Download to read offline

























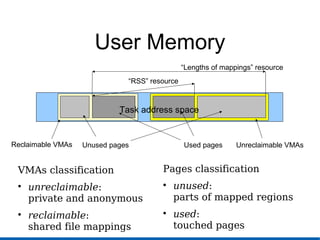








This document discusses recent advances in Linux kernel resource management through control groups (cgroups). It provides background on containers and their implementation, outlines existing resource management mechanisms and their shortcomings, and describes how cgroups provide a generic mechanism for grouping tasks and controlling their access to resources like CPU, memory, disk I/O through hierarchical groups and controllers. Specifically, it details the memory controller for cgroups which accounts for and reclaims user memory and triggers the OOM killer if limits are exceeded. Future work is needed to improve accounting of shared memory and implement other resource controllers.





































































































