This document provides an overview of waveform coding techniques including prediction filtering, DPCM, delta modulation, ADPCM, LPC, and their principles. It discusses key concepts such as:
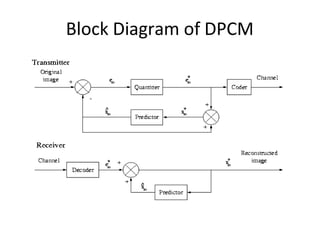
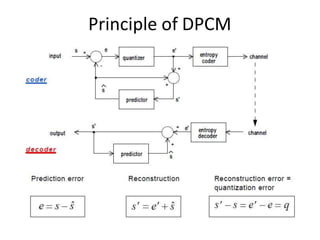
1. DPCM and ADPCM encode the difference between actual and predicted sample values, allowing lower bit rates by exploiting redundancy between samples.
2. Delta modulation uses adaptive quantization step sizes determined by the slope of the input signal to improve quality.
3. Linear predictive coding estimates future sample values as a linear combination of past samples to model the signal generation process and extract prediction errors for coding.
4. Various algorithms like Durbin and Schur can solve the autocorrelation or covariance matrices to determine the




















![• There are some limitations for the model
• (1) G(Z) = 1 then V(Z) = 1/A(Z) this is so called “Full
Poles εodels” and the parametric de-convolution
became coefficients(ai) estimation problem.
• (2) e(n) sequence is of form Ge(n), where e(n) is a
periodic pulse or a Gaussian white noise sequence.
For the first case e(n) = Σ6(n-rNp) and for the second
case R(k) = E[e(n)e(n+k)] = 6(k) and the value of
e(n) satisfied with Normal distribution. G is a non-
negative real number controlling the amplitude.
• The way is x(n)->V(Z)(P,ai)->e(n),G->type of e(n)](https://image.slidesharecdn.com/jxxulv0squmscimcxlyz-waveform-codingunit-ii-dc-ppt-221006130316-76de2501/85/Waveform_codingUNIT-II_DC_-PPT-pptx-24-320.jpg)

![• σ2 = Σnε2(n) (time average replaced means)
• It could be proved that if x(n) is generated by “full
poles” model : x(n) = -Σi=1
P ai x(n-i) + Ge(n) and
optimized P’ = P
, optimized ai = ai, σ2 is minimal.
• σ2 = Σn [x(n) -Σi=1
P ai x(n-i)]2
• ={Σn x2(n)}-2Σi=1
P ak{Σn x(n-k)x(n)}+
• Σk=1
PΣi=1
P akai{Σn x(n-k)x(n-i)}
• By setting ð(σ2 )/ ðak = 0 we can get
• -2 {Σn x(n-k)x(n)}+2Σi=1
P ai{Σn x(n-k)x(n-i)}=0
• Or Σi=1
P aiφ(k,i) = φ(k,0)
• if φ(k,i) =Σn x(n-k)x(n-i) 1<=i<=P and 1<=k<=P](https://image.slidesharecdn.com/jxxulv0squmscimcxlyz-waveform-codingunit-ii-dc-ppt-221006130316-76de2501/85/Waveform_codingUNIT-II_DC_-PPT-pptx-26-320.jpg)
![i=1 i
• Σ P a φ(k,i) = φ(k,0), k=1~P is called δPC
canonical equations. There are some different
algorithms to deal with the solution.
k=0 k 0
• [σ2]min = Σ P a φ(k,0) with a = 1
• So if we have x(n), φ(k,i) could be calculated,
and equations could be solved to get ai and
[σ2]min also could be obtained. For short-time
speech signal according to different lower and
upper limitation of the summary we could
have different types of equations. We will
discuss these different algorithms later.](https://image.slidesharecdn.com/jxxulv0squmscimcxlyz-waveform-codingunit-ii-dc-ppt-221006130316-76de2501/85/Waveform_codingUNIT-II_DC_-PPT-pptx-27-320.jpg)

![• |R(0) R(1) …… R(P-1)| |a1| | R(1) |
• |R(1) R(0) …… R(P-2)| |a2| | R(2) |
• |………………………………….| |...| = …...
• |R(P-1) R(P-2) … R(0) | |ap| | R(P) |
• 6.2.1 Durbin Algorithm
• 1. E(0) = R(0)
• 2. Ki = [ R(i) - Σ aj R(i-j)]/E
(i-1) (i-1)
• 3. ai = Ki
(i)
• 4. aj = aj – Kiai-j
(i) (i-1) (i-j)
• 5. E(i) = (1-Ki )E
2 (i-1)
• Final solution is aj = aj(p)
1<=i<=p
1<=j<=i-1
1<=j<=p](https://image.slidesharecdn.com/jxxulv0squmscimcxlyz-waveform-codingunit-ii-dc-ppt-221006130316-76de2501/85/Waveform_codingUNIT-II_DC_-PPT-pptx-29-320.jpg)






![• (2) Coefficients of Logarithm Area Ratio
• gi = log(Ai+1/Ai) = log[(1-ki)/1+ki]) i=1~p
• Where A is the intersection area of i-th
segment of the lossless tube.
• ki = (1-exp(gi))/(1+exp(gi)) i=1~p
• (3) Cepstrum Coefficients
• cn = an + Σk=1 kckan-k/n, 1<=n<=p+1
n
•
n-1 kc a /n, n>p+1
= an + Σk=n-p k n-k](https://image.slidesharecdn.com/jxxulv0squmscimcxlyz-waveform-codingunit-ii-dc-ppt-221006130316-76de2501/85/Waveform_codingUNIT-II_DC_-PPT-pptx-36-320.jpg)




![• Replace z with expjω:
• P(expjω)=|A(P)(expjω)|expjφ(ω)[1+exp[-j((p+1)ω+
2φ(ω))]
• Q(expjω)=|A(P)(expjω)|expjφ(ω)[1+exp[-j((p+1)ω+
2φ(ω)+π)]
• If the roots of A(P)(z) are inside the unit circle, whenωis
0~π, φ(ω) changes from 0 and returns to 0, the amount
[(p+1)ω+2φ(ω)] will be 0~(p+1)π
• P(expjω)=0 : [(p+1)ω+2φ(ω)]=kπ, k=1,3,…P+1
• Q(expjω)=0 : [(p+1)ω+2φ(ω)]=kπ, k=0,2,…P
• The roots of P and Q : Zk = expjωk [(p+1)ω+2φ(ω)]=kπ,
k=0,1,2,…P+1
• And ω0 < ω1 < ω2 < … < ωP < ωP+1](https://image.slidesharecdn.com/jxxulv0squmscimcxlyz-waveform-codingunit-ii-dc-ppt-221006130316-76de2501/85/Waveform_codingUNIT-II_DC_-PPT-pptx-41-320.jpg)
















































![Attack surfaces and attack tress[inform]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture03-260108015941-a4dee53b-thumbnail.jpg?width=640&height=640&fit=bounds)
