Download as ODP, PPTX















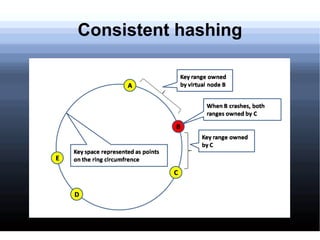
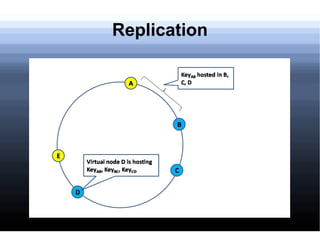
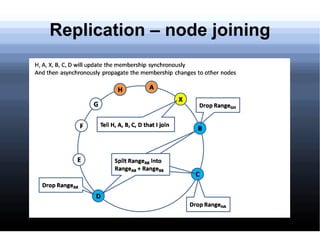
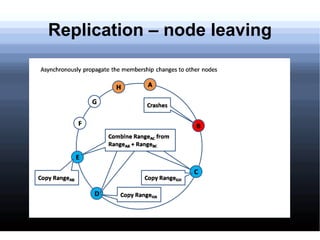



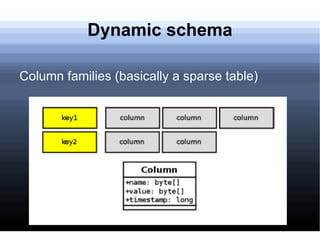
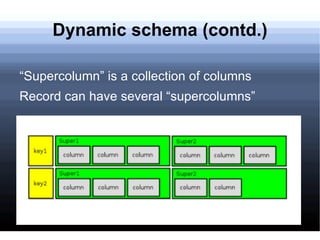

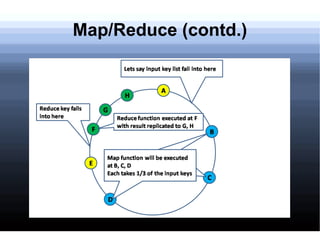
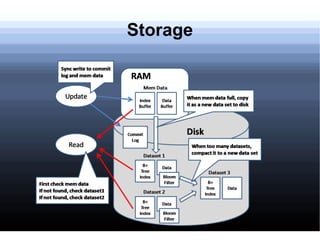











Non-relational databases were developed to address the problems that traditional relational databases have in handling web-scale applications with massive amounts of data and users. They sacrifice consistency to gain availability and partition tolerance. Examples include BigTable, HBase, Dynamo, and Cassandra. They provide benefits like massive scalability, high availability, and elasticity through techniques like consistent hashing, replication, and MapReduce processing.















































































