Downloaded 21 times









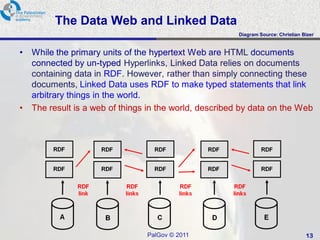


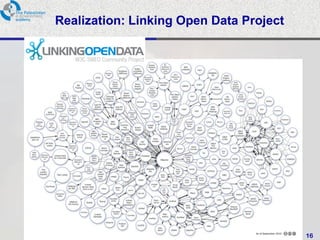



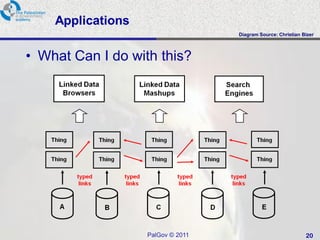
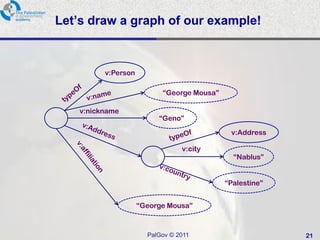


This document provides an overview of a tutorial on data integration and open information systems. It discusses the goals of the semantic web and linked data, which aim to create a universal medium for data exchange by publishing and connecting structured data on the web. Currently, web APIs allow access to data but use different data models and formats. Linked data uses common RDF standards and links entities to enable querying across diverse domains and data sources, forming a global data web.

































![[ABDO] Data Integration](https://cdn.slidesharecdn.com/ss_thumbnails/dataintegration-1232531198117886-2-thumbnail.jpg?width=640&height=640&fit=bounds)



























































