Download to read offline









![ Chroot
Docker
LXC
Systemd-nspawn
Singularity
openVZ
Solaris Containers/Zone
AIX- WPAR
Linux-Vserver [Windos/Linux]](https://image.slidesharecdn.com/containers101-201013083048/85/Introduction-to-OS-LEVEL-Virtualization-Containers-10-320.jpg)


![ Kernel need userspace process help to understand which process is important and have
higher priority.[NICE]
Limit the usage of a given process.
Without CPU quotas many container process can starve and slows the system.
Every OS provide certain control to manage resource usage for per process.
Administrator can designate container specific CPU/Core.](https://image.slidesharecdn.com/containers101-201013083048/85/Introduction-to-OS-LEVEL-Virtualization-Containers-13-320.jpg)



![ Check Pointing
Running container make changes to the filesystem which remains intact if container engine
starts/stops
In memory data can be lost in such container engine start/stop events.
If container or host system crashes container instance and data may remain inconsistent in
filesystem
A robust container solution must have solution which allows to freeze a running container and
create a checkpoint as collection of files.
Linux provide CRIU mechanism to create Checkpoint/Restore in userspace.
[https://criu.org/Main_Page]
Live migration
A process to move live container from one physical server to another or cloud without
disconnecting from client.
Two kind of live migration
1) pre-copy memory 2)post-copy memory (lazy migration)](https://image.slidesharecdn.com/containers101-201013083048/85/Introduction-to-OS-LEVEL-Virtualization-Containers-17-320.jpg)









![[vasharma@vasharma ~]$ mount
sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime,seclabel)
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
devtmpfs on /dev type devtmpfs (rw,nosuid,seclabel,size=1743648k,nr_inodes=435912,mode=755)
securityfs on /sys/kernel/security type securityfs (rw,nosuid,nodev,noexec,relatime)
tmpfs on /dev/shm type tmpfs (rw,nosuid,nodev,seclabel)
devpts on /dev/pts type devpts (rw,nosuid,noexec,relatime,seclabel,gid=5,mode=620,ptmxmode=000)
tmpfs on /run type tmpfs (rw,nosuid,nodev,seclabel,mode=755)
pstore on /sys/fs/pstore type pstore (rw,nosuid,nodev,noexec,relatime)
tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,seclabel,mode=755)
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,pids)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,cpuset)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,memory)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,perf_event)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,hugetlb)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,freezer)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,net_prio,net_cls)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,cpuacct,cpu)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,blkio)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,seclabel,devices)
configfs on /sys/kernel/config type configfs (rw,relatime)
/](https://image.slidesharecdn.com/containers101-201013083048/85/Introduction-to-OS-LEVEL-Virtualization-Containers-27-320.jpg)



![ All major linux distribution has a Security framework consist of either
Apparmor or Selinux.
SELinux/APPaormor restrict capabilities of a process running on the host
operating system.
Both SELinux & APPaormor provides security lables to secure container
processes and files.
Example of a container process secured with SELINUX
system_u:system_r:container_t:s0:c940,c967
System_u : user [ user designated to run system services]
System_r : role [This role is for all system processes except user processes:]
container_t : Types [ prebuilt selinux type to run containers]
Running a docker container with apparmor security in Ubuntu
docker run --rm -it --security-opt apparmor=unconfined debian:jessie bash -i](https://image.slidesharecdn.com/containers101-201013083048/85/Introduction-to-OS-LEVEL-Virtualization-Containers-31-320.jpg)


![ Two Versions:
CGROUP – v1 [Linux Kernel ver 2.6.24 and later ]
CGROUP- v2 [ Linux Kernel ver. 4.5 and later
Both version are orthogonal
Currently, cgroups v2 implements only a subset of the controllers available in cgroups v1.
The two systems are implemented so that both v1 controllers and v2 controllers can be
mounted on the same system. But Container controller cannot simultaneously employed in
both.
CGROUP –v1 is named hierarchies.
Multiple instances of such hierarchies can be mounted; each hierarchy must have a unique name.
The only purpose of such hierarchies is to track processes.
mount -t cgroup -o none,name=somename none /some/mount/point](https://image.slidesharecdn.com/containers101-201013083048/85/Introduction-to-OS-LEVEL-Virtualization-Containers-34-320.jpg)



![ A child process created via fork(2) inherits its parent's cgroup memberships. A process's cgroup memberships are preserved across
execve(2).
The clone3(2) CLONE_INTO_CGROUP flag can be used to create a childprocess that begins its life in a different version 2 cgroup from
the parent process.
CGROUP-v1/v2 related file
# cat /proc/cgroups
#subsys_name hierarchy num_cgroups enabled
cpuset 3 1 1
cpu 9 1 1
cpuacct 9 1 1
memory 4 1 1
devices 11 92 1
freezer 7 1 1
net_cls 8 1 1
blkio 10 1 1
perf_event 5 1 1
hugetlb 6 1 1
pids 2 92 1
net_prio 8 1 1
# cat /proc/[pid]/cgroup
11:devices:/system.slice/gdm.service
10:blkio:/
9:cpuacct,cpu:/
/sys/kernel/cgroup/delegate : This file exports a list of the cgroups v2 files (one per line) that are delegatable.
/sys/kernel/cgroup/features : This file contains list of cgroups v2 features that are provided by the kernel.](https://image.slidesharecdn.com/containers101-201013083048/85/Introduction-to-OS-LEVEL-Virtualization-Containers-38-320.jpg)
![ Development library : libcgroup
yum install libcgroup ( this will install cgconfig)
yum install libcgroup-tools
Setup cgconfig service and restart it [ edit /etc/cgconfig.conf ]
mount {
controller_name = /sys/fs/cgroup/controller_name;
…
}
# systemctl restart cgconfig.service
CGROUP uses VFS.
CGROUP actions are filesystem operations i.e moun/unmout, create/delete directory etc.
Mounting CGROUP
# mkdir /sys/fs/cgroup/name
# mount -t cgroup -o controller_name none /sys/fs/cgroup/controller_name
Mount command will aattach controller cgroup
Verify whether cgroup is attached to the hierarchy correctly by listing all available hierarchies along with their current mount points using the lssubsys command
# lssubsys -am
cpuset /sys/fs/cgroup/cpuset
cpu,cpuacct /sys/fs/cgroup/cpu,cpuacct
memory /sys/fs/cgroup/memory
devices /sys/fs/cgroup/devices
freezer /sys/fs/cgroup/freezer
net_cls /sys/fs/cgroup/net_cls
blkio /sys/fs/cgroup/blkio
perf_event /sys/fs/cgroup/perf_event
hugetlb /sys/fs/cgroup/hugetlb
net_prio /sys/fs/cgroup/net_prio
Unmount hierarchy :
# umount /sys/fs/cgroup/controller_name](https://image.slidesharecdn.com/containers101-201013083048/85/Introduction-to-OS-LEVEL-Virtualization-Containers-39-320.jpg)
![ Use cgcreate command
cgcreate -t uid:gid -a uid:gid -g controllers:path
-g — specifies the hierarchy in which the cgroup should be created, as a comma-separated list of the controllers associated with hierarchies.
Alternatively we can create a child of cgroup directly using mkdir command
mkdir /sys/fs/cgroup/controller/name/child_name
To delete cgroup :
cgdelete controllers:path
Modify /etc/cgconfig.conf to set parameter of a control group.
perm {
task {
uid = task_user;
gid = task_group;
}
admin {
uid = admin_name;
gid = admin_group;
}
}
Alternatively we can use cgset command.
cgset -r parameter=value path_to_cgroup
Now we can move a desired process to cgroup
# cgclassify -g controllers:path_to_cgroup pidlist
Start a process in control group
# cgexec -g controllers:path_to_cgroup command arguments
Displaying Parameters of Control Groups
cgget -r parameter list_of_cgroups
# cgget -g cpuset /
group name {
[permissions]
controller {
param_name =
param_value; … } …
}
$ cgget -g cpuset /
/:
cpuset.memory_pressure_enabled: 0
cpuset.memory_spread_slab: 0
cpuset.memory_spread_page: 0
cpuset.memory_pressure: 0
cpuset.memory_migrate: 0
cpuset.sched_relax_domain_level: -1](https://image.slidesharecdn.com/containers101-201013083048/85/Introduction-to-OS-LEVEL-Virtualization-Containers-40-320.jpg)




![struct task_struct {
[...]
/* process credentials */
const struct cred __rcu *cred; /* effective (overridable) subjective task *
credentials (COW) */
[...]
/* namespaces */
struct nsproxy *nsproxy;](https://image.slidesharecdn.com/containers101-201013083048/85/Introduction-to-OS-LEVEL-Virtualization-Containers-47-320.jpg)
![struct nsproxy {
atomic_t count;
struct uts_namespace *uts_ns;
struct ipc_namespace *ipc_ns;
struct mnt_namespace *mnt_ns;
struct pid_namespace *pid_ns_for_children;
struct net *net_ns;
};
struct cred {
[...]
struct user_namespace *user_ns; /* user_ns the caps and keyrings are relative to. */
[...]
struct user_namespace {
[...]
struct user_namespace *parent;
struct ns_common ns;
[...]
};](https://image.slidesharecdn.com/containers101-201013083048/85/Introduction-to-OS-LEVEL-Virtualization-Containers-48-320.jpg)


![ [vasharma@vasharma ~]$ lsns
NS TYPE NPROCS PID USER COMMAND
4026531836 pid 2 9943 vasharma -bash
4026531837 user 2 9943 vasharma -bash
4026531838 uts 2 9943 vasharma -bash
4026531839 ipc 2 9943 vasharma -bash
4026531840 mnt 2 9943 vasharma -bash
4026531956 net 2 9943 vasharma –bash
To check list of namespace associated with a given process
lsns –p <pid of a container process>](https://image.slidesharecdn.com/containers101-201013083048/85/Introduction-to-OS-LEVEL-Virtualization-Containers-51-320.jpg)










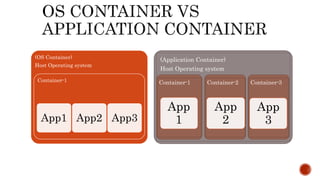
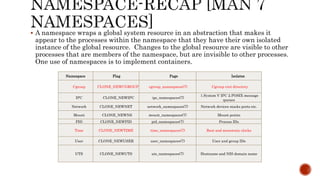
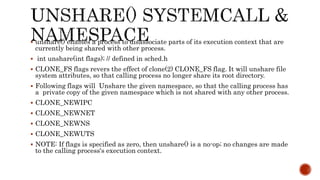
The document discusses the fundamentals and technical aspects of operating system-level virtualization, particularly focusing on containers and control groups (cgroups) in Linux. It covers the architecture, resource management, application containers, and their features, including memory and CPU quotas, filesystem isolation, and security measures through SELinux and AppArmor. The presentation also emphasizes practical examples and methodologies for effective containerization and resource allocation in a DevOps environment.



































































