Download to read offline











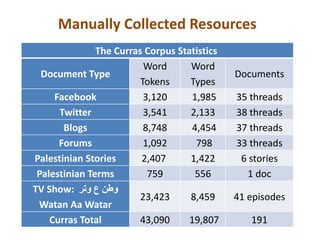





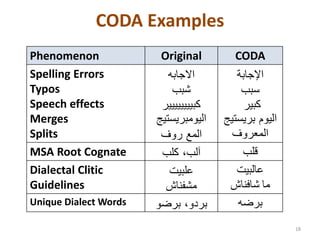








This document discusses a workshop presentation on building a corpus for Palestinian Arabic as part of the Curras project, highlighting the unique features of the dialect, collection and annotation processes, and challenges faced. The primary objective is to create a high-coverage and well-annotated corpus to support Arabic Natural Language Processing (NLP) tools, which have predominantly focused on Modern Standard Arabic. The project indicates the importance of developing a conventional orthography and tailored morphological annotation for Palestinian Arabic to advance NLP applications.



















![[DCSB] Torsten Roeder (BBAW), Yury Arzhanov (RuhrUniversität Bochum) "The Gl...](https://cdn.slidesharecdn.com/ss_thumbnails/dcsbroeder-arzhanov2013-11-19-131211134029-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)














