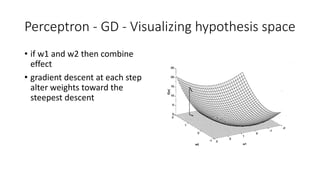
Perceptrons are a type of artificial neural network where each unit is called a perceptron. Perceptrons take a vector of inputs and can only deal with linearly separable functions like AND and OR, but not XOR. The perceptron training rule modifies weights at each step according to the error between the target and actual output. If there is no error, the weights are not updated. Gradient descent was introduced to handle non-linearly separable functions by finding weights for the best fit without a threshold, by minimizing the squared error over all training examples through iterative weight updates in the direction of steepest descent. The delta rule for gradient descent is similar to the perceptron rule but uses the linear unit output rather than the




![coding for perceptron training rule
• import numpy as np
• inputs = np.array([[0,0,-1],[0,1,-
1],[1,0,-1],[1,1,-1]])
• targets = np.array([[1],[0],[0],[0]])
• weights = np.array([[0.2],[0.1],[0.2]])
• for n in range(4):
•
• out = np.dot(inputs,weights)
• out=np.where(out>0,1,0)
•
• weights -=
0.25*np.dot(np.transpose(inputs
),(out-targets))
•
• print ("Iteration: ", n)
• print (weights)
• print (out)](https://image.slidesharecdn.com/perceptrons-191014072409/85/Perceptrons-4-320.jpg)