Downloaded 554 times

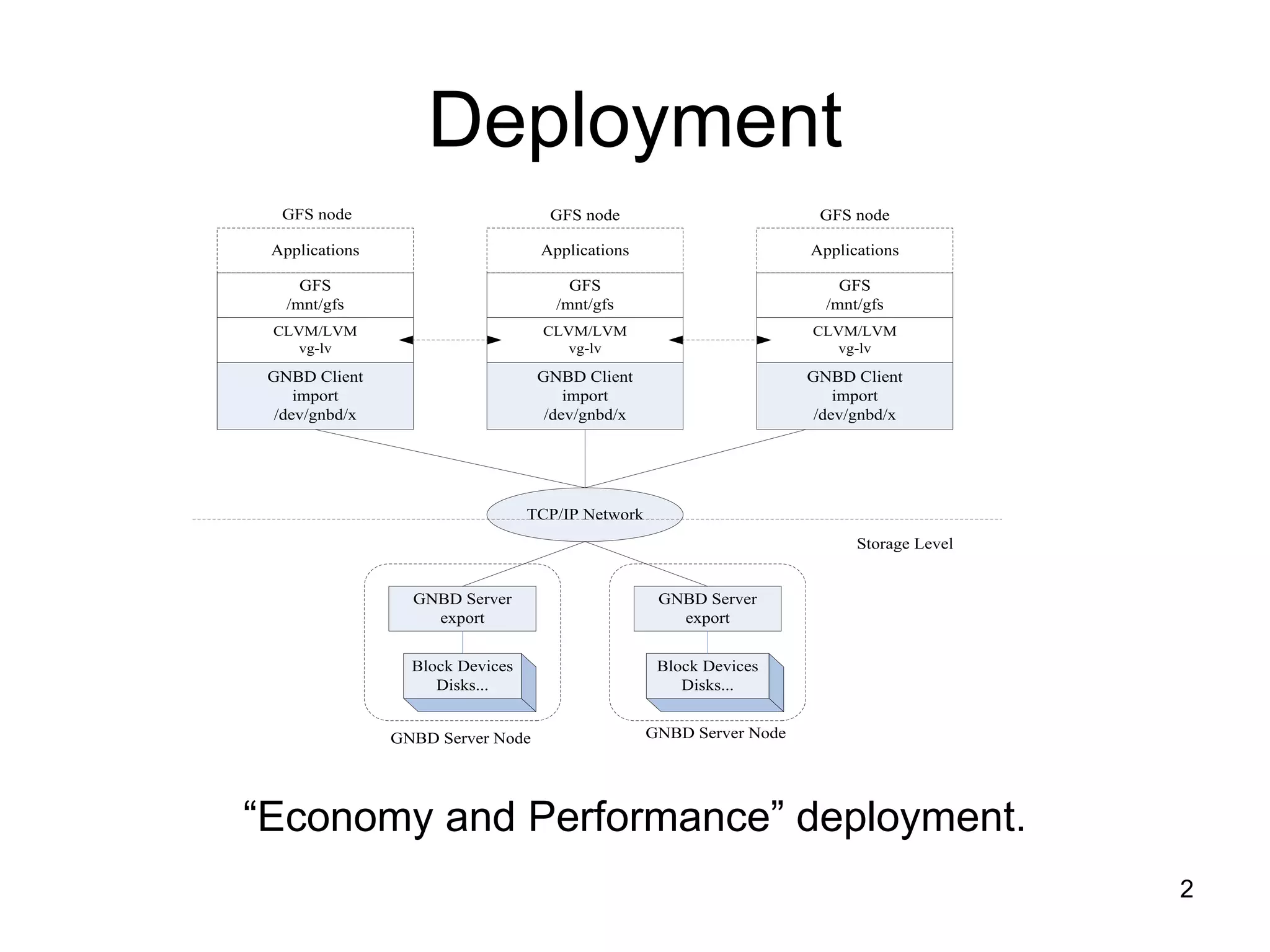
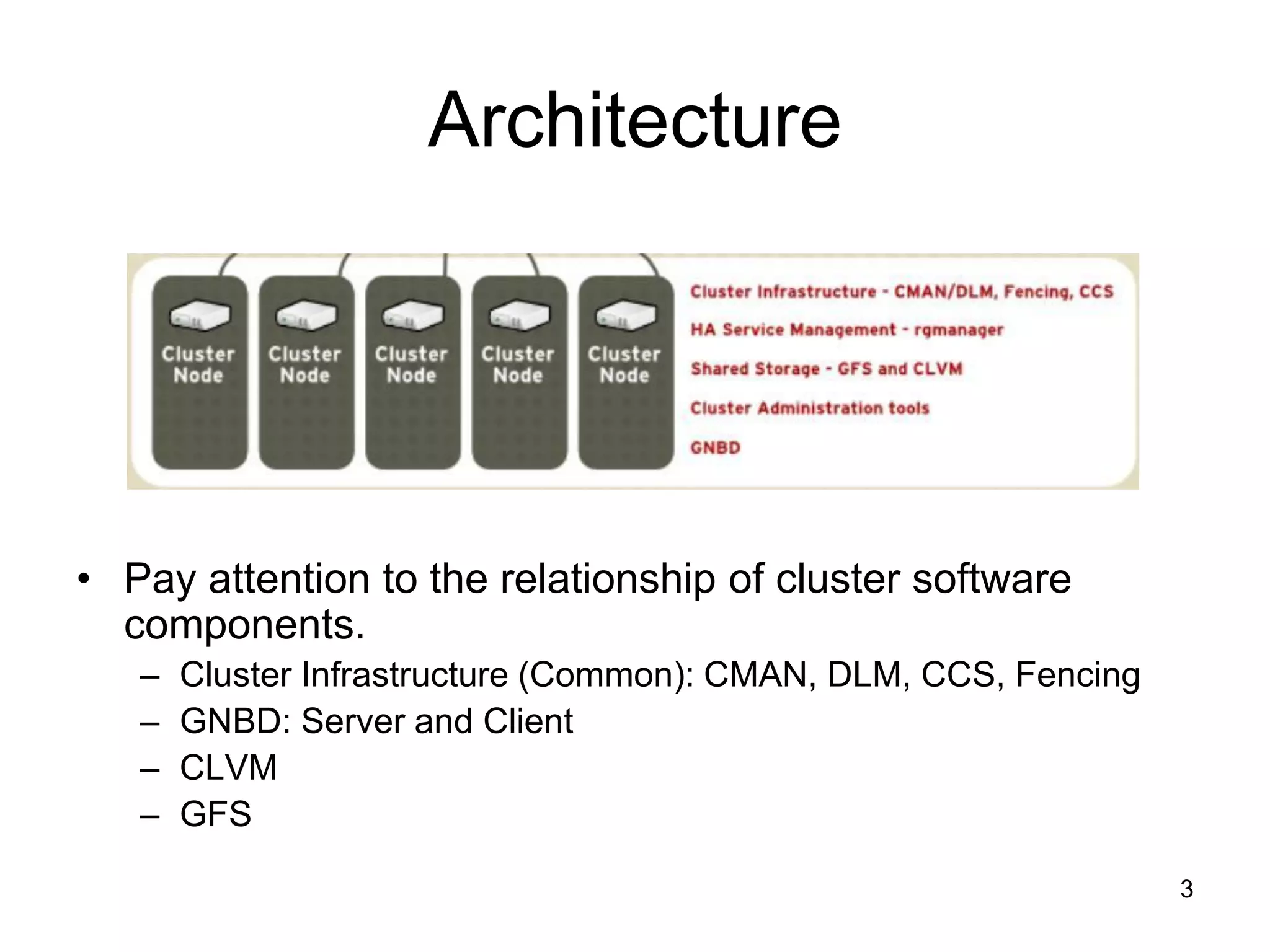






















This document describes the setup and architecture of a Red Hat Storage Cluster using Global File System (GFS), Clustered Logical Volume Manager (CLVM), and Global Network Block Device (GNBD). GFS allows nodes to share block-level storage over the network as if it were locally attached. GNBD exports block devices over TCP/IP to GFS nodes. CLVM provides cluster-wide logical volume management on top of shared block devices. The cluster uses components like CMAN, DLM, and fencing for distributed coordination and locking across nodes.
Introduction to Red Hat Storage Cluster with GFS, CLVM, and GNBD, enabling block-level storage sharing among nodes.
Overview of cluster components including Cluster Management (CMAN), Lock Management (DLM), Configuration Management (CCS), and Fencing.
GNBD exports block-level storage over TCP/IP to GFS; consists of server and client components.
CLVM manages cluster-wide storage; it uses LVM2 capabilities with synchronization for shared resources.
GFS allows simultaneous access to shared block devices, ensures a consistent file system view across nodes.
Emphasizes configuring fencing for GFS nodes to maintain data integrity.
Step-by-step guidelines to install software, setup GNBD server and client, configure CLVM and GFS, add nodes, and evaluate the cluster functionality.
















![[OpenInfra Days Korea 2018] Day 1 - T4-7: "Ceph 스토리지, PaaS로 서비스 운영하기"](https://cdn.slidesharecdn.com/ss_thumbnails/47openinfradaykorea2018hyun-ha-180705032301-thumbnail.jpg?width=640&height=640&fit=bounds)

























































![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)











![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)