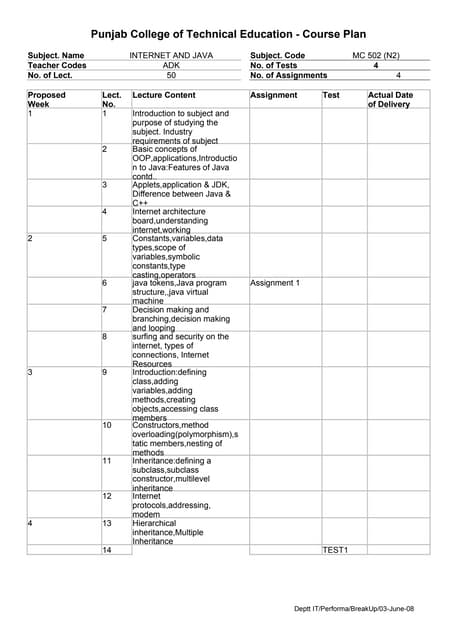
Download as PDF, PPTX




























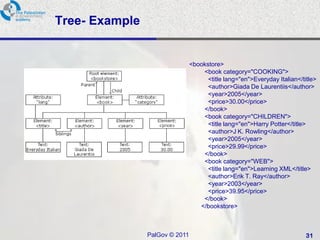


























The document discusses XML (Extensible Markup Language) basics and namespaces. It provides an overview of XML, describing it as a protocol for containing and managing information by allowing users to create their own markup languages. The document also discusses the need for namespaces to avoid conflicts between element names and introduces the syntax for using namespaces, which involves associating namespaces with prefixes.