07/14/2025 3
Topic Objective(CO2)
After completion of this topic, students will be able to understand:
• What is NoSQL?
• NoSQL Databases
4.
07/14/2025 4
What isNOSQL? (CO2)
• NoSQL database, also called Not Only SQL, is an approach to data
management and database design that's useful for very large sets of
distributed data.
• NoSQL is not a relational database. The reality is that a relational
database model may not be the best solution for all situations.
• The easiest way to think of NoSQL, is that of a database which does
not adhering to the traditional relational database management
system (RDMS) structure.
5.
07/14/2025 Hirdesh SharmaRCA E45 Big Data
Unit: 2
5
• Traditional Relational Databases (RDBMS)
• Use tables with rows and columns.
• Data is organized in a fixed schema (structure).
• Relationships between data are defined using keys (primary
keys, foreign keys).
• Examples: MySQL, PostgreSQL, Oracle, SQL Server.
What is NOSQL?
6.
07/14/2025 Hirdesh SharmaRCA E45 Big Data
Unit: 2
6
• NoSQL Databases
• Do not follow this strict table-based, relational structure.
• They are more flexible in how data is stored and organized.
• Can store data in various formats like:
– Documents (e.g., JSON or BSON) — MongoDB
– Key-Value pairs — Redis, DynamoDB
– Wide-column stores — Cassandra, HBase
– Graphs — Neo4j
• No fixed schema required — data can evolve easily without
altering a strict structure.
• Designed for scalability, high performance, and handling large
volumes of diverse data types.
What is NOSQL?
7.
07/14/2025 7
Why AreNoSQL Databases Interesting? / Why we should use
Nosql? / when to use Nosql?
There are several reasons why people consider using a NoSQL
database:
• Application development productivity
• Large data
• Analytics
Why Are NoSQL Databases Interesting? (CO2)
8.
07/14/2025 8
• Scalability:NoSQL databases are designed to scale; it’s one of the
primary reasons that people choose a NoSQL database.
• Massive write performance: This is probably the canonical usage
based on Google's influence, which implies key-value access,
MapReduce, replication, fault tolerance, consistency issues, and all
the rest. For faster writes in-memory systems can be used.
• Fast key-value access: This is probably the second most cited
virtue of NoSQL in the general mind set.
Why Are NoSQL Databases Interesting? (CO2)
9.
07/14/2025 9
Why AreNoSQL Databases Interesting? (CO2)
• Flexible data model and flexible datatypes: NoSQL products
support a whole range of new data types. We have: column-oriented,
graph, advanced data structures, document-oriented, and key-value.
Complex objects can be easily stored without a lot of mapping.
• Schema migration
• Write availability
• Easier maintainability, administration and operations
10.
07/14/2025 10
• Nosingle point of failure
• Generally available parallel computing
• Programmer ease of use: Accessing your data should be easy.
Programmers grok keys, values, JSON, Javascript stored procedures,
HTTP, and so on. NoSQL is for programmers.
Why Are NoSQL Databases Interesting? (CO2)
11.
07/14/2025 11
• Usethe right data model for the right problem: Different data
models are used to solve different problems.
• Distributed systems and cloud computing support: Not everyone
is worried about scale or performance over and above that which
can be achieved by non-NoSQL systems.
Why Are NoSQL Databases Interesting? (CO2)
12.
07/14/2025 12
Difference betweenSQL and NoSQL (CO2)
• SQL databases are primarily called as Relational Databases
(RDBMS); whereas NoSQL database are primarily called as non-
relational or distributed database.
• SQL databases are table based databases whereas NoSQL databases
are document based, key-value pairs, graph databases or wide-
column stores.
13.
07/14/2025 13
Difference betweenSQL and NoSQL (CO2)
• SQL databases are scaled by increasing the horse-power of the
hardware. NoSQL databases are scaled by increasing the databases
servers in the pool of resources to reduce the load.
• SQL database examples: MySql, Oracle, Sqlite, Postgres and MS-
SQL. NoSQL database examples: MongoDB, BigTable, Redis,
RavenDb, Cassandra, Hbase, Neo4j and CouchDb.
14.
07/14/2025 14
• Forthe type of data to be stored: SQL databases are not best fit for
hierarchical data storage. But, NoSQL database fits better for the
hierarchical data storage as it follows the key-value pair way of
storing data similar to JSON data. NoSQL database are highly
preferred for large data set (i.e for big data).
Difference between SQL and NoSQL (CO2)
15.
07/14/2025 15
• Forproperties: SQL databases emphasizes on ACID properties
( Atomicity, Consistency, Isolation and Durability) whereas the
NoSQL database follows the Brewers CAP theorem ( Consistency,
Availability and Partition tolerance ).
• For DB types: On a high-level, we can classify SQL databases as
either open-source or close-sourced from commercial vendors.
NoSQL databases can be classified on the basis of way of storing
data as graph databases, key-value store databases, document store
databases, column store database and XML databases.
Difference between SQL and NoSQL (CO2)
16.
07/14/2025 16
Hirdesh SharmaRCA E45 Big Data Unit: 2
Type of NoSQL Database (CO2)
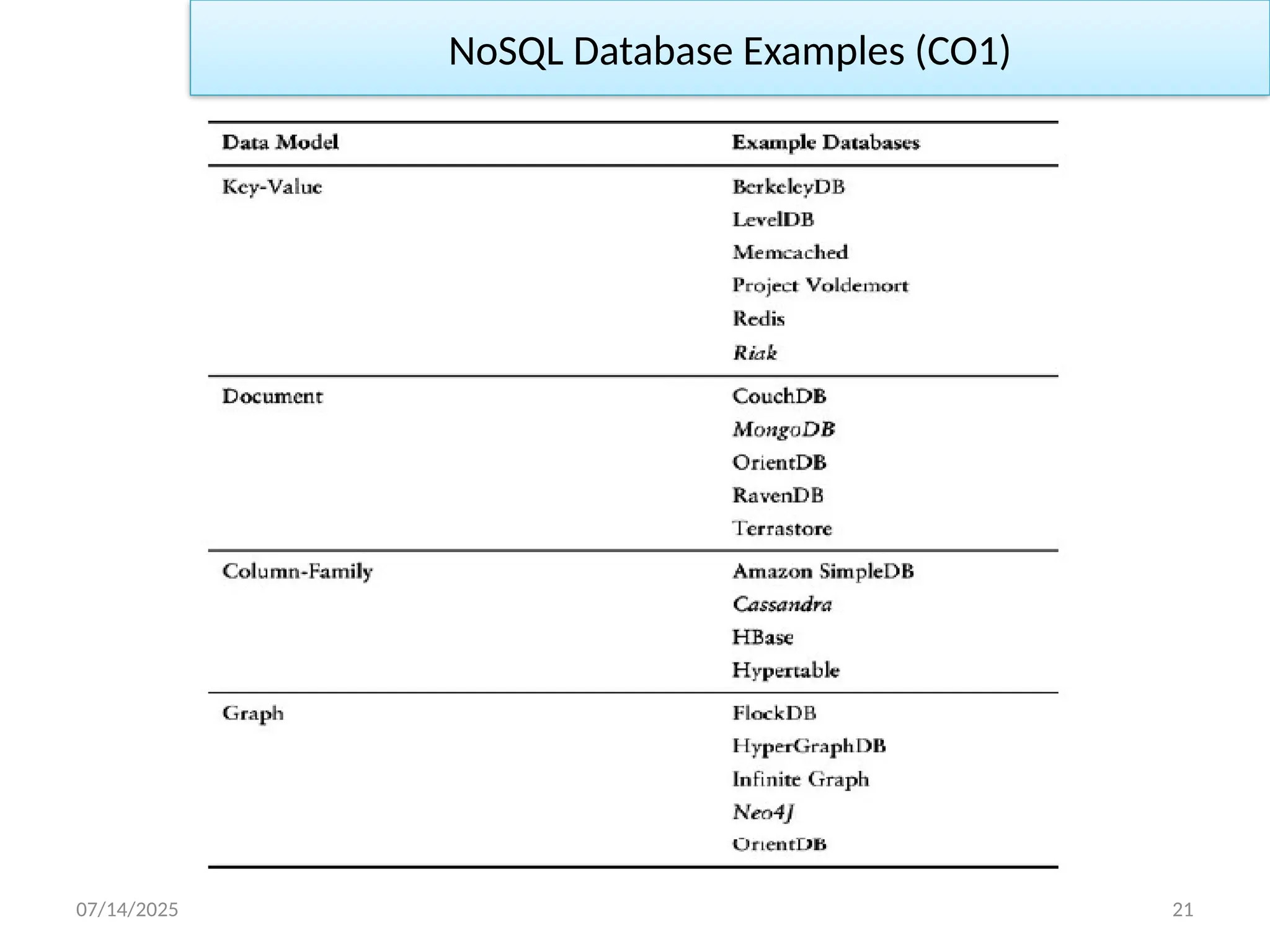
There are four general types of NoSQL databases, each with their
own specific attributes:
1. Key-Value storage
2. Document Databases
3. Column Storage
4. Graph Storage
17.
07/14/2025 17
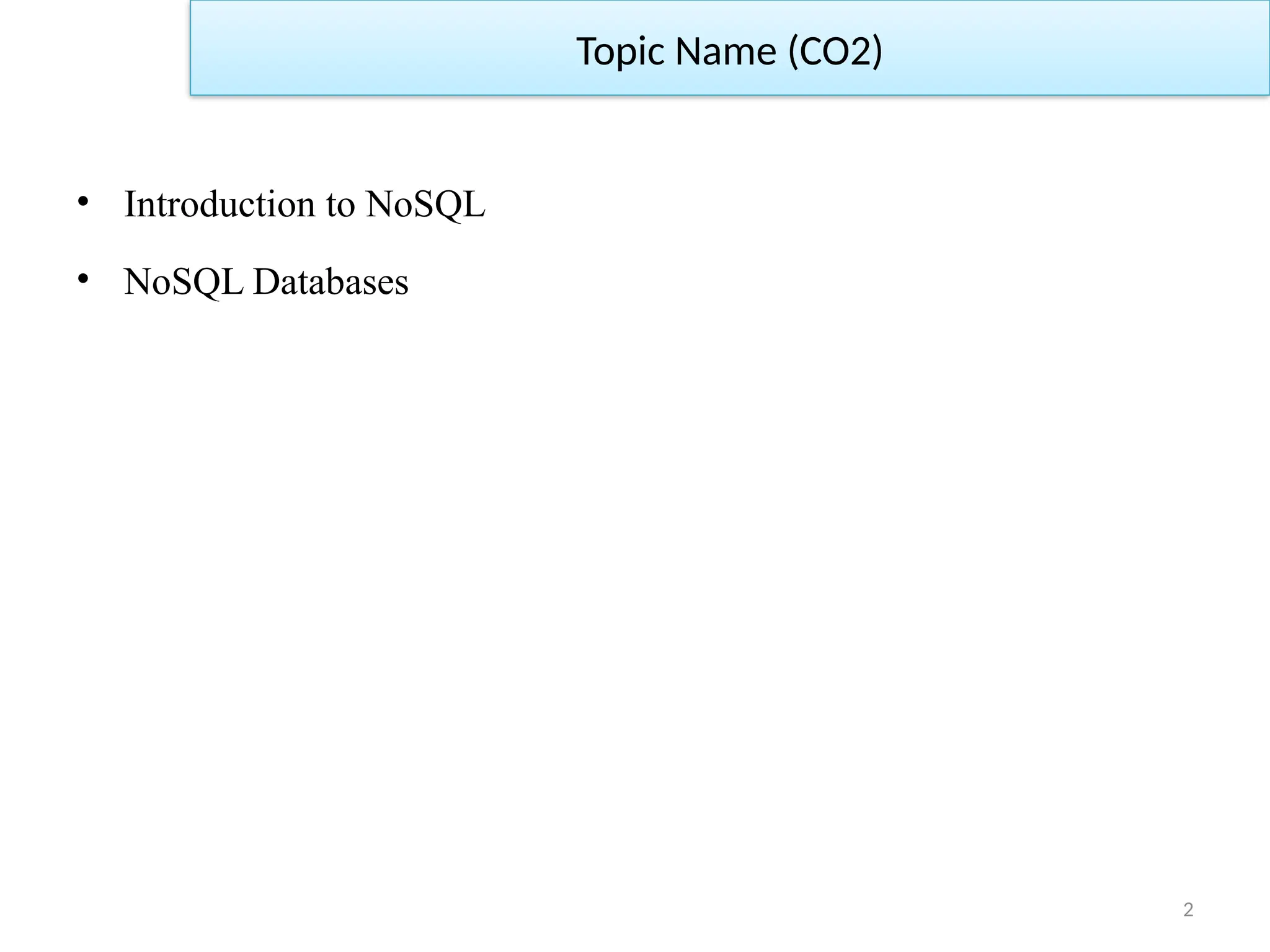
• Key-Valuestorage: This is the first category of NoSQL database.
Key-value stores have a simple data model, which allow clients to
put a map/dictionary and request value par key. In the key-value
storage, each key has to be unique to provide non-ambiguous
identification of values. For example:
Type of NoSQL Database (CO2)
18.
07/14/2025 18
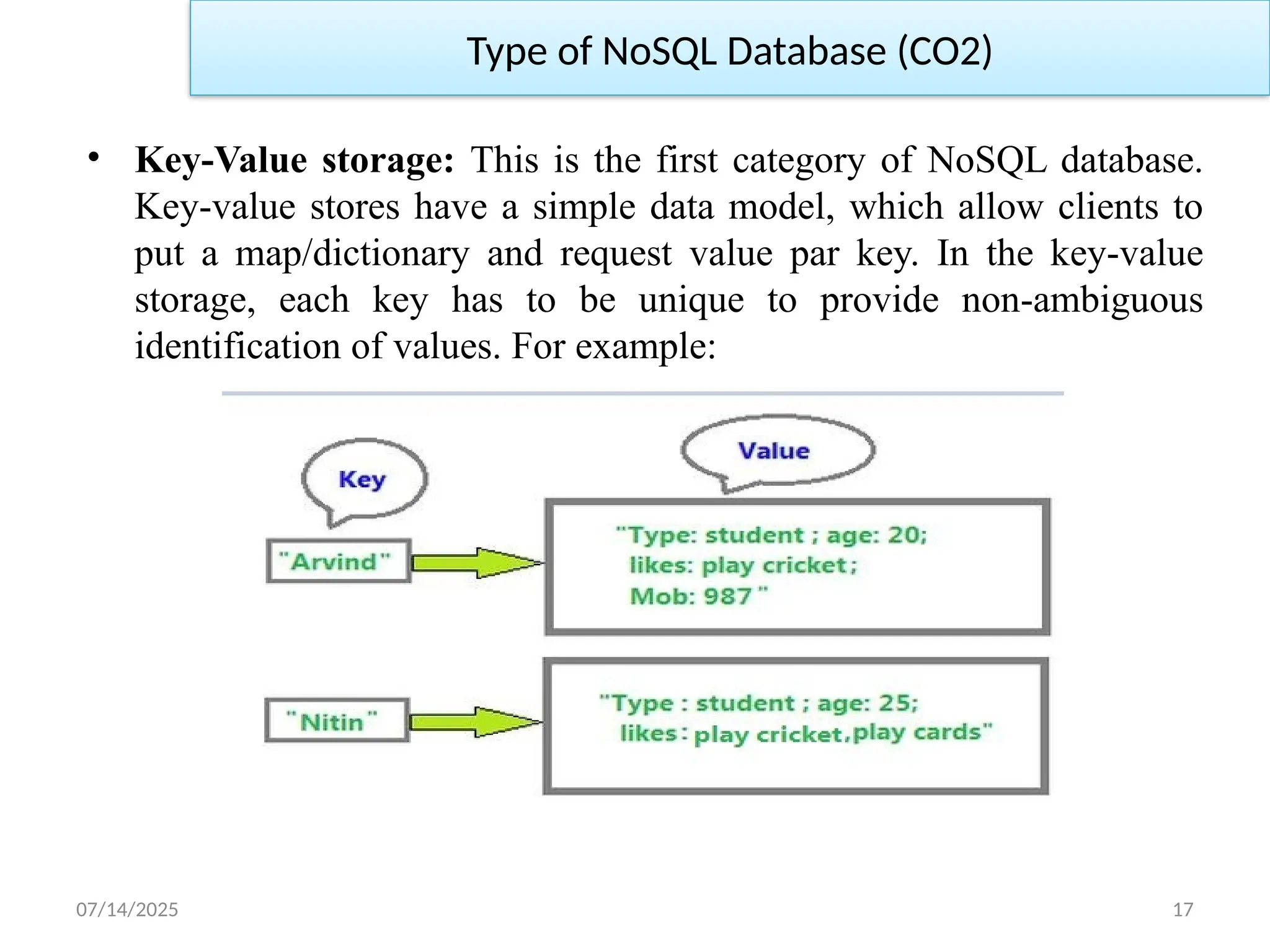
• Documentdatabases: In the document database NoSQL store
document in JSON format. JSON-based document are store in
completely different sets of attributes can be stored together, which
stores highly unstructured data as named value pairs and
applications that look at user behavior, actions, and logs in real time.
Type of NoSQL Database (CO2)
19.
07/14/2025 19
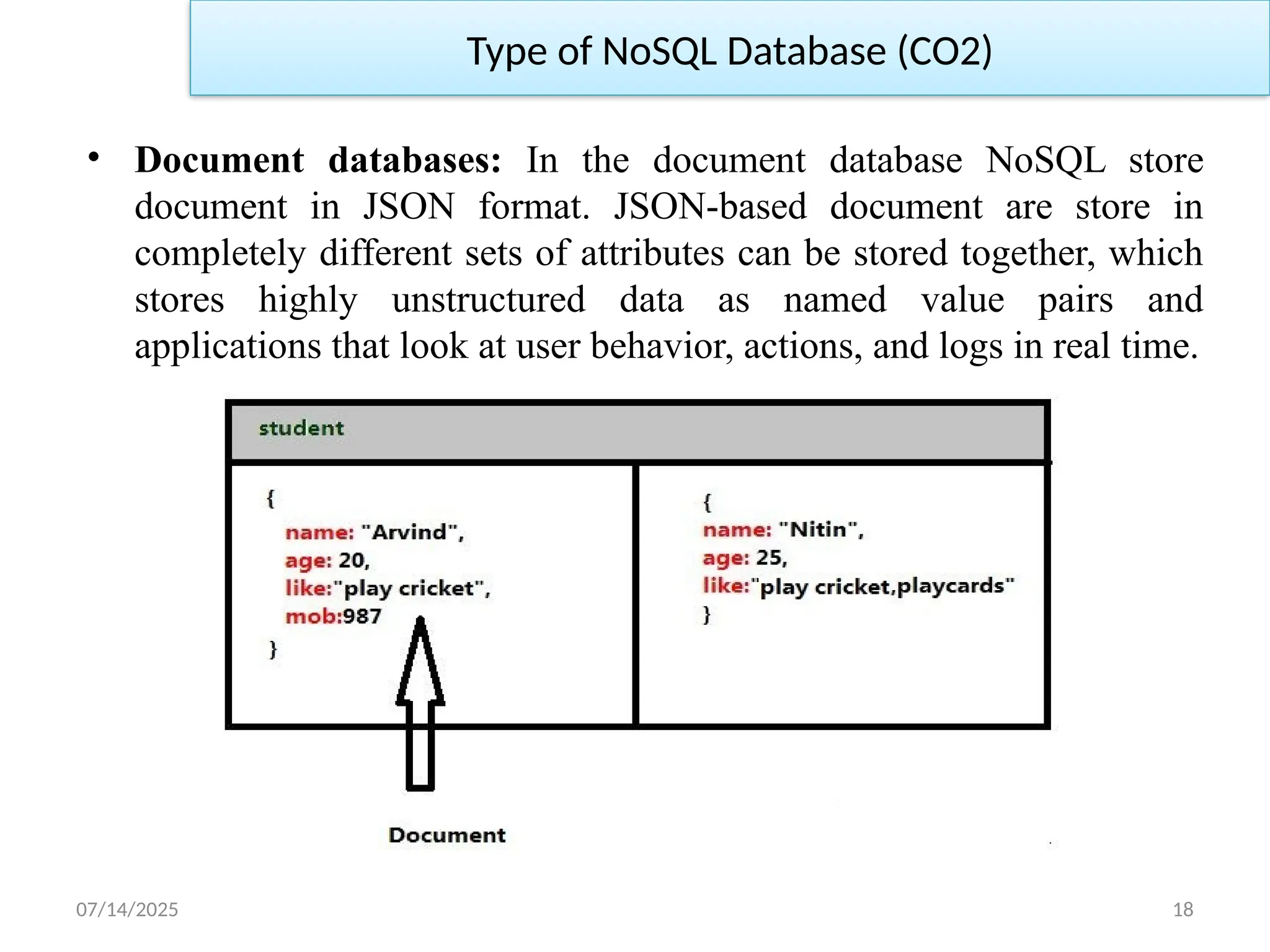
• Columnsstorage: Columnar databases are almost like tabular
databases. Thus keys in wide column store scan have many
dimensions, resulting in a structure similar to a multi-dimensional,
associative array. Shown in below example storing data in a wide
column system using a two-dimensional key.
Type of NoSQL Database (CO2)
20.
07/14/2025 20
Type ofNoSQL Database (CO2)
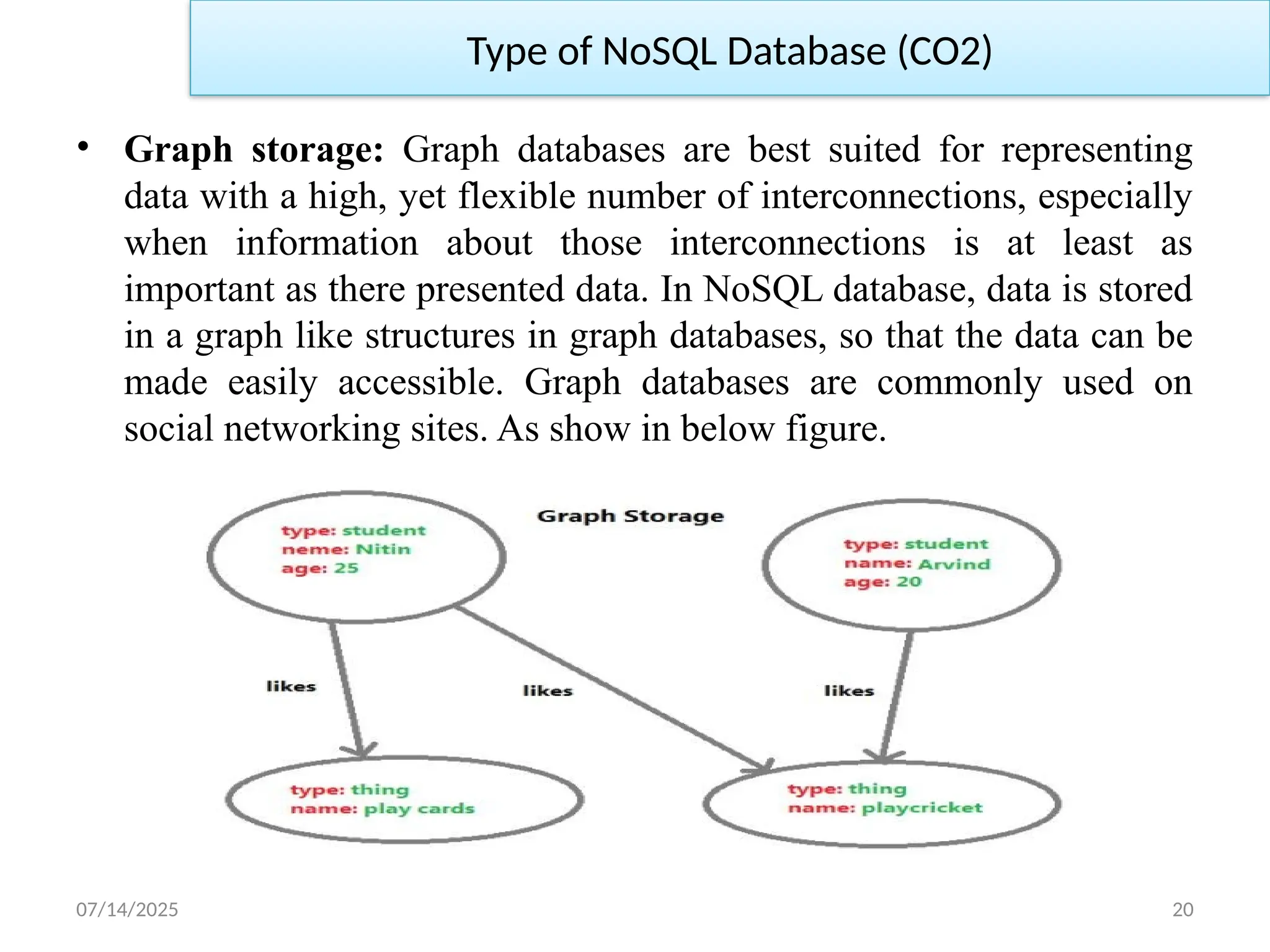
• Graph storage: Graph databases are best suited for representing
data with a high, yet flexible number of interconnections, especially
when information about those interconnections is at least as
important as there presented data. In NoSQL database, data is stored
in a graph like structures in graph databases, so that the data can be
made easily accessible. Graph databases are commonly used on
social networking sites. As show in below figure.
07/14/2025 22
Advantages
– Datapersistence
– Concurrency – ACID, transactions, etc.
– Integration across multiple applications
– Standard Model – tables and SQL
Disadvantages
– Impedance mismatch
– Integration databases vs. application databases
– Not designed for clustering
Pros and Cons of Relational Databases (CO2)
23.
07/14/2025 23
CONS
Impedance Mismatch
Intraditional relational databases, data is stored in tables with rows and
columns, while in most programming languages (especially object-oriented
ones), data is represented as objects.
Why it's a disadvantage:
– There’s a "mismatch" between how data is structured in the database (tables) and
how it's structured in the application (objects).
– This often requires extra work to map database tables to programming objects,
called Object-Relational Mapping (ORM).
– NoSQL tries to solve this by storing data in formats like JSON documents that
are closer to application objects, but sometimes this mismatch still exists,
especially when mixing NoSQL with relational data or legacy systems.
24.
07/14/2025 24
Integration Databasesvs. Application Databases
– Some databases are designed as integration points to bring data together
from multiple sources (integration databases).
– Others are designed primarily to support a specific application's data
needs (application databases).
Why it's a disadvantage:
– NoSQL databases are usually application-specific, optimized for a
particular app’s data access patterns.
– This can make it hard to integrate data from multiple systems or do
complex queries spanning different data sources, unlike relational
databases which excel at integration.
– So if your use case requires combining or analyzing data from many
systems, NoSQL might be less ideal.
25.
07/14/2025 25
Not Designedfor Clustering of NoSQL (in some cases)
– Clustering means running multiple database servers together to
work as a single system, providing high availability and scalability.
– Some early or simpler NoSQL databases were not built to support
clustering or distributed operation well.
Why it's a disadvantage:
– Without good clustering, databases can become a single point of
failure or struggle with scaling as data grows.
– This means they might not handle big loads or uptime requirements
as well as relational databases with mature clustering features.
– However, many modern NoSQL systems do support clustering and
distributed data, but it depends on the specific database.
26.
07/14/2025 26
Some commoncharacteristics of nosql include:
• Does not use the relational model (mostly)
• Generally open source projects (currently)
• Driven by the need to run on clusters
• Built for the need to run 21st century web properties
• Schema-less
• Polygot persistence
• Auto Sharding
Characteristics of NoSQL (CO2)
27.
07/14/2025 27
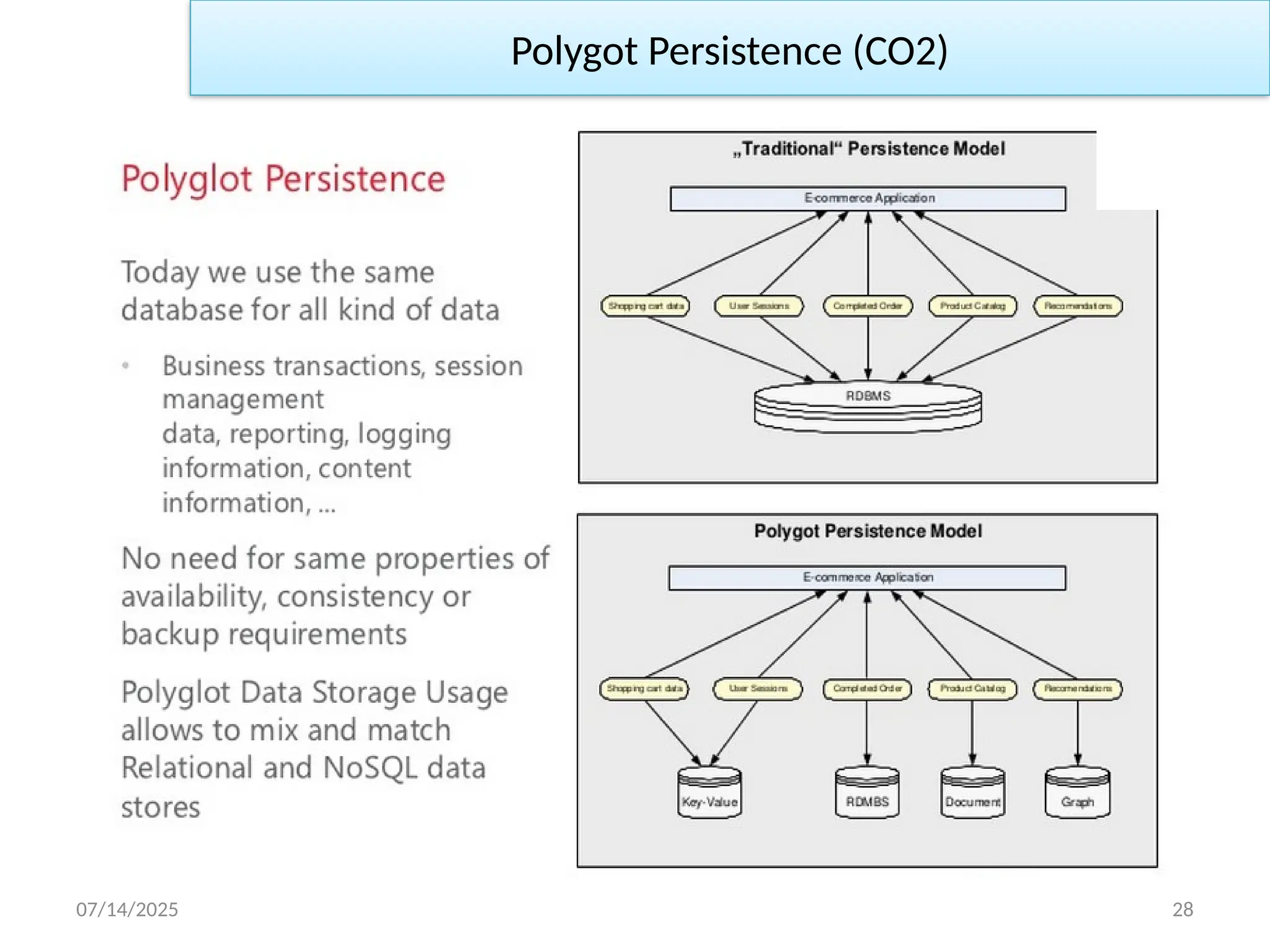
• Thepoint of view of using different data stores in different
circumstances is known as Polyglot Persistence.
• Polyglot persistence is commonly used to define this hybrid
approach.
• The definition of polyglot is “someone who speaks or writes several
languages.” The term polyglot is redefined for big data as a set of
applications that use several core database technologies.
Polygot Persistence (CO2)
07/14/2025 29
• Whatlicense is Hadoop distributed under?
a) Apache License 2.0
b) Mozilla Public License
c) Shareware
d) Commercial
• Which of the following genres does Hadoop produce?
a) Distributed file system
b) JAX-RS
c) Java Message Service
d) Relational Database Management System
Daily Quiz
30.
07/14/2025 30
Recap
• NoSQLdatabase, also called Not Only SQL, is an approach to data
management and database design that's useful for very large sets of
distributed data.
07/14/2025 32
Hirdesh SharmaRCA E45 Big Data Unit: 2
Topic Objective (CO2)
After completion of this topic, students will be able to understand:
• NoSQL Data Models
• Aggregate Data Models
33.
07/14/2025 33
• NoSQLdatabases have a very different model. For example, a
document-oriented NoSQL database takes the data you want to store
and aggregates it into documents using the JSON format.
• Each JSON document can be thought of as an object to be used by
your application.
• A JSON document might, for example, take all the data stored in a
row that spans 20 tables of a relational database and aggregate it into
a single document/object.
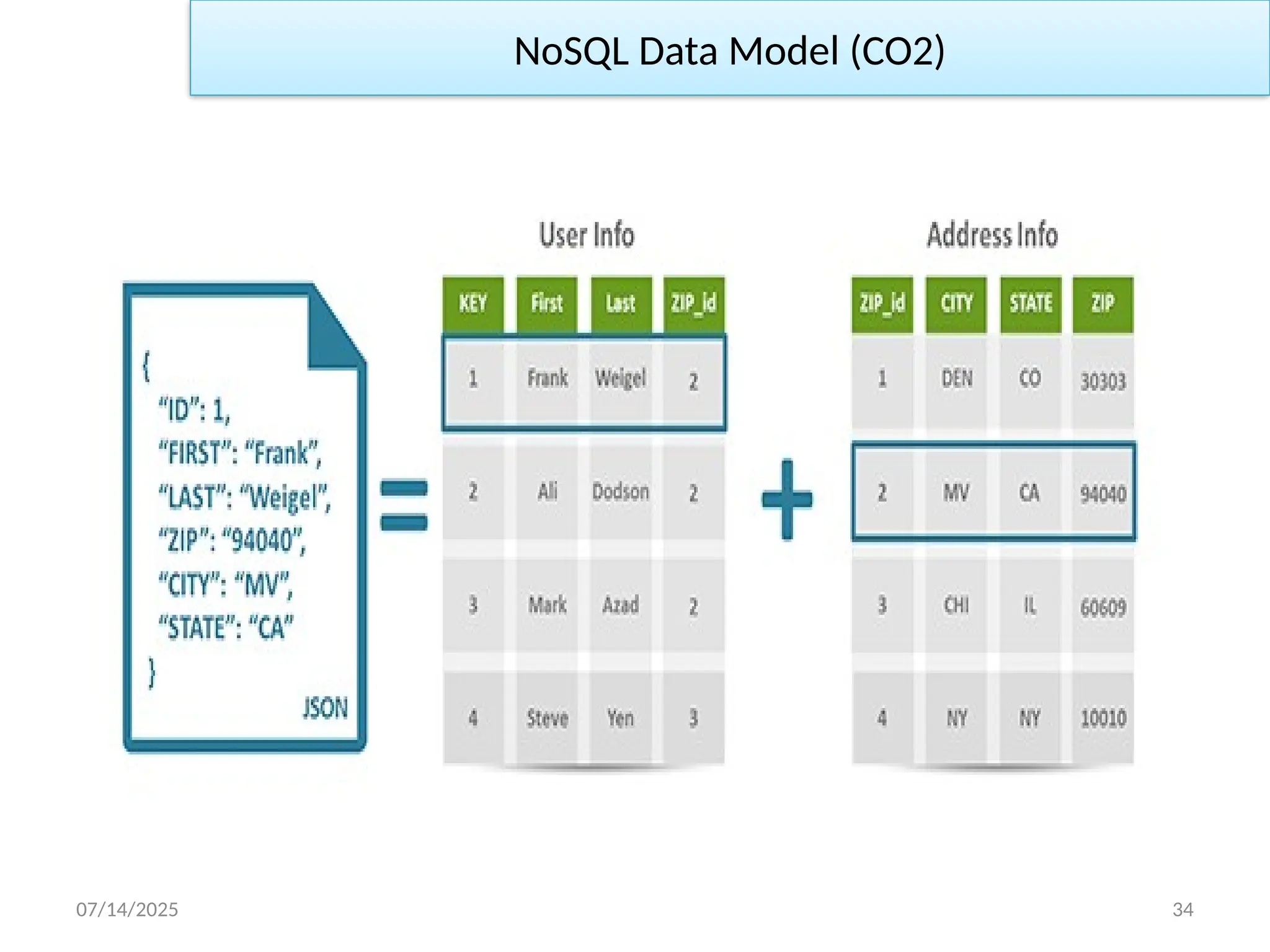
NoSQL Data Model (CO2)
07/14/2025 35
• Anothermajor difference is that relational technologies have rigid
schemas while NoSQL models are schemaless.
• The exact opposite of the behavior desired in the Big Data era,
where application developers need to constantly – and rapidly –
incorporate new types of data to enrich their apps.
NoSQL Data Model (CO2)
36.
07/14/2025 36
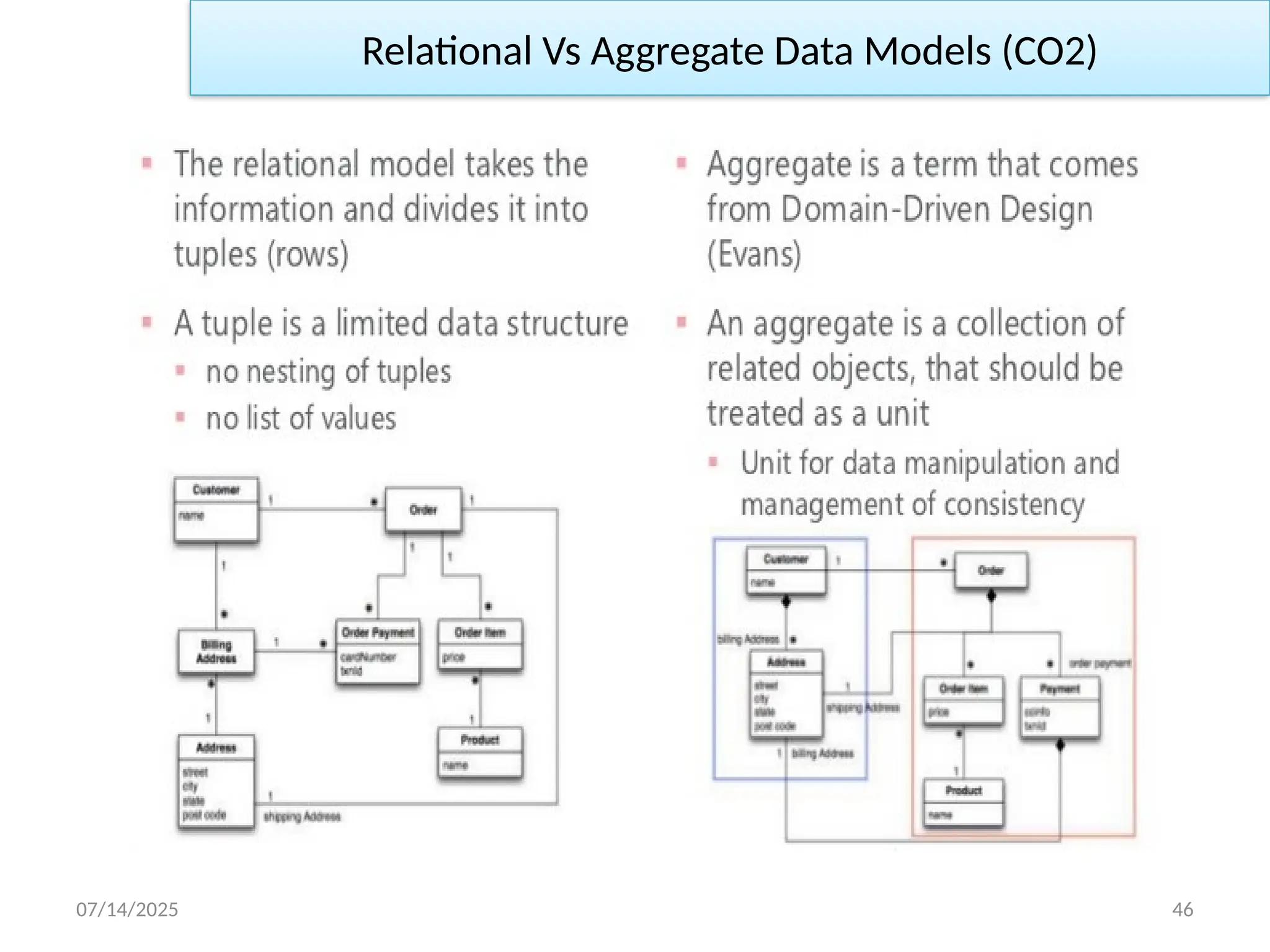
Aggregate DataModel in NoSQL (CO2)
• Data Model: A data model is the model through which we perceive
and manipulate our data.
• Relational Data Model: The relational model takes the information
that we want to store and divides it into tuples.
• Aggregate Model: Aggregate is a term that comes from Domain-
Driven Design, an aggregate is a collection of related objects.
37.
07/14/2025 37
Aggregate DataModel in NoSQL (CO2)
• Atomic property holds within an aggregate.
• Communication with data storage happens in unit of aggregate.
Example of Relations and Aggregates
• Let’s assume we have to build an e-commerce website; we are going
to be selling items directly to customers over the web.
• We can use this scenario to model the data using a relation data store
as well as NoSQL data stores and talk about their pros and cons.
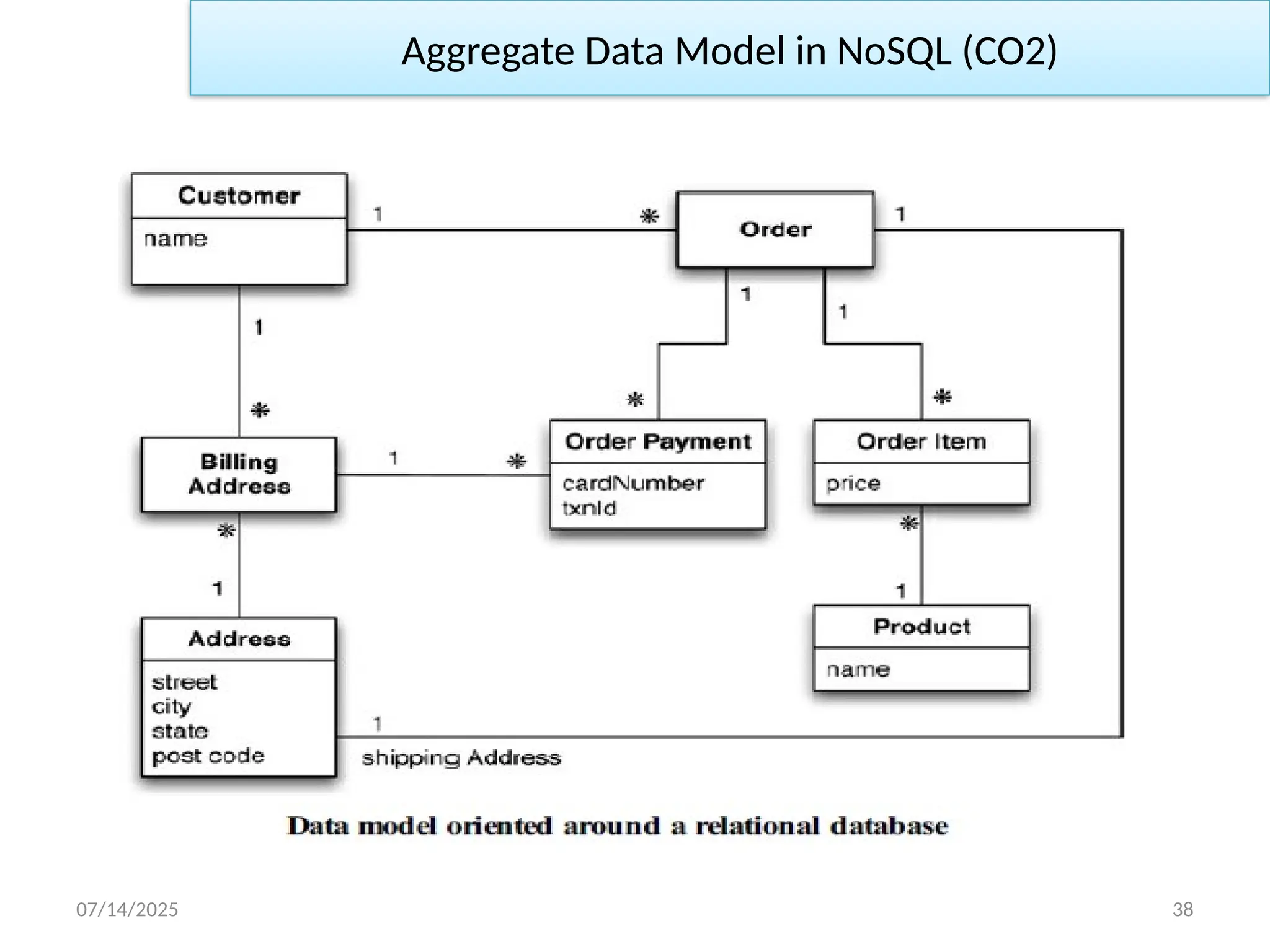
07/14/2025 39
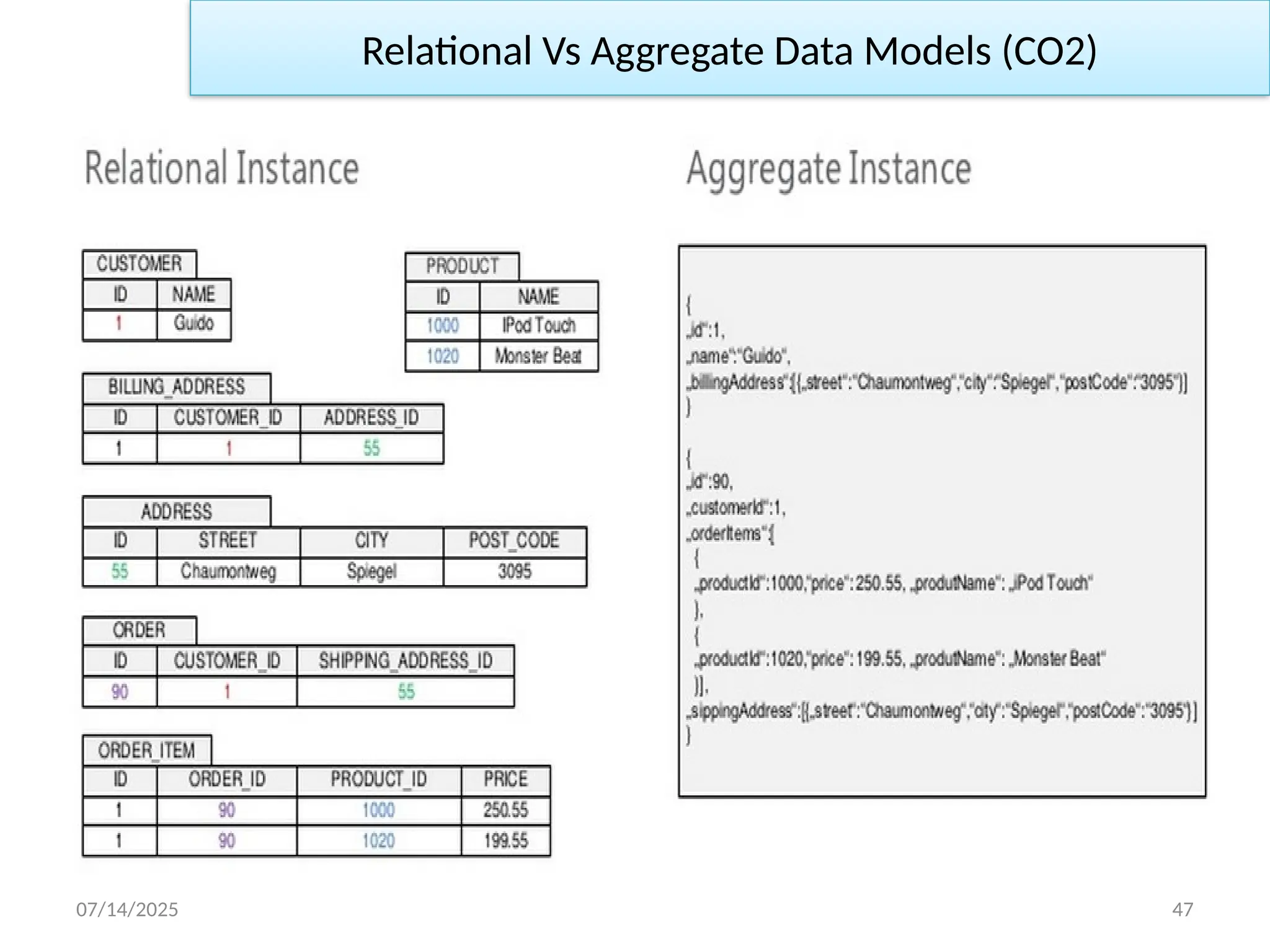
• Thefollowing figure presents some sample data for this model.
Aggregate Data Model in NoSQL (CO2)
40.
07/14/2025 40
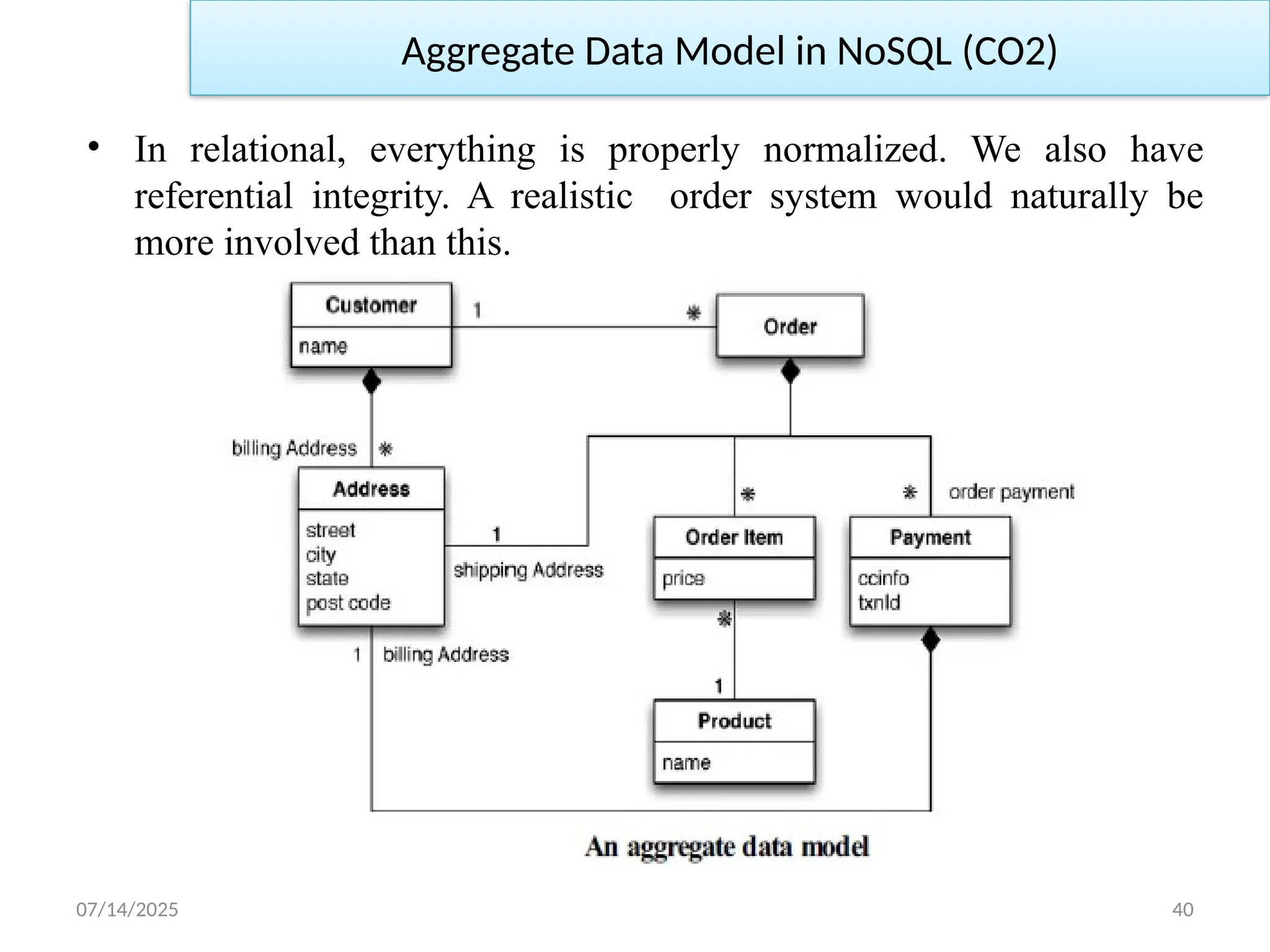
• Inrelational, everything is properly normalized. We also have
referential integrity. A realistic order system would naturally be
more involved than this.
Aggregate Data Model in NoSQL (CO2)
41.
07/14/2025 41
Again, wehave some sample data, which we’ll show in JSON
format as that’s a common representation for data in NoSQL.
// in customers
{ "
id":1,
"name":"Martin",
"billingAddress":[{"city":"Chicago"}]
}
// in orders
{ "
id":99,
"customerId":1,
"orderItems":[
Hirdesh Sharma RCA E45 Big Data Unit: 2
Aggregate Data Model in NoSQL (CO2)
42.
07/14/2025 42
{
"productId":27,
"price": 32.45,
"productName":"NoSQL Distilled"
}
],
"shippingAddress":[{"city":"Chicago"}]
"orderPayment":[
{
"ccinfo":"1000-1000-1000-1000",
"txnId":"abelif879rft",
"billingAddress": {"city": "Chicago"}
}
],
}
Aggregate Data Model in NoSQL (CO2)
43.
07/14/2025 43
Aggregate DataModel in NoSQL (CO2)
• In this model, we have two main aggregates: customer and order.
We’ve used the black-diamond composition marker in UML to show
how data fits into the aggregation structure.
• The customer contains a list of billing addresses; the order contains
a list of order items, a shipping address, and payments.
• The payment itself contains a billing address for that payment.
44.
07/14/2025 44
Aggregate OrientedDatabases (CO2)
Aggregate-oriented databases work best when most data interaction
is done with the same aggregate;
Key-value databases
– Stores data that is opaque to the database
– The database does cannot see the structure of records
– Application needs to deal with this
– Allows flexibility regarding what is stored (i.e. text or binary
data)
Document databases
– Stores data whose structure is visible to the database
– Imposes limitations on what can be stored
– Allows more flexible access to data (i.e. partial records) via
querying
45.
07/14/2025 45
Both key-valueand document databases consist of aggregate records
accessed by ID values
Column-family databases
– Two levels of access to aggregates (and hence, two pars to the
“key” to access an aggregate’s data)
– ID is used to look up aggregate record
– Column name – either a label for a value (name) or a key to a list
entry (order id)
– Columns are grouped into column families
Aggregate Oriented Databases (CO2)
07/14/2025 48
Schemaless Databases(CO2)
• A common theme across all the forms of NoSQL databases is that
they are schemaless.
• When you want to store data in a relational database, you first have
to define a schema—a defined structure for the database which says
what tables exist, which columns exist, and what data types each
column can hold.
• Before you store some data, you have to have the schema defined
for it.
49.
07/14/2025 49
Why schemaless?
–A schemaless store also makes it easier to deal with nonuniform
data
– When starting a new development project you don't need to
spend the same amount of time on up-front design of the
schema.
– No need to learn SQL or database specific stuff and tools.
– The rigid schema of a relational database (RDBMS). It can be
harder to push data into the DB as it has to perfectly fit the
schema.
Schemaless Databases (CO2)
50.
07/14/2025 50
Pros:
– Morefreedom and flexibility
– you can easily change your data organization
– you can deal with non uniform data
Cons:
– A program that accesses data: almost always relies on some form
of implicit schema, it assumes that certain fields are present ,
carry data with a certain meaning
– The implicit schema is shifted into the application code that
accesses data
Schemaless Databases (CO2)
51.
07/14/2025 51
Example:
You storeuser data in a schemaless database like MongoDB:
json
// In the database { "username": "sana123", "email":
"sana@example.com", "age": 25 }
In your application code:
python
def send_email(user):
if "@example.com" in user["email"]:
email_user(user["email"])
This code assumes:
•user["email"] exists
•It’s a string
•It contains an email
If email is missing or of the wrong type, the code may crash.
52.
07/14/2025 52
Multiple servers:
–In NoSQL systems, data distributed over large clusters.
Single server:
– simplest model, everything on one machine. Run the database on
a single machine that handles all the reads and writes to the data
store.
Distribution Models (CO2)
53.
07/14/2025 53
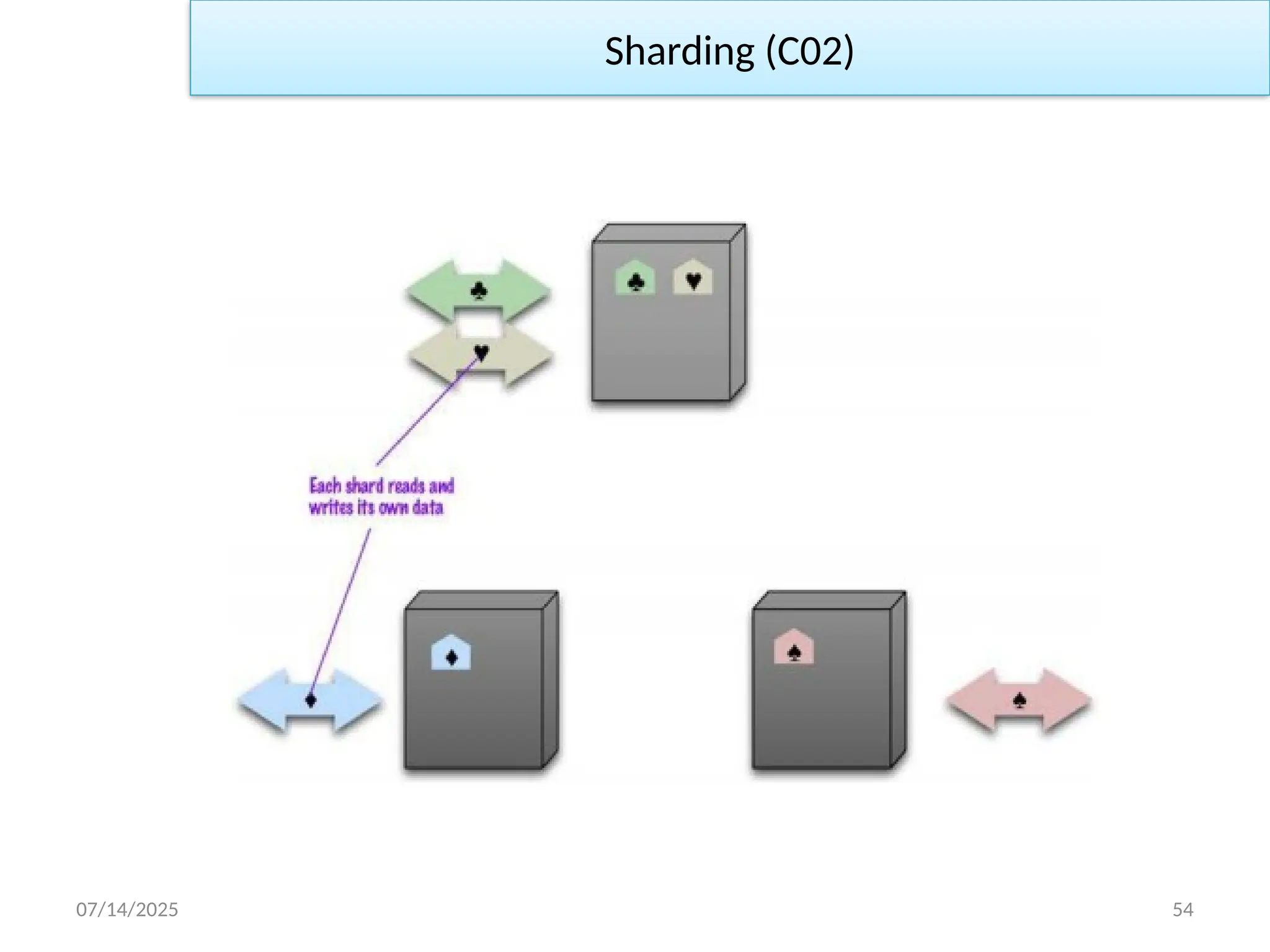
Sharding:
• DBSharding is nothing but horizontal partitioning of data. Different
people are accessing different parts of the dataset.
• In these circumstances we can support horizontal scalability by
putting different parts of the data onto different servers—a technique
that’s called sharding.
Orthogonal aspects of data distribution models (C02)
07/14/2025 55
• Differentparts of the data onto different servers
– Horizontal scalability
– Ideal case: different users all talking to different server nodes
– Data accessed together on the same node aggregate unit!
̶
• Pros: it can improve both reads and writes
• Cons: Clusters use less reliable machines resilience decreases
̶
• Many NoSQL databases offer auto-sharding
– the database takes on the responsibility of sharding
Sharding (C02)
56.
07/14/2025 56
Sharding (CO2)
Improvingperformance:
Main rules of sharding:
• Place the data close to where it’s accessed
– Orders for Boston: data in your eastern US data center
– If users in Boston access their data from a server in California, it will
be slower.
– Storing Boston user data in a data center in the eastern US improves
performance.
• Try to keep the load even
– All nodes should get equal amounts of the load
•Storing Boston user data in a data center in the eastern US improves performance.
lacing all items for a single order on the same shard makes reads/writes faster and simple
57.
07/14/2025 Hirdesh SharmaRCA E45 Big Data
Unit: 2
57
• Put together aggregates that may be read in sequence
Same order, same node
If one user’s order is spread across multiple shards, reading or updating it
becomes expensive.
Placing all items for a single order on the same shard makes reads/writes
faster and simpler.
58.
07/14/2025 58
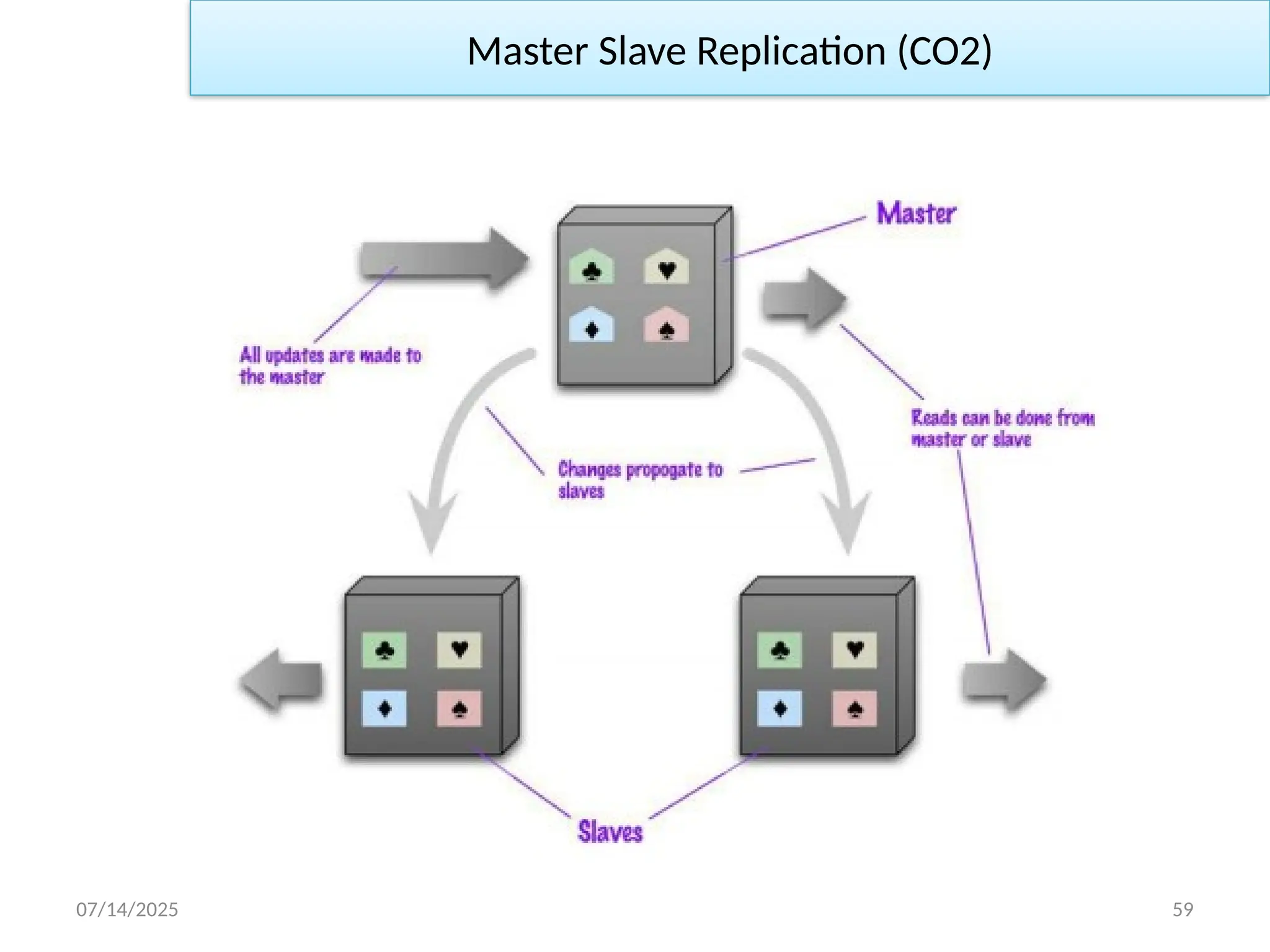
Master SlaveReplication (CO2)
Master
– is the authoritative source for the data
– is responsible for processing any updates to that data
– can be appointed manually or automatically
Slaves
– A replication process synchronizes the slaves with the master
– After a failure of the master, a slave can be appointed as new
master very quickly
07/14/2025 60
Pros andcons of Master-Slave Replication
Pros
– More read requests:
– Add more slave nodes
– Ensure that all read requests are routed to the slaves
Cons
– The master is a bottleneck
– Limited by its ability to process updates and to pass those
updates on
– Its failure does eliminate the ability to handle writes until:
Master Slave Replication (CO2)
07/14/2025 62
• Allthe replicas have equal weight, they can all accept writes
• The loss of any of them doesn’t prevent access to the data store.
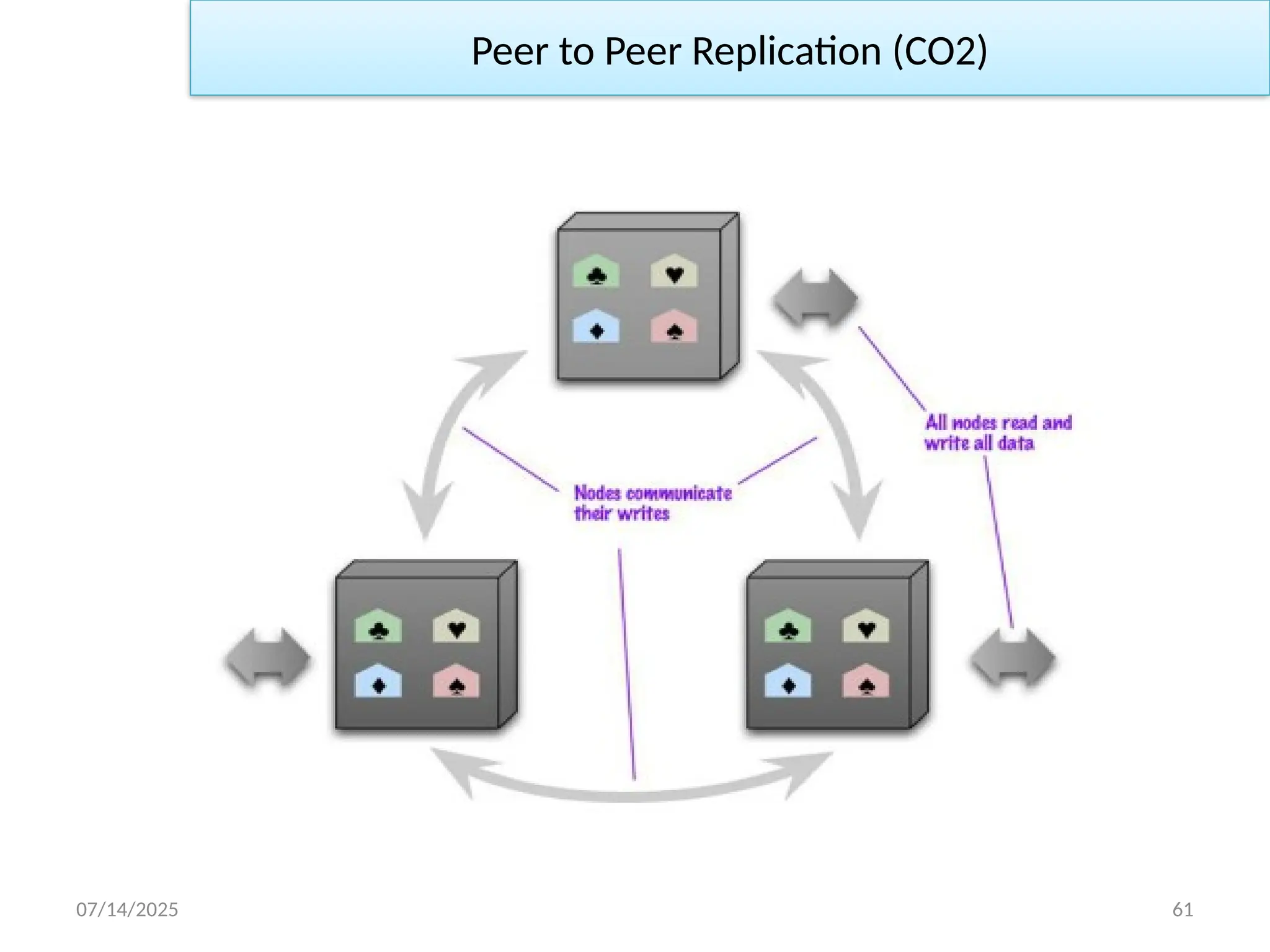
Pros and cons of peer-to-peer replication
Pros:
– you can ride over node failures without losing access to data
– you can easily add nodes to improve your performance
Cons:
– Inconsistency
– Slow propagation of changes to copies on different nodes
Peer to Peer Replication (CO2)
63.
07/14/2025 63
• Replicationand sharding are strategies that can be combined.
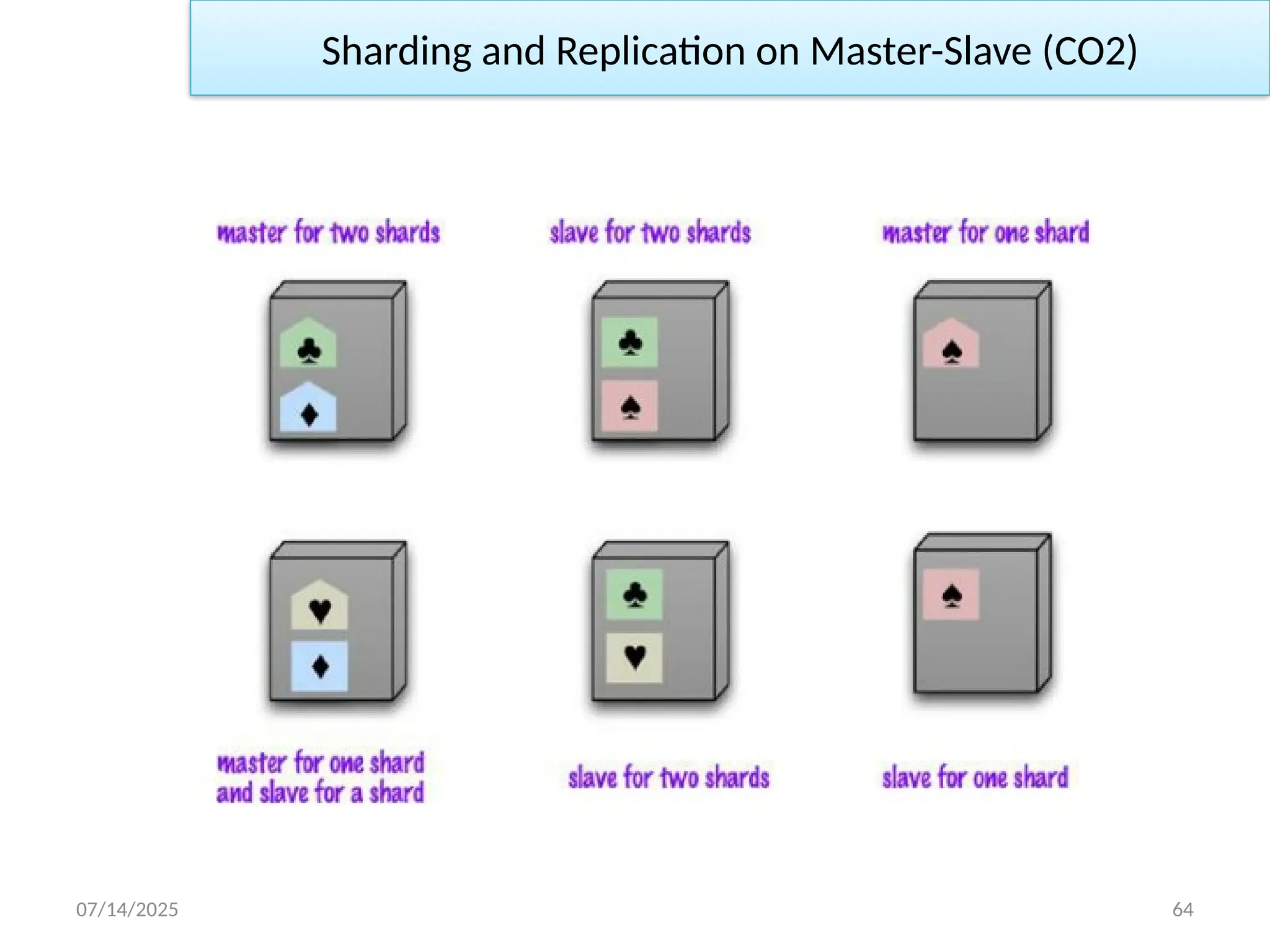
• If we use both master slave replication and sharding, this means that
we have multiple masters, but each data item only has a single
master.
• We have multiple masters, but each data only has a single master.
Two schemes:
– A node can be a master for some data and slaves for others
– Nodes are dedicated for master or slave duties
Sharding and Replication on Master-Slave (CO2)
07/14/2025 65
• Usingpeer-to-peer replication and sharding is a common strategy
for column family databases.
• Usually each shard is present on three nodes.
• A common strategy for column-family databases.
Sharding and Replication on P2P (CO2)
07/14/2025 67
Key Points:
–Sharding distributes different data across multiple servers, so
each server acts as the single source for a subset of data.
– Replication copies data across multiple servers, so each bit of
data can be found in multiple places.
A system may use either or both techniques. Replication comes in
two forms:
– Master-slave replication makes one node the authoritative copy
that handles writes while slaves synchronize with the master and
may handle reads.
– Peer-to-peer replication allows writes to any node; the nodes
coordinate to synchronize their copies of the data.
Replication (CO2)
68.
07/14/2025 68
Recap (CO2)
•Replication and sharding are strategies that can be combined.
• We have multiple masters, but each data only has a single master.
Two schemes:
– A node can be a master for some data and slaves for others
– Nodes are dedicated for master or slave duties
07/14/2025 70
Topic Objective(CO2)
After completion of this topic, students will be able to understand:
• Consistency
• Version Stamp
• Positioning and Combining
71.
07/14/2025 71
• Theconsistency property ensures that any transaction will bring the
database from one valid state to another.
• Relational databases has strong consistency whereas NoSQL
systems hass mostly eventual consistency.
• ACID: A DBMS is expected to support “ACID transactions,”
processes that are:
– Atomicity: either the whole process is done or none is
– Consistency: only valid data are written
– Isolation: one operation at a time
– Durability: once committed, it stays that way
Consistency (CO2)
72.
07/14/2025 72
Update Consistency(or write-write conflict):
• Martin and Pramod are looking at the company website and notice
that the phone number is out of date. Incredibly, they both have
update access, so they both go in at the same time to update the
number.
Hirdesh Sharma RCA E45 Big Data Unit: 2
Various forms of Consistency (CO2)
73.
07/14/2025 73
Update Consistency(or write-write conflict):
Solutions:
– Pessimistic approach
– Prevent conflicts from occurring
Approaches:
– conditional updates: test the value just before updating
– Do not work if there’s more than one server (peer-to-peer
replication)
Hirdesh Sharma RCA E45 Big Data Unit: 2
Various forms of Consistency (CO2)
74.
07/14/2025 74
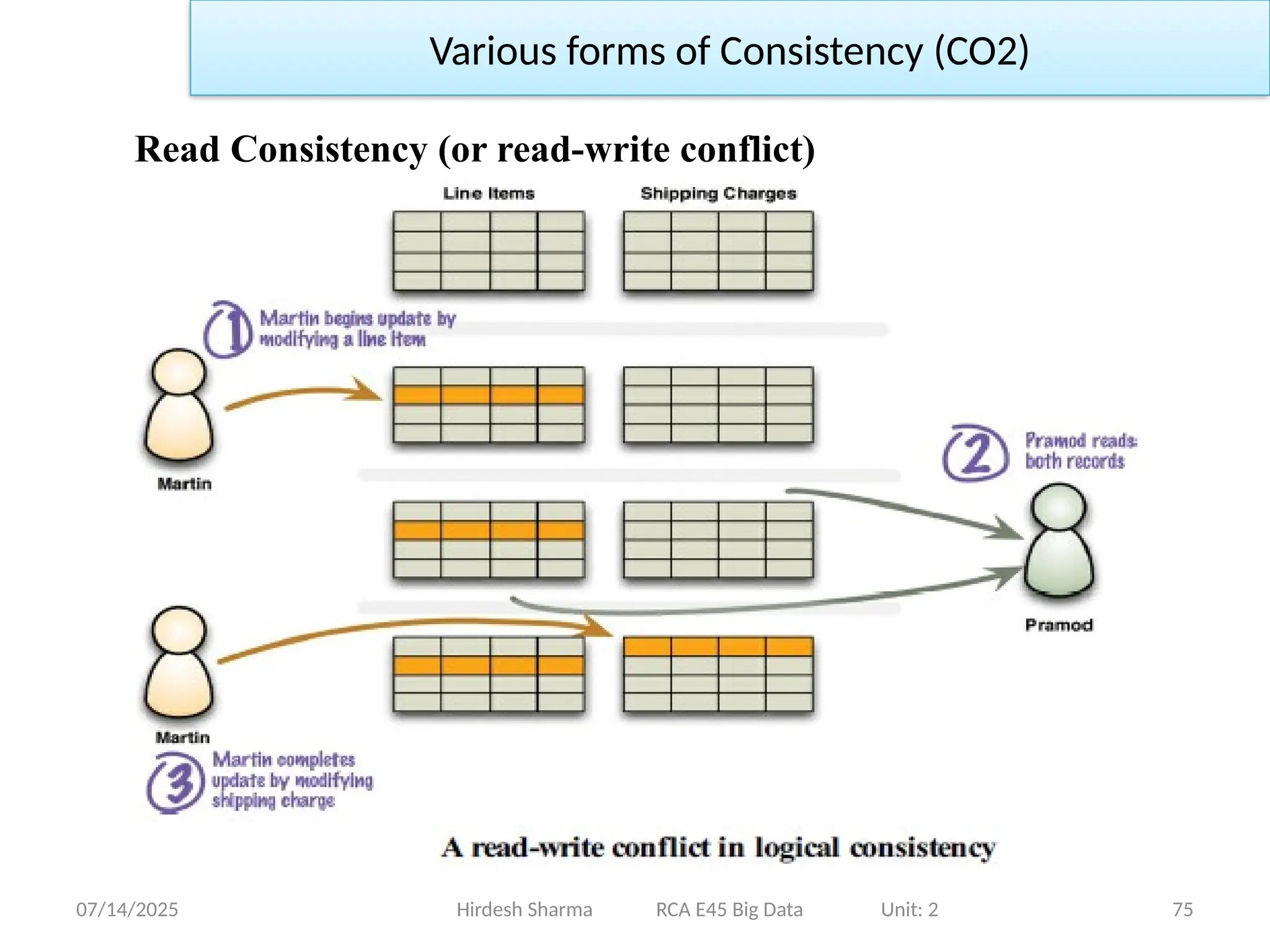
Read Consistency(or read-write conflict)
• Alice and Bob are using Ticketmaster website to book tickets for a
specific show.
• Only one ticket is left for the specific show. Alice signs on to
Ticketmaster first and finds one left, and finds it expensive. Alice
takes time to decide.
Hirdesh Sharma RCA E45 Big Data Unit: 2
Various forms of Consistency (CO2)
75.
07/14/2025 75
Read Consistency(or read-write conflict)
Hirdesh Sharma RCA E45 Big Data Unit: 2
Various forms of Consistency (CO2)
76.
07/14/2025 76
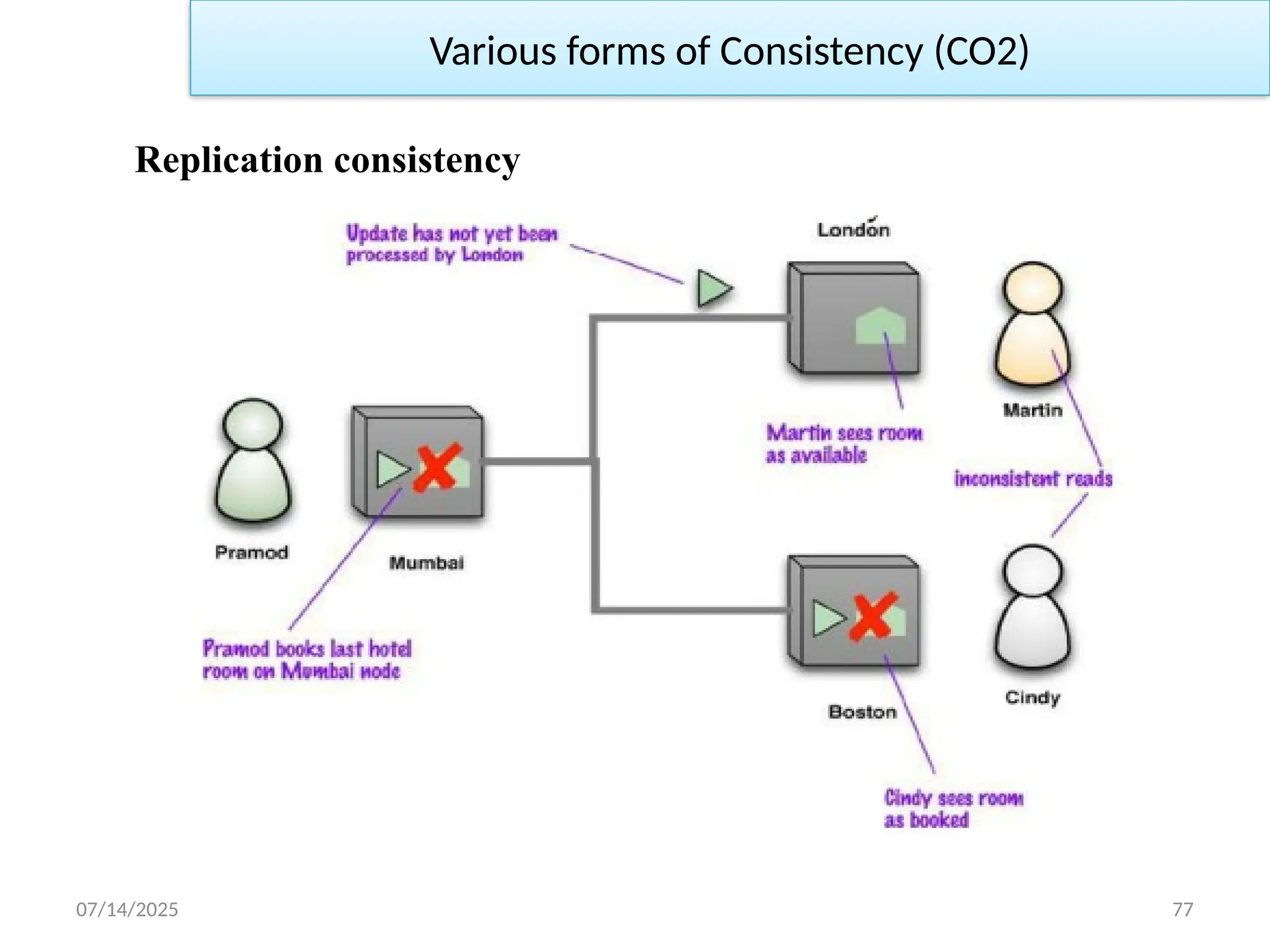
Various formsof Consistency (CO2)
Replication consistency
• Let’s imagine there’s one last hotel room for a desirable event. The
hotel reservation system runs on many nodes.
• This is another inconsistent read—but it’s a breach of a different
form of consistency we call replication consistency: ensuring that
the same data item has the same value when read from different
replicas.
07/14/2025 78
Various formsof Consistency (CO2)
Eventual consistency:
• At any time, nodes may have replication inconsistencies but, if there
are no further updates, eventually all nodes will be updated to the
same value.
• In other words, Eventual consistency is a consistency model used in
nosql database to achieve high availability that informally
guarantees that, if no new updates are made to a given data item,
eventually all accesses to that item will return the last updated value.
79.
07/14/2025 79
In BigData systems (especially distributed databases), a
version stamp is a technique used to track changes and
resolve conflicts in replicated or distributed data.
Version stamp
What Is a Version Stamp?
A version stamp is a marker (often a number, timestamp, or
vector) assigned to a piece of data that changes every time the
data is updated.
Purpose: To know which version of the data is the most recent
and to detect or resolve conflicts when the same data is
updated in different places.
80.
07/14/2025 80
Why IsIt Needed in Big Data?
• In distributed systems, data is stored across multiple
machines (nodes). Updates might happen:
• At different times
• On different nodes
• Simultaneously (leading to conflicts)
A version stamp helps to:
• Identify the latest version
• Ensure eventual consistency
• Support conflict resolution
81.
07/14/2025 Hirdesh SharmaRCA E45 Big Data
Unit: 2
81
Type Description
Timestamps
Attach a system time to each update
(e.g., 2025-07-04T14:00:00Z)
Incrementing Counters
Each update increases a version
number (e.g., v1 → v2 → v3)
Vector Clocks
Advanced version tracking across
multiple nodes to detect concurrent
changes
Common Types of Version Stamps
82.
07/14/2025 82
• ExampleScenario: Version Stamp with
Timestamps
• Let’s say you have a product record in an e-
commerce system stored in three replicas:
• Replica A: Price = $100, Timestamp = 12:00 PM
• Replica B: Price = $90, Timestamp = 12:05 PM
• Replica C: Price = $100, Timestamp = 12:00 PM
• 🔍 The system compares the version stamps
(timestamps) and determines Replica B has
the most recent version.
83.
07/14/2025 83
System HowVersioning Is Used
Apache Cassandra
Uses timestamps to resolve
conflicting writes
Amazon DynamoDB Uses vector clocks internally
HBase
Each cell can store multiple
versions (by timestamp)
MongoDB
Supports write concern and
timestamps for consistency
Used In:
84.
07/14/2025 84
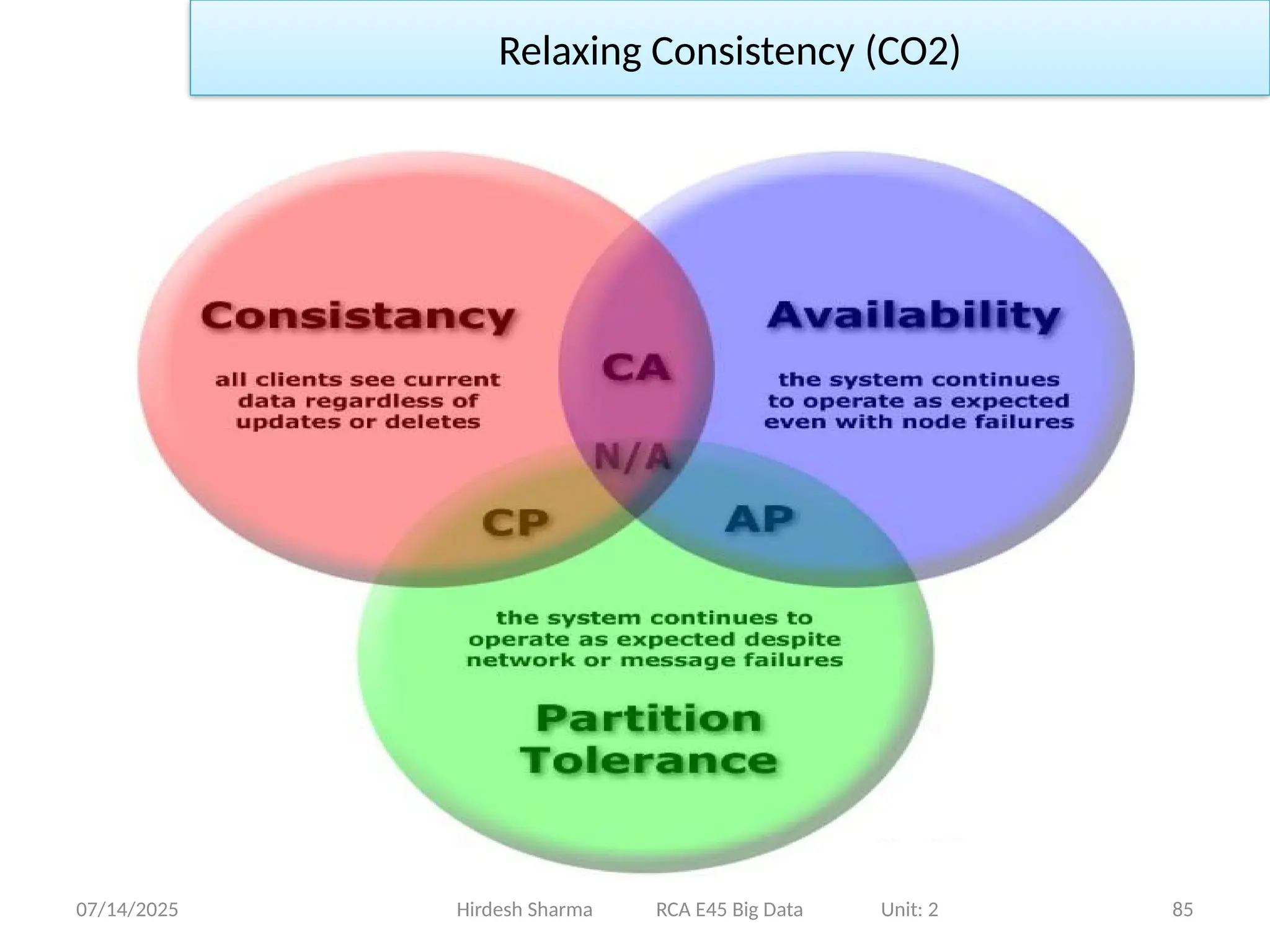
• TheCAP Theorem: The basic statement of the CAP theorem is that,
given the three properties of Consistency, Availability, and Partition
tolerance, you can only get two.
• Consistency Every read receives the most recent write or an
error. All nodes see the same data at the same time.
• Availability
Every request (read or write) receives a response, without
guarantee that it contains the most recent data.
Hirdesh Sharma RCA E45 Big Data Unit: 2
Relaxing Consistency (CO2)
•Partition Tolerance (P):
The system continues to operate despite arbitrary message loss
or failure of part of the system (network partitions).
07/14/2025 86
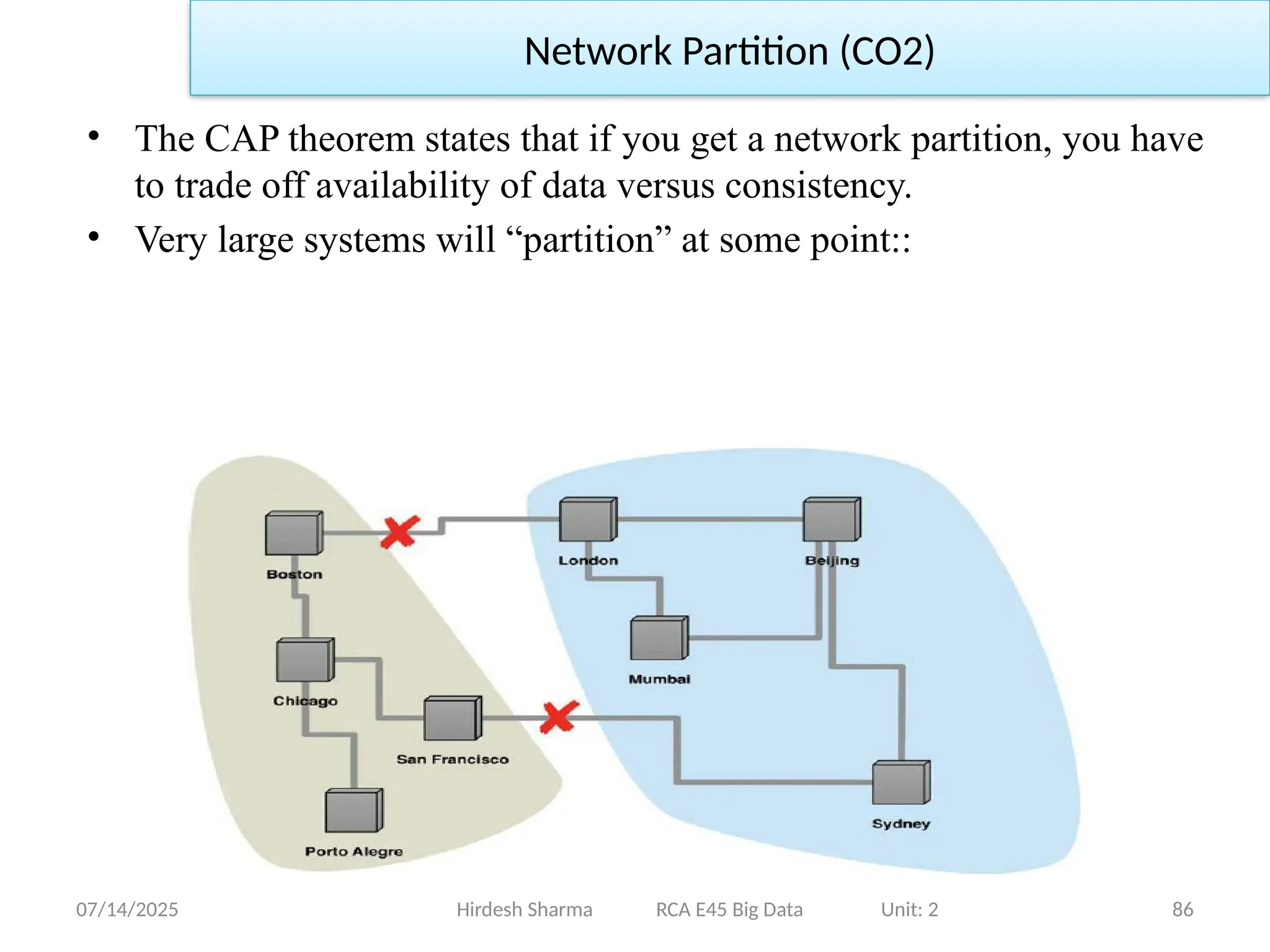
• TheCAP theorem states that if you get a network partition, you have
to trade off availability of data versus consistency.
• Very large systems will “partition” at some point::
Hirdesh Sharma RCA E45 Big Data Unit: 2
Network Partition (CO2)
87.
07/14/2025 87
A single-serversystem is the obvious example of a CA system:
– CA cluster: if a partition occurs, all the nodes would go down
– A failed, unresponsive node doesn’t infer a lack of CAP
availability
• If the system is CA (Consistency + Availability) but NOT Partition
tolerant:
• CA means:
– The system always responds (Availability)
– All nodes have consistent, up-to-date data (Consistency)
• But it cannot tolerate partitions (network failures between nodes).
An example
– Ann is trying to book a room of the Ace Hotel in New York on a
node located in London of a booking system
– Pathin is trying to do the same on a node located in Mumbai
Hirdesh Sharma RCA E45 Big Data Unit: 2
CA System (CO2)
88.
07/14/2025 88
Possible solutions
–CP: Neither user can book any hotel room, sacrificing
availability
– CAP: Designate Mumbai node as the master for Ace hotel
Hirdesh Sharma RCA E45 Big Data Unit: 2
CA System (CO2)
89.
07/14/2025 89
• Itis a way to take a big task and divide it into discrete tasks that can
be done in parallel.
• A common use case for Map/Reduce is in document database .
• A Map Reduce program is composed of a Map() procedure that
performs filtering and sorting and a Reduce() procedure that
performs a summary operation.
• "Map" step
• "Reduce" step
Hirdesh Sharma RCA E45 Big Data Unit: 2
Map Reduce (CO2)
90.
07/14/2025 90
Logical view
•The Map function is applied in parallel to every pair in the input
dataset.
• Map(k1,v1) → list(k2,v2)
• The Reduce function is then applied in parallel to each group, which in
turn produces a collection of values in the same domain:
• Reduce(k2, list (v2)) → list(v3)
• Each Reduce call typically produces either one value v3 or an empty
return
Hirdesh Sharma RCA E45 Big Data Unit: 2
Map Reduce (CO2)
07/14/2025 94
Hirdesh SharmaRCA E45 Big Data Unit: 2
Map Reduce (CO2)
Multistage map-reduce calculations: Let us say that we have a set of
documents and its attributes with the following form:
{
"type": "post",
"name": "Raven's Map/Reduce functionality",
"blog_id": 1342,
"post_id": 29293921,
"tags": ["raven", "nosql"],
"post_content": "<p>...</p>",
"comments": [
{
"source_ip": '124.2.21.2',
"author": "martin",
"text": "excellent blog..."
}]
}
95.
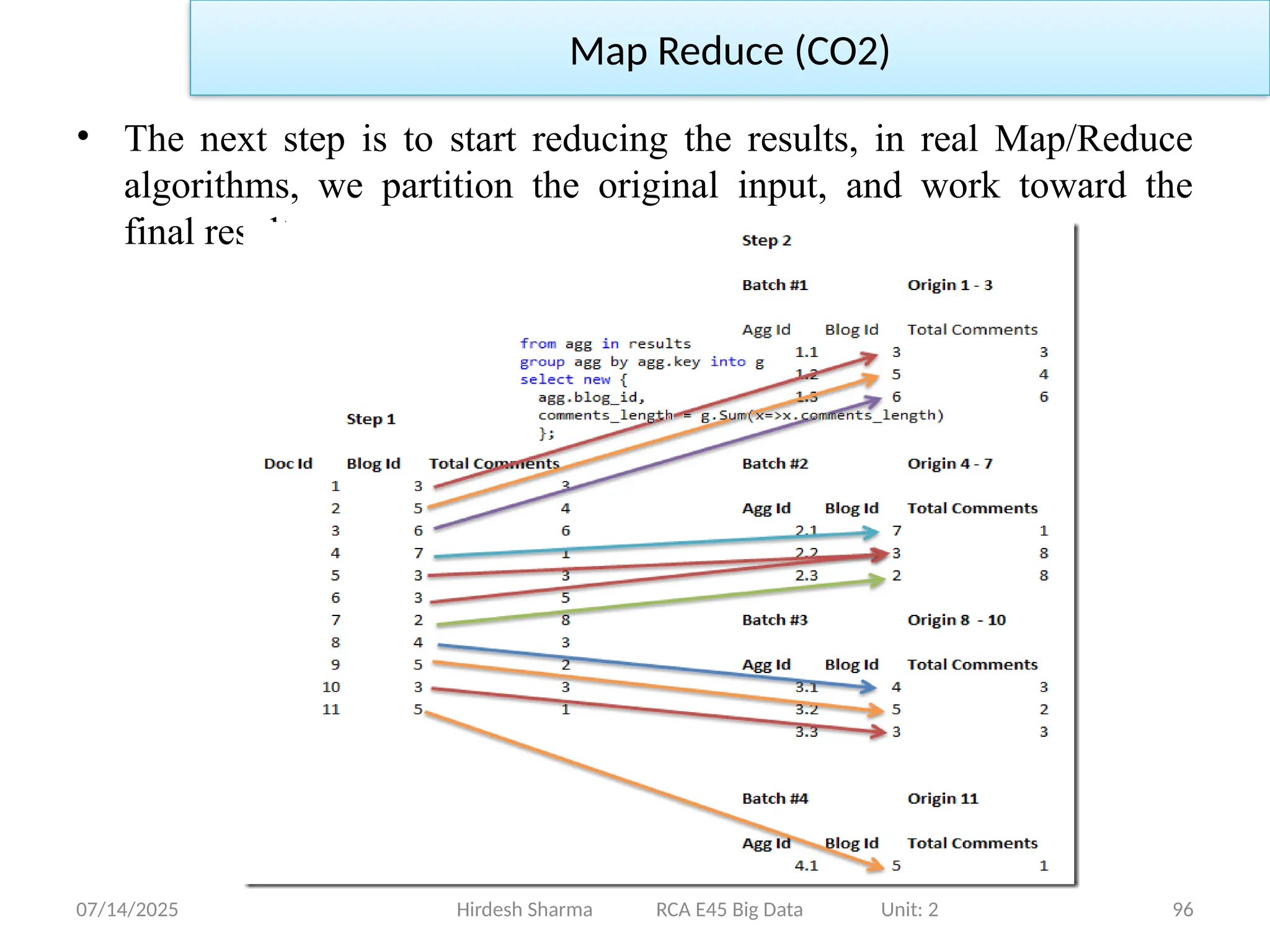
07/14/2025 95
Hirdesh SharmaRCA E45 Big Data Unit: 2
Map Reduce (CO2)
• Let us see how this works, we start by applying the map query to the
set of documents that we have, producing this output:
96.
07/14/2025 96
Hirdesh SharmaRCA E45 Big Data Unit: 2
Map Reduce (CO2)
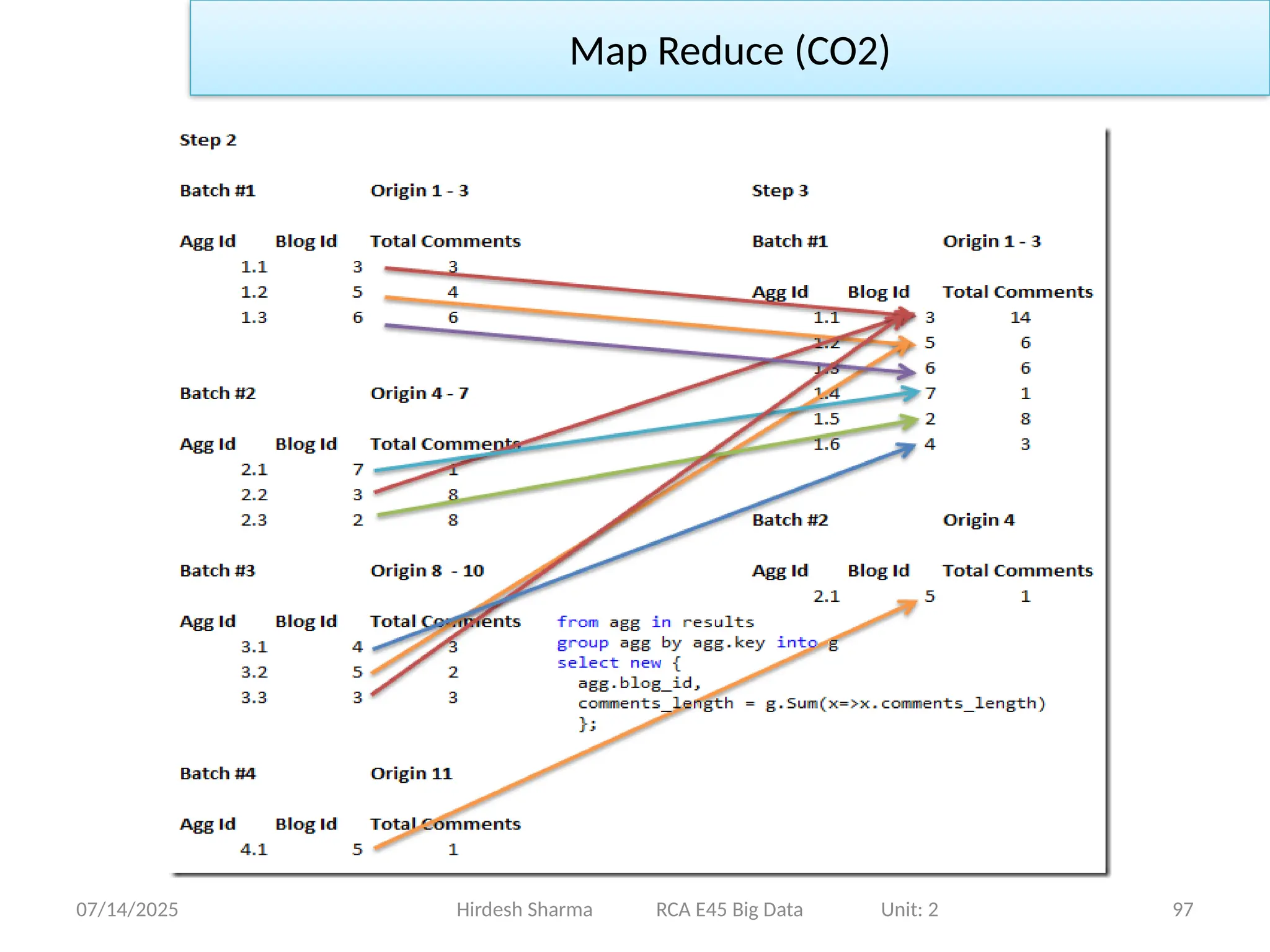
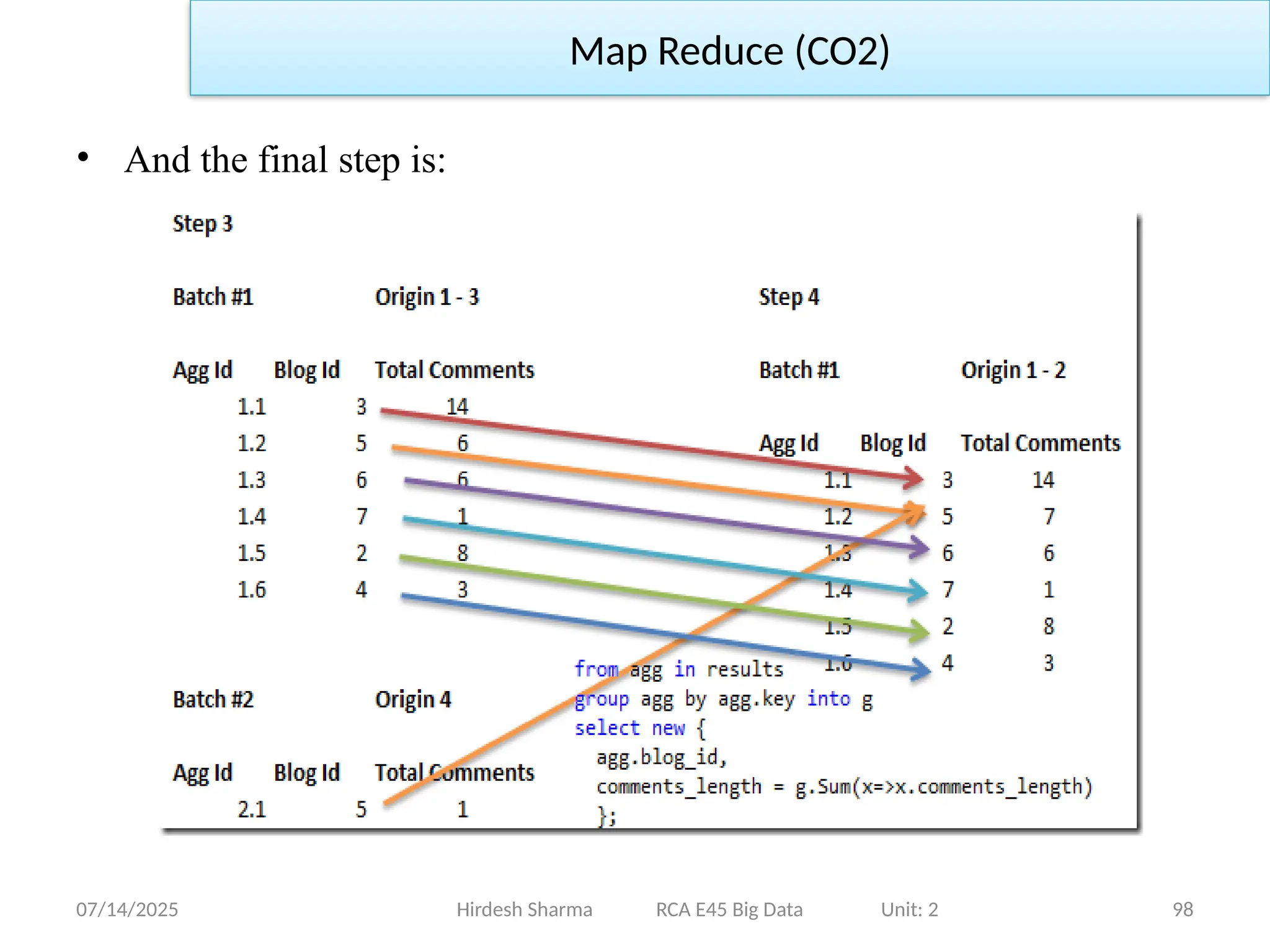
• The next step is to start reducing the results, in real Map/Reduce
algorithms, we partition the original input, and work toward the
final result.
07/14/2025 99
Hirdesh SharmaRCA E45 Big Data Unit: 2
RDBMS compared to MapReduce (CO2)
• MapReduce is a good fit for problems that need to analyze the
whole dataset, in a batch fashion, particularly for ad hoc analysis.
• MapReduce suits applications where the data is written once, and
read many times, whereas a relational database is good for datasets
that are continually updated.
07/14/2025 101
Hirdesh SharmaRCA E45 Big Data Unit: 2
Portioning and Combining (CO2)
• In the simplest form, we think of a map-reduce job as having a
single reduce function.
• The outputs from all the map tasks running on the various nodes are
concatenated together and sent into the reduce.
102.
07/14/2025 102
Hirdesh SharmaRCA E45 Big Data Unit: 2
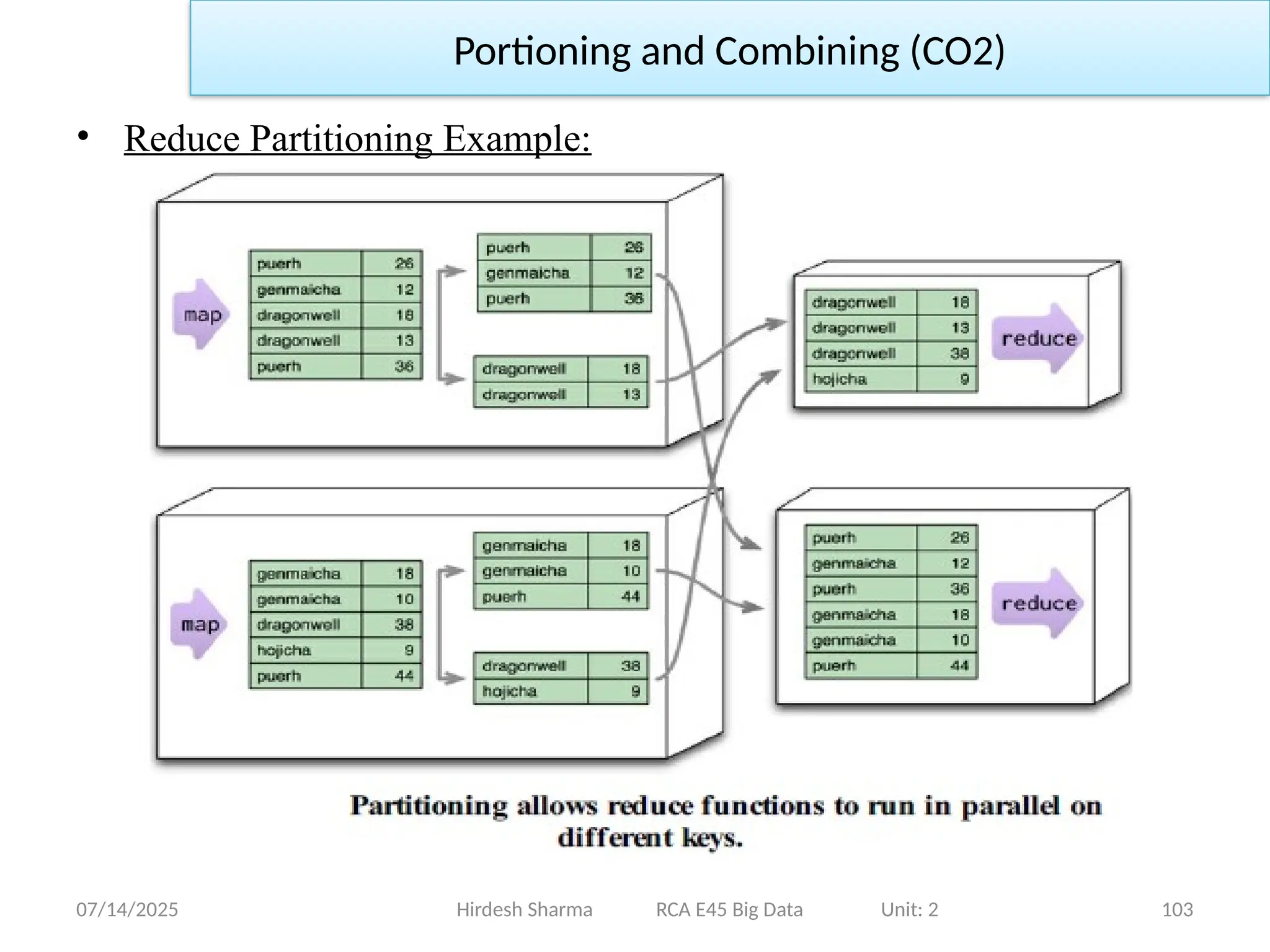
Portioning and Combining (CO2)
• To take advantage of this, the results of the mapper are divided up
based the key on each processing node.
• Typically, multiple keys are grouped together into partitions. The
framework then takes the data from all the nodes for one partition,
combines it into a single group for that partition, and sends it off to a
reducer.
07/14/2025 105
Hirdesh SharmaRCA E45 Big Data Unit: 2
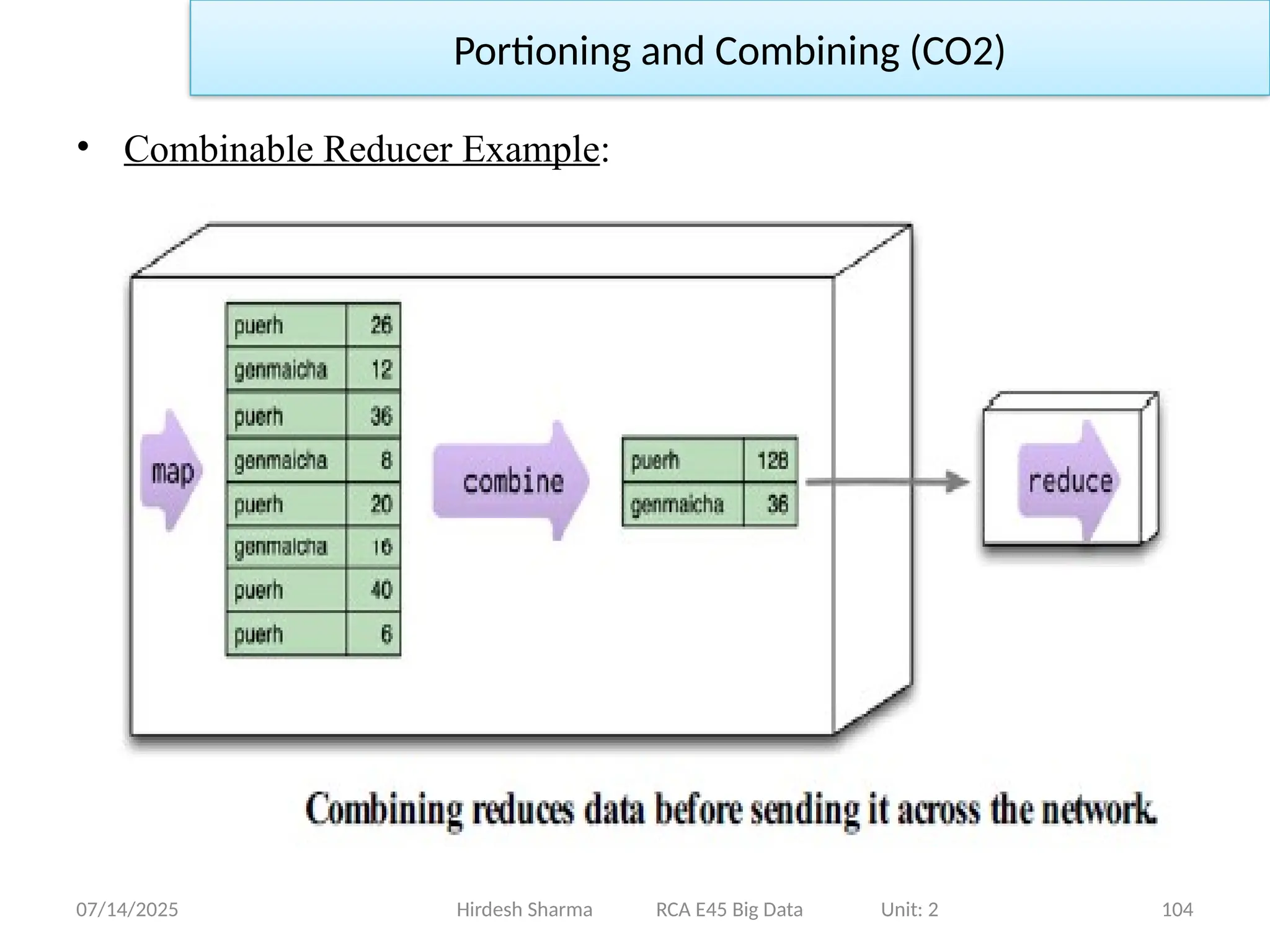
Portioning and Combining (CO2)
• Combinable Reducer:
A combiner function is, in essence, a reducer function—indeed, in
many cases the same function can be used for combining as the final
reduction. The reduce function needs a special shape for this to
work: Its output must match its input. We call such a function a
combinable reducer.
106.
07/14/2025 106
• Mapperand Reducer implementations can use the ________ to
report progress or just indicate that they are alive.
a) Partitioner
b) OutputCollector
c) Reporter
d) All of the mentioned
• _________ is the primary interface for a user to describe a
MapReduce job to the Hadoop framework for execution.
a) Map Parameters
b) JobConf
c) MemoryConf
d) None of the mentioned
Hirdesh Sharma RCA E45 Big Data Unit: 2
Daily Quiz
107.
07/14/2025 107
• Theconsistency property ensures that any transaction will bring the
database from one valid state to another.
• Relational databases has strong consistency whereas NoSQL
systems hass mostly eventual consistency.
Hirdesh Sharma RCA E45 Big Data Unit: 2
Recap
108.
07/14/2025 108
• https://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html
•https://www.tutorialspoint.com/hadoop/hadoop_mapreduce
.htm
• https://www.sanfoundry.com/mapreduce-questions-answers/
Hirdesh Sharma RCA E45 Big Data Unit: 2
Faculty Video Links, Youtube & NPTEL Video Links and Online
Courses Details
109.
07/14/2025 109
Q:1 Explainthe concept of NoSQL in Big Data.
Q:2 Give the difference between Relation database and NoSQL
database.
Q:3 Explain various aggregate data modes:
Key value storage
Document Storage
Graph Storage
Colum value Storage
Q:4 Explain the Schema less database. Also explain the properties
of schema less database.
Hirdesh Sharma RCA E45 Big Data Unit: 2
Weekly Assignment 1
110.
07/14/2025 110
Q:1 Writea short note on following terms:
–Materialized Views
–Distribution Models
–Sharing
Q:2 Explain the following terms:
–Version Stamps
–Map Reduce Calculations
–Portioning and Combining
–Consistency
Q:3 Explain Master Slave Replication with the help of suitable
example.
Q:4 Explain Peer to peer Replication with the help of suitable
example.
Hirdesh Sharma RCA E45 Big Data Unit: 2
Weekly Assignment 2
111.
07/14/2025 111
• Pointout the correct statement.
a) MapReduce tries to place the data and the compute as close as
possible
b) Map Task in MapReduce is performed using the Mapper() function
c) Reduce Task in MapReduce is performed using the Map() function
d) All of the mentioned
• Point out the correct statement.
a) Hadoop is an ideal environment for extracting and transforming
small volumes of data
b) Hadoop stores data in HDFS and supports data
compression/decompression
c) The Giraph framework is less useful than a MapReduce job to solve
graph and machine learning
d) None of the mentioned
Hirdesh Sharma RCA E45 Big Data Unit: 2
MCQ s
112.
07/14/2025 112
• Whatlicense is Hadoop distributed under?
a) Apache License 2.0
b) Mozilla Public License
c) Shareware
d) Commercial
• Which of the following genres does Hadoop produce?
a) Distributed file system
b) JAX-RS
c) Java Message Service
d) Relational Database Management System
Hirdesh Sharma RCA E45 Big Data Unit: 2
MCQ s
07/14/2025 117
Q:1 Writea short note on following terms:
–Materialized Views
–Distribution Models
–Sharing
Q:2 Explain the following terms:
–Version Stamps
–Map Reduce Calculations
–Portioning and Combining
–Consistency
Q:3 Explain Master Slave Replication with the help of suitable
example.
Q:4 Explain Peer to peer Replication with the help of suitable
example.
Hirdesh Sharma RCA E45 Big Data Unit: 2
Expected Questions for University Exam
118.
07/14/2025 118
Q:5 Explainthe concept of NoSQL in Big Data.
Q:6 Give the difference between Relation database and NoSQL
database.
Q:7 Explain various aggregate data modes:
Key value storage
Document Storage
Graph Storage
Colum value Storage
Q:8 Explain the Schema less database. Also explain the properties
of schema less database.
Hirdesh Sharma RCA E45 Big Data Unit: 2
Expected Questions for University Exam
119.
07/14/2025 119
• NoSQL database, also called Not Only SQL, is an approach to data
management and database design that's useful for very large sets of
distributed data.
• SQL databases have predefined schema whereas No SQL databases
have dynamic schema for unstructured data.
• There are four general types of No SQL databases, each with their
own specific attributes:
–Key value storage
–Document Storage
–Graph Storage
–Colum value Storage
Hirdesh Sharma RCA E45 Big Data Unit: 2
Summary
120.
07/14/2025 120
Hirdesh SharmaRCA E45 Big Data Unit: 2
References
1. Michael Minelli, Michelle Chambers, and Ambiga Dhiraj, "Big Data, Big
Analytics: Emerging Business Intelligence and Analytic Trends for Today's
Businesses", Wiley, 2013.
2. P. J. Sadalage and M. Fowler, "NoSQL Distilled: A Brief Guide to the Emerging
World of
3. Polyglot Persistence", Addison-Wesley Professional, 2012.
4. Tom White, "Hadoop: The Definitive Guide", Third Edition, O'Reilley, 2012.
5. Eric Sammer, "Hadoop Operations", O'Reilley, 2012.
6. E. Capriolo, D. Wampler, and J. Rutherglen, "Programming Hive", O'Reilley,
2012.
7. Lars George, "HBase: The Definitive Guide", O'Reilley, 2011.
8. Eben Hewitt, "Cassandra: The Definitive Guide", O'Reilley, 2010.
9. Alan Gates, "Programming Pig", O'Reilley, 2011.
Thank You




























![07/14/2025 41
Again, we have some sample data, which we’ll show in JSON
format as that’s a common representation for data in NoSQL.
// in customers
{ "
id":1,
"name":"Martin",
"billingAddress":[{"city":"Chicago"}]
}
// in orders
{ "
id":99,
"customerId":1,
"orderItems":[
Hirdesh Sharma RCA E45 Big Data Unit: 2
Aggregate Data Model in NoSQL (CO2)](https://image.slidesharecdn.com/519707611-unit2-bd-250714095111-ed1760cd/75/NOSQL-IN-BIGDATA-FOR-PG-STUDENTS-FOR-COL-41-2048.jpg)
![07/14/2025 42
{
"productId":27,
"price": 32.45,
"productName": "NoSQL Distilled"
}
],
"shippingAddress":[{"city":"Chicago"}]
"orderPayment":[
{
"ccinfo":"1000-1000-1000-1000",
"txnId":"abelif879rft",
"billingAddress": {"city": "Chicago"}
}
],
}
Aggregate Data Model in NoSQL (CO2)](https://image.slidesharecdn.com/519707611-unit2-bd-250714095111-ed1760cd/75/NOSQL-IN-BIGDATA-FOR-PG-STUDENTS-FOR-COL-42-2048.jpg)






![07/14/2025 51
Example:
You store user data in a schemaless database like MongoDB:
json
// In the database { "username": "sana123", "email":
"sana@example.com", "age": 25 }
In your application code:
python
def send_email(user):
if "@example.com" in user["email"]:
email_user(user["email"])
This code assumes:
•user["email"] exists
•It’s a string
•It contains an email
If email is missing or of the wrong type, the code may crash.](https://image.slidesharecdn.com/519707611-unit2-bd-250714095111-ed1760cd/75/NOSQL-IN-BIGDATA-FOR-PG-STUDENTS-FOR-COL-51-2048.jpg)


































![07/14/2025 94
Hirdesh Sharma RCA E45 Big Data Unit: 2
Map Reduce (CO2)
Multistage map-reduce calculations: Let us say that we have a set of
documents and its attributes with the following form:
{
"type": "post",
"name": "Raven's Map/Reduce functionality",
"blog_id": 1342,
"post_id": 29293921,
"tags": ["raven", "nosql"],
"post_content": "<p>...</p>",
"comments": [
{
"source_ip": '124.2.21.2',
"author": "martin",
"text": "excellent blog..."
}]
}](https://image.slidesharecdn.com/519707611-unit2-bd-250714095111-ed1760cd/75/NOSQL-IN-BIGDATA-FOR-PG-STUDENTS-FOR-COL-94-2048.jpg)


















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)