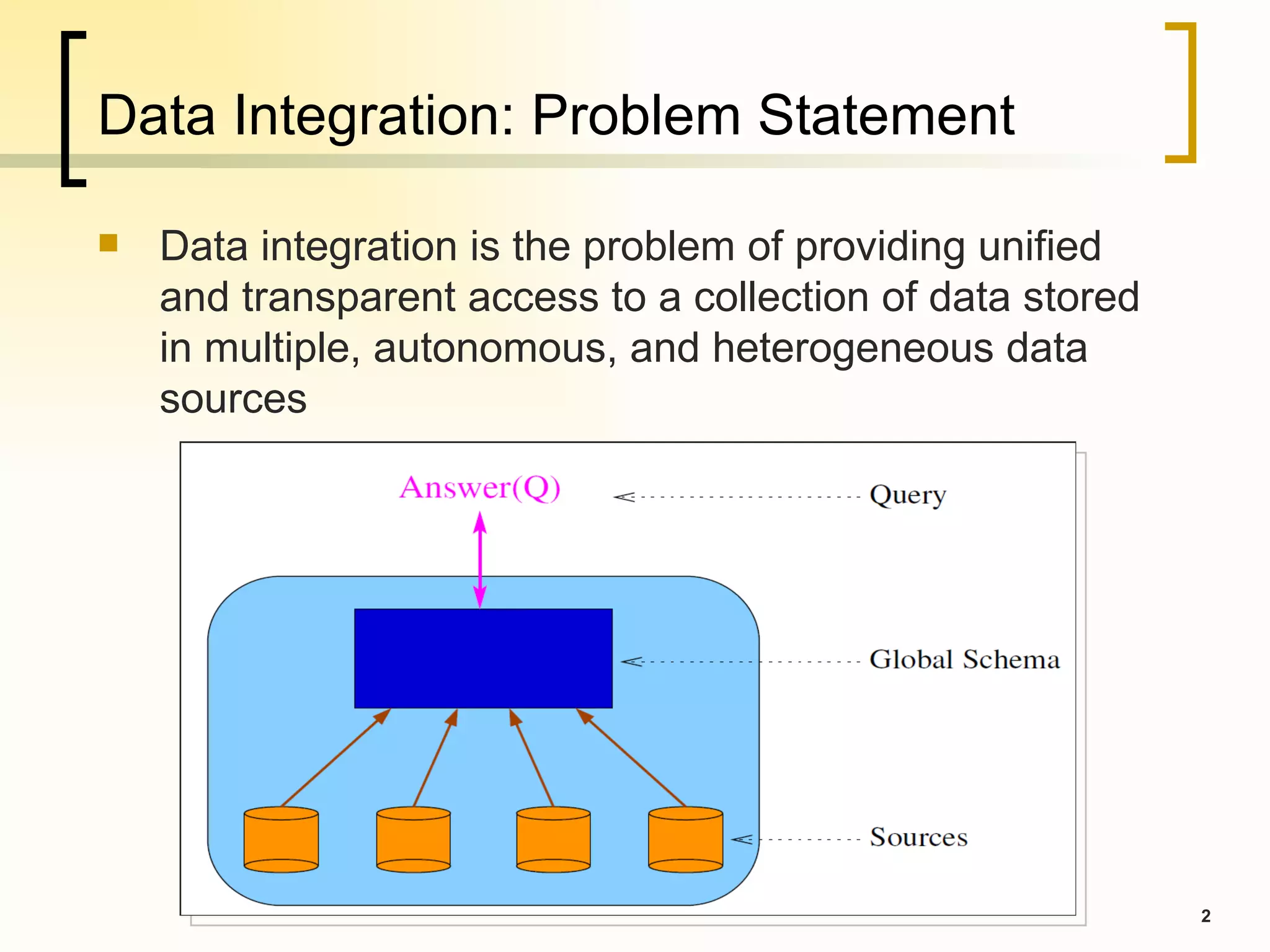

Data integration involves providing unified access to data stored across multiple heterogeneous data sources. There are several data integration architectures including data warehouses, virtual mediators, and peer-to-peer integration. Key challenges in data integration include modeling the global schema, source schemas, and mappings between them, as well as reformulating queries over the global schema to retrieve answers from the source schemas. Languages for modeling schema mappings include GAV, LAV, and GLAV, with different advantages for query reformulation and modularity when new sources are added.







![[DSBW Spring 2010] Unit 10: XML and Web And beyond](https://cdn.slidesharecdn.com/ss_thumbnails/dsbw-spring-2010-unit-10-xml-and-web-and-beyond3626-thumbnail.jpg?width=640&height=640&fit=bounds)









































![[ABDO] Logic As A Database Language](https://cdn.slidesharecdn.com/ss_thumbnails/logicasadblanguage-1232531111014566-3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSBW Spring 2009] Unit 07: WebApp Design Patterns & Frameworks (3/3)](https://cdn.slidesharecdn.com/ss_thumbnails/unit07-3-frameworks-090513110336-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSBW Spring 2009] Unit 04: From Requirements to the UX Model](https://cdn.slidesharecdn.com/ss_thumbnails/unit04-starting-090328141241-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSBW Spring 2009] Unit 02: Web Technologies (2/2)](https://cdn.slidesharecdn.com/ss_thumbnails/unit02-2-tech-090302113937-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSBW Spring 2009] Unit 06: Conallen's Web Application Extension for UML (WAE2)](https://cdn.slidesharecdn.com/ss_thumbnails/unit06-wae2-090328141625-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSBW Spring 2009] Unit 07: WebApp Design Patterns & Frameworks (1/3)](https://cdn.slidesharecdn.com/ss_thumbnails/unit07-1-wadp-090513110219-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSBW Spring 2009] Unit 03: WebEng Process Models](https://cdn.slidesharecdn.com/ss_thumbnails/unit03-process-090328140932-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSBW Spring 2009] Unit 09: Web Testing](https://cdn.slidesharecdn.com/ss_thumbnails/unit09-web-testing-090513110512-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSBW Spring 2009] Unit 02: Web Technologies (1/2)](https://cdn.slidesharecdn.com/ss_thumbnails/unit02-1-tech-090302113923-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSBW Spring 2009] Unit 01: Introducing Web Engineering](https://cdn.slidesharecdn.com/ss_thumbnails/unit01intro-1234552683396225-3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSBW Spring 2009] Unit 07: WebApp Design Patterns & Frameworks (2/3)](https://cdn.slidesharecdn.com/ss_thumbnails/unit07-2-wadp-090513110259-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSBW Spring 2009] Unit 05: Web Architectures](https://cdn.slidesharecdn.com/ss_thumbnails/unit05-architecture-090328141542-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSBW Spring 2009] Unit 08: WebApp Security](https://cdn.slidesharecdn.com/ss_thumbnails/unit08-web-security-090513110418-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



















