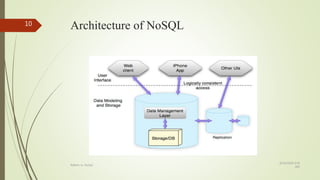
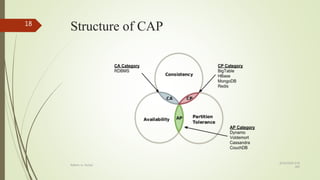
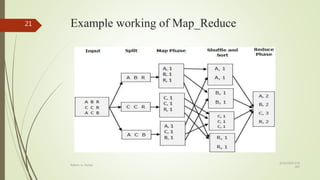
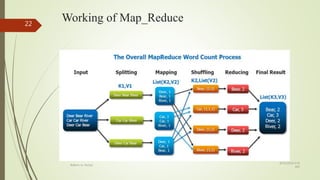
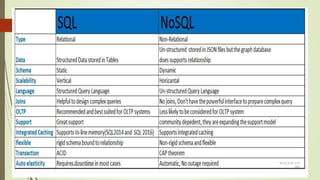
This document compares RDBMS and NoSQL databases. RDBMS uses SQL and follows ACID properties, storing data in tables and columns. NoSQL databases are non-relational, distributed, and horizontally scalable. Common NoSQL databases include MongoDB, Cassandra, and HBase. NoSQL databases sacrifice consistency for availability and partition tolerance as described by CAP theorem.