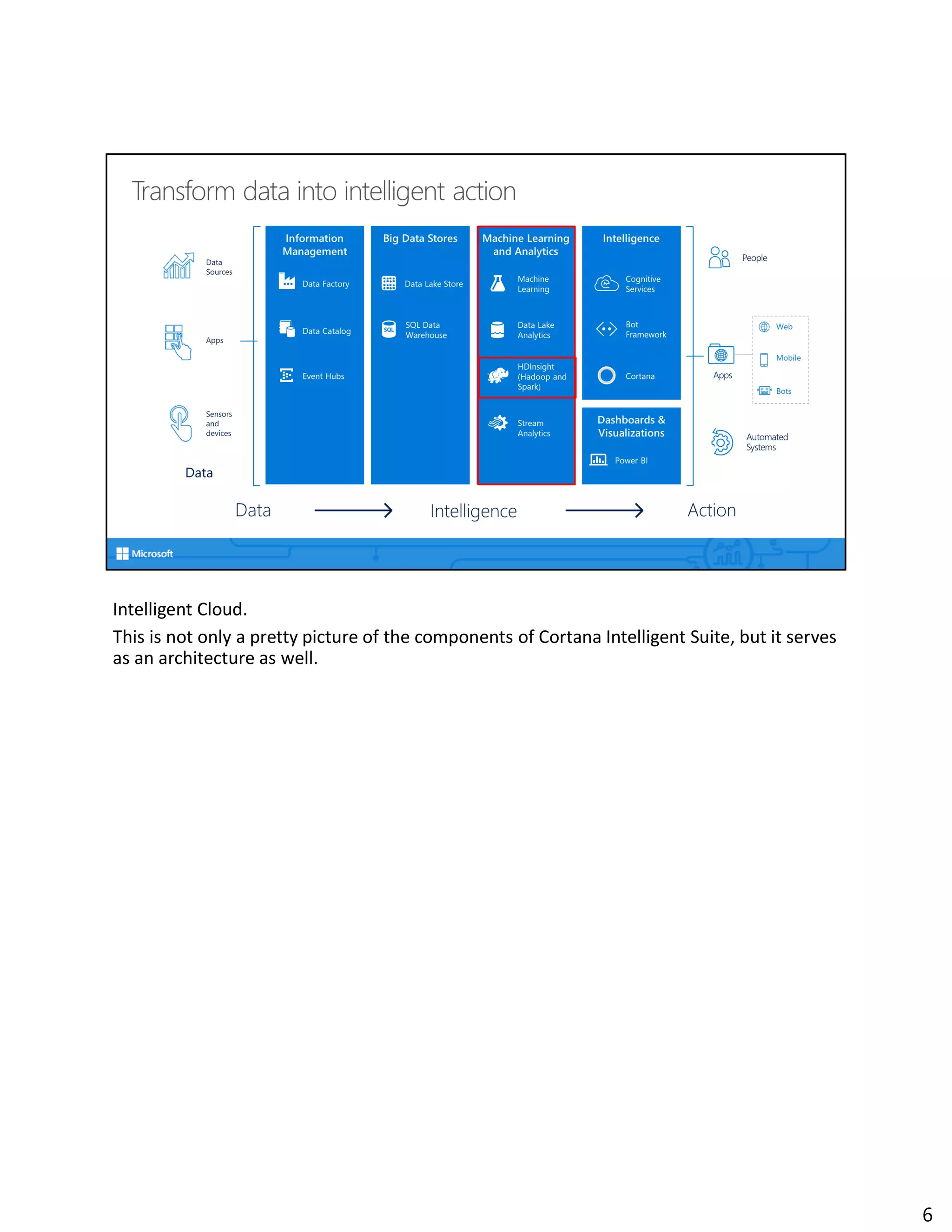
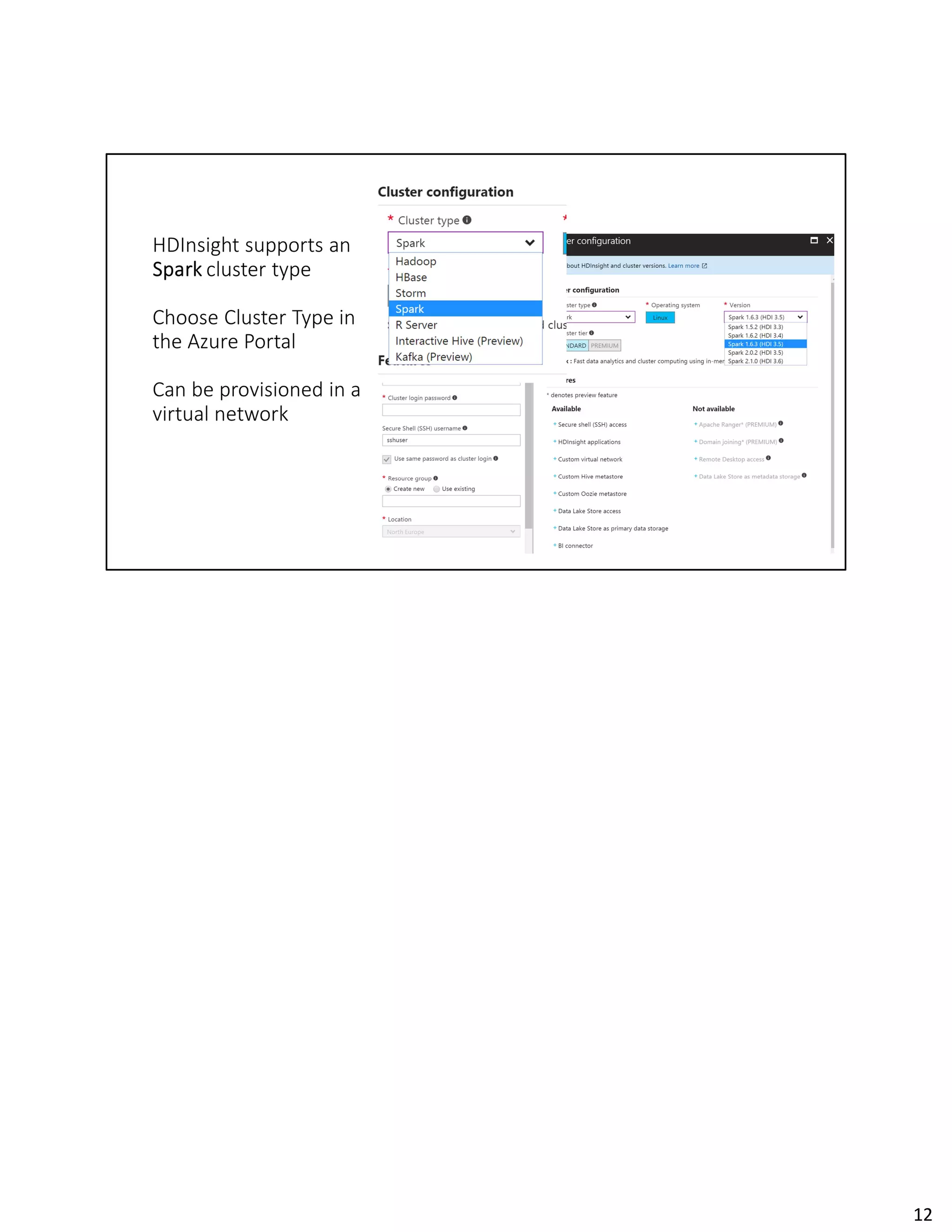
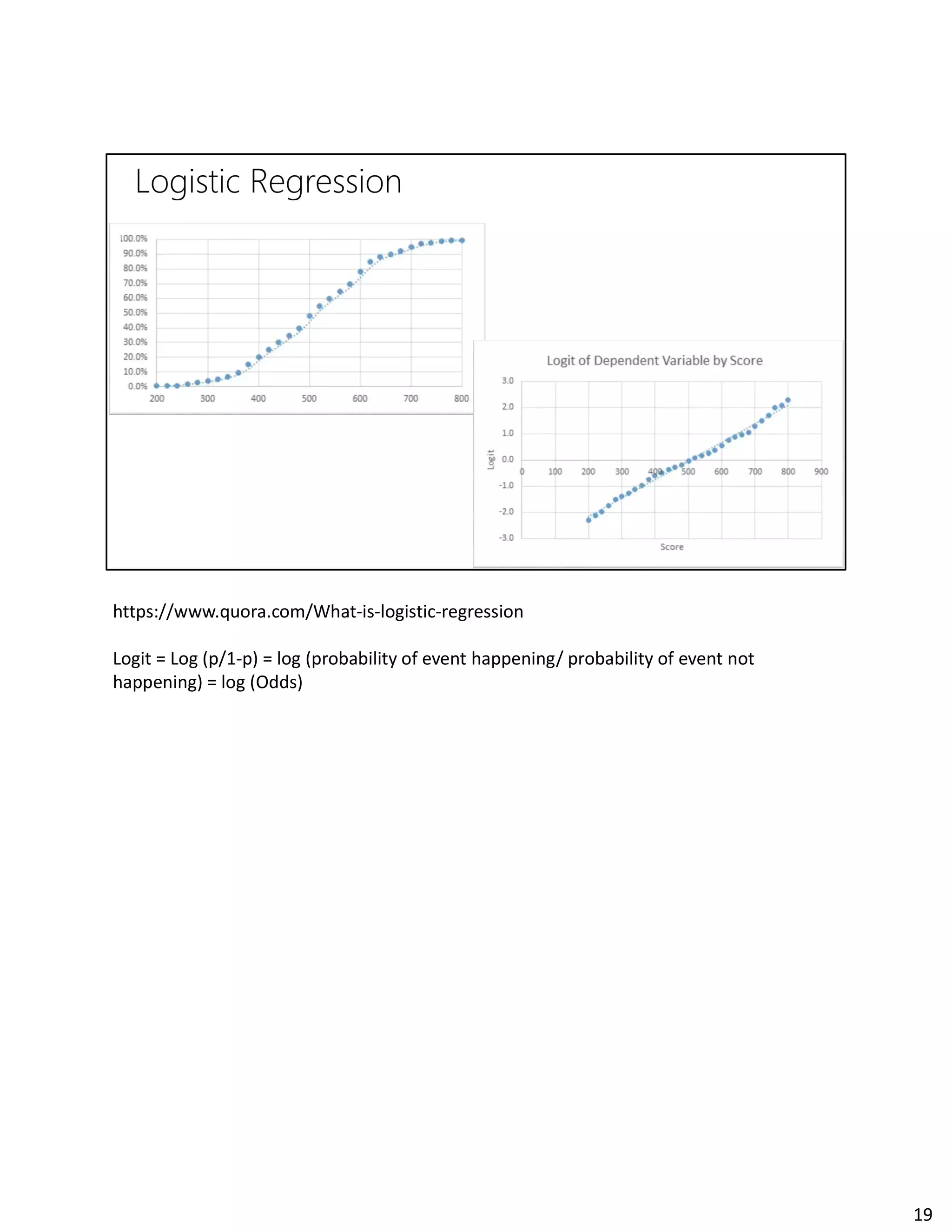
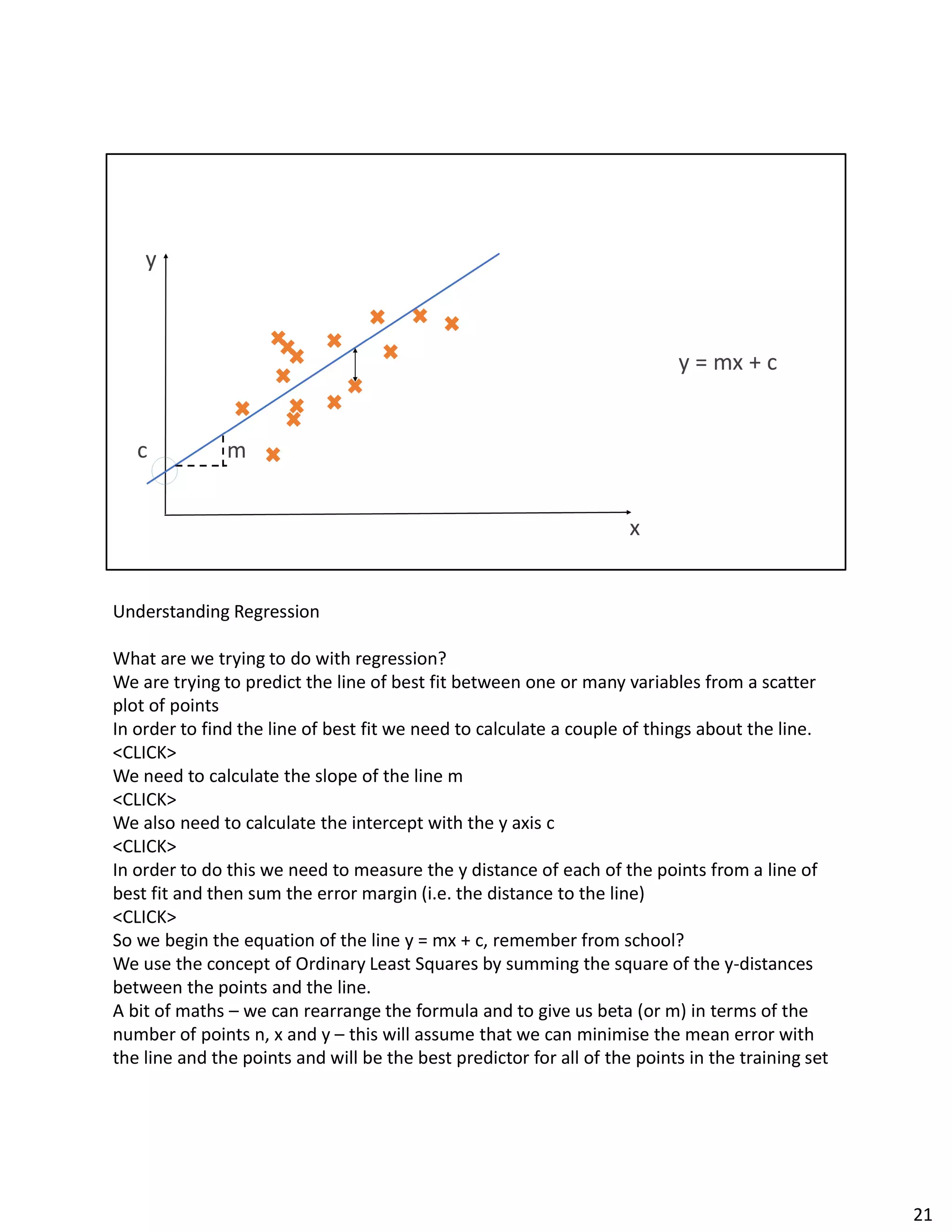
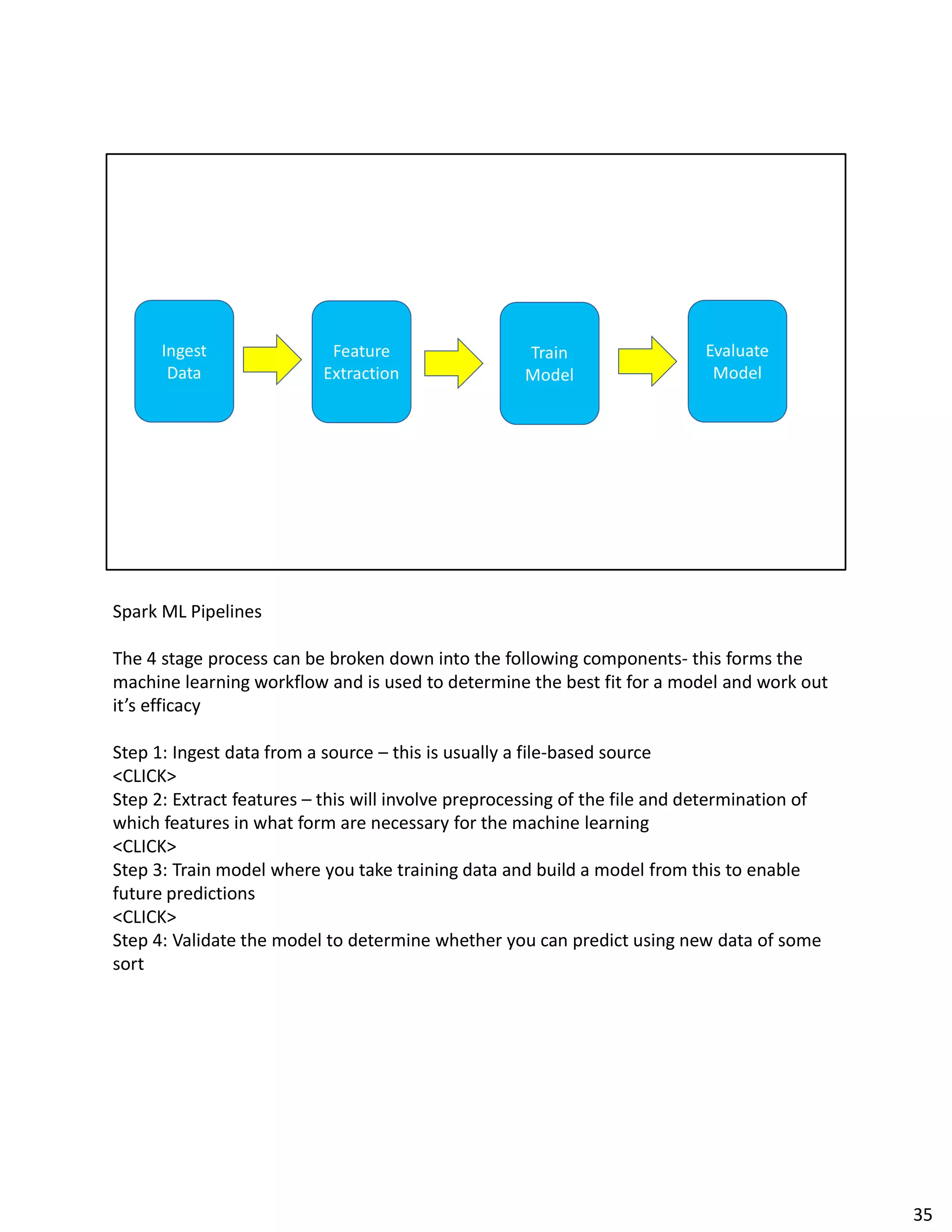
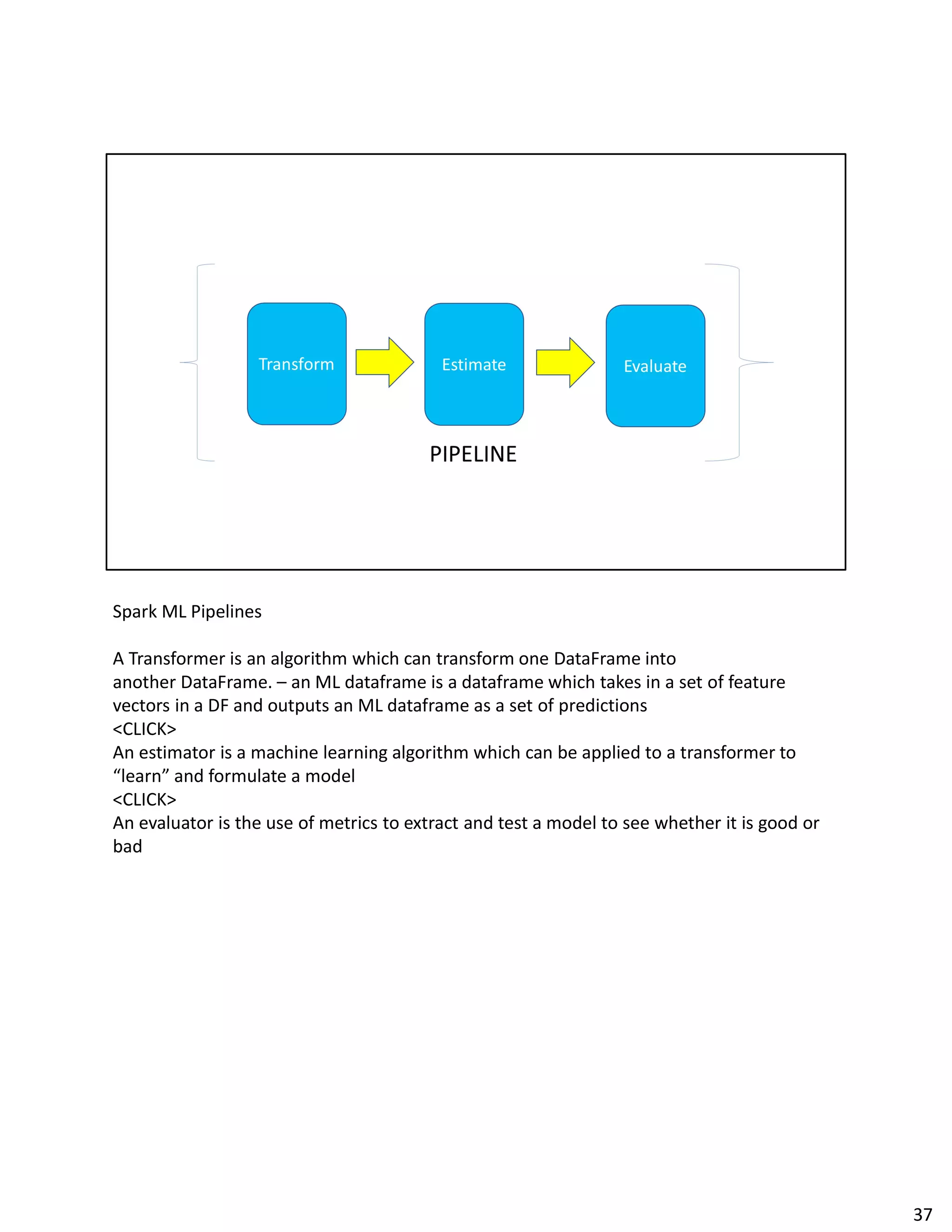
The document discusses Spark streaming and machine learning concepts like logistic regression, linear regression, and clustering algorithms. It provides code examples in Scala and Python showing how to perform binary classification on streaming data using Spark MLlib. Links and documentation are referenced for setting up streaming machine learning pipelines to train models on streaming data in real-time and make predictions.










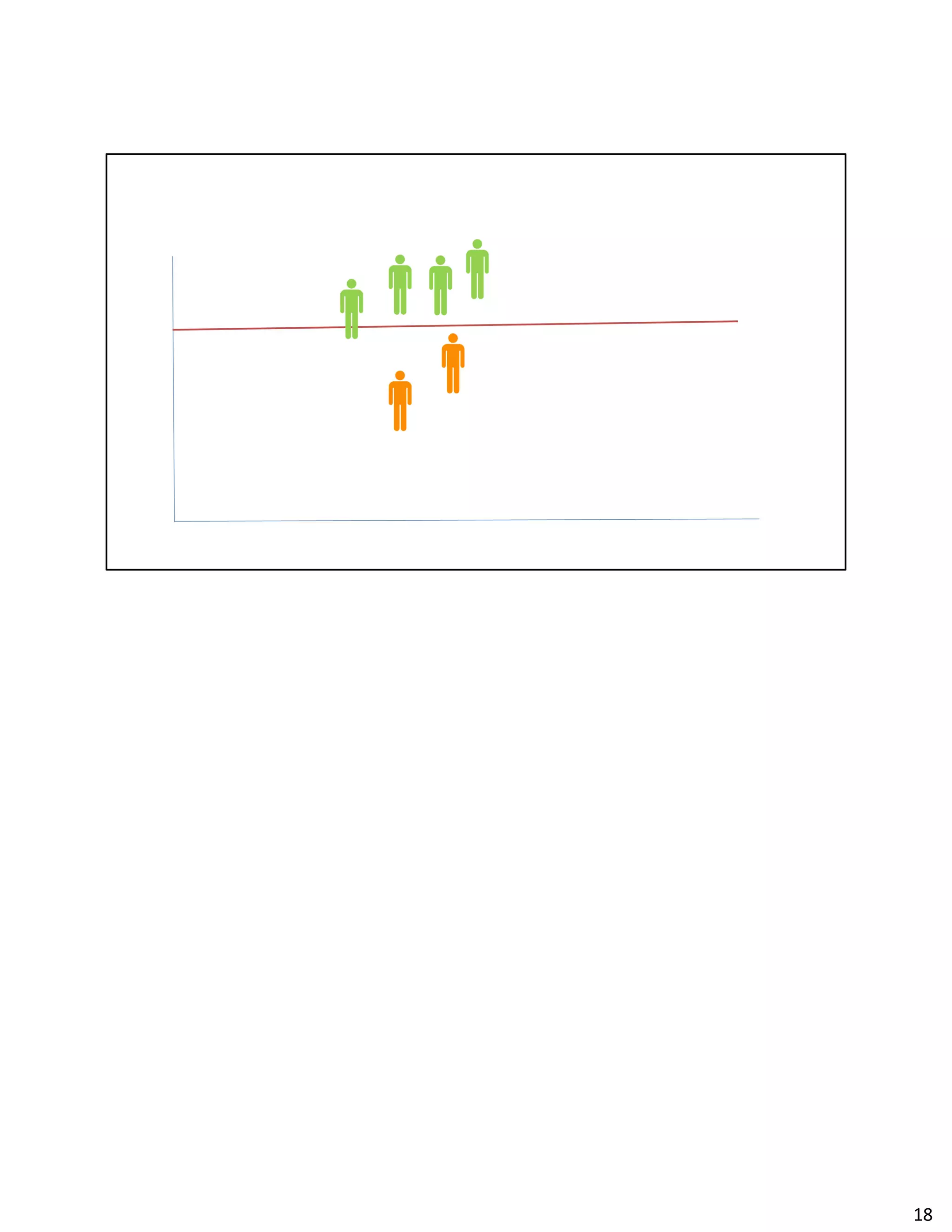






















![An example of Kmeans & streaming.
<CLICK>
We make an input stream of vectors for training, as well as a stream of labelled data points
for testing - this isn't shown in the code segment below. We assume a StreamingContext
ssc has been created already.
<CLICK>
We create a model with random clusters and specify the number of clusters to find where
<CLICK>
Now register the streams for training and testing and start the job, printing the predicted
cluster assignments on new data points as they arrive.
<CLICK>
As you add new text files with data the cluster centers will update. Each training point
should be formatted as [x1, x2, x3], and each test data point should be formatted as (y, [x1,
x2, x3]), where y is some useful label or identifier (e.g. a cluster assignment). Anytime a
text file is placed in training dir the model will update. Anytime a text file is placed in test
dir you will see predictions. With new data, the cluster centers will change.
44](https://image.slidesharecdn.com/sparkmlstreaming-170609145624/75/Spark-ml-streaming-44-2048.jpg)