Download as PDF, PPTX







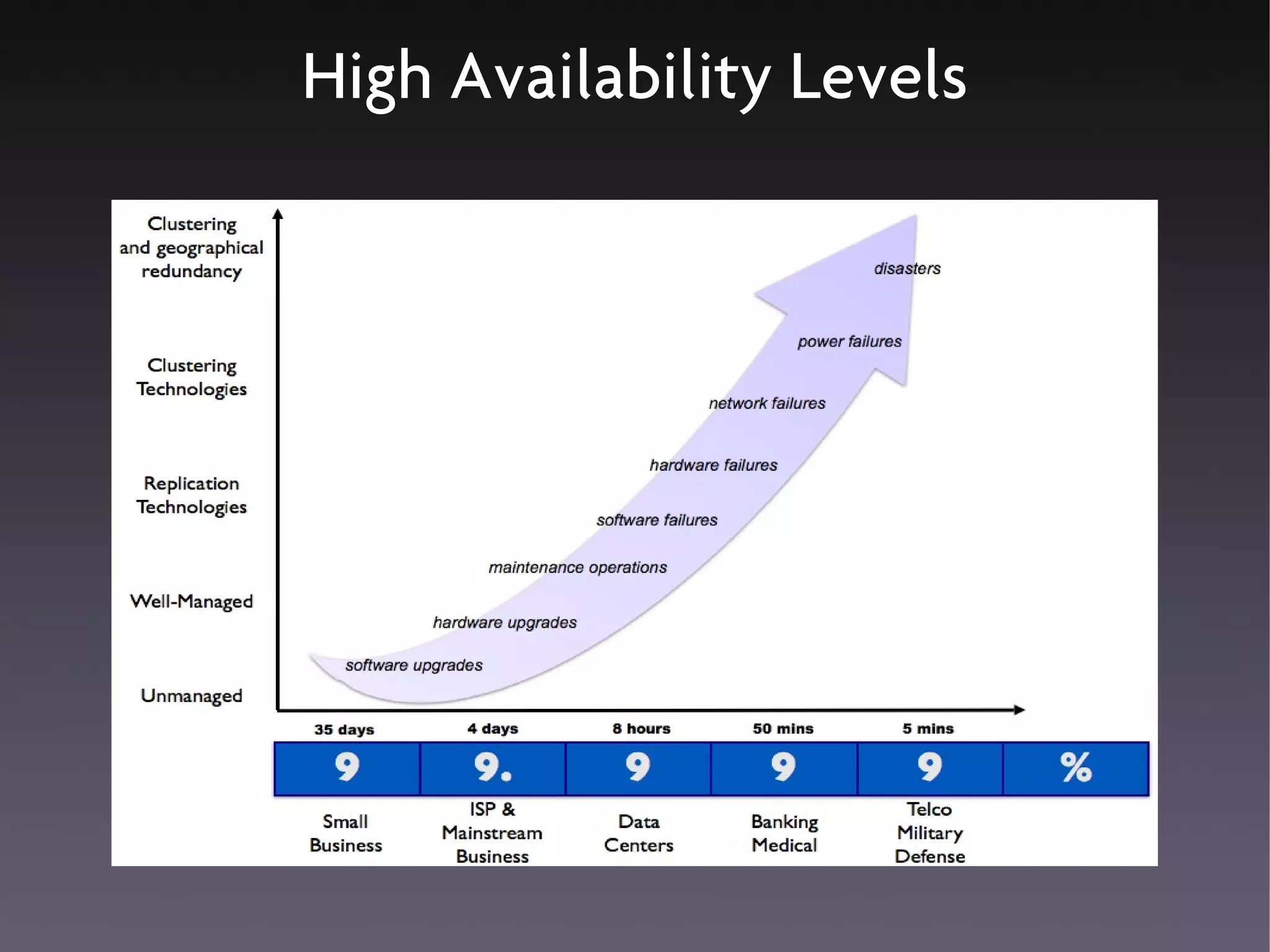






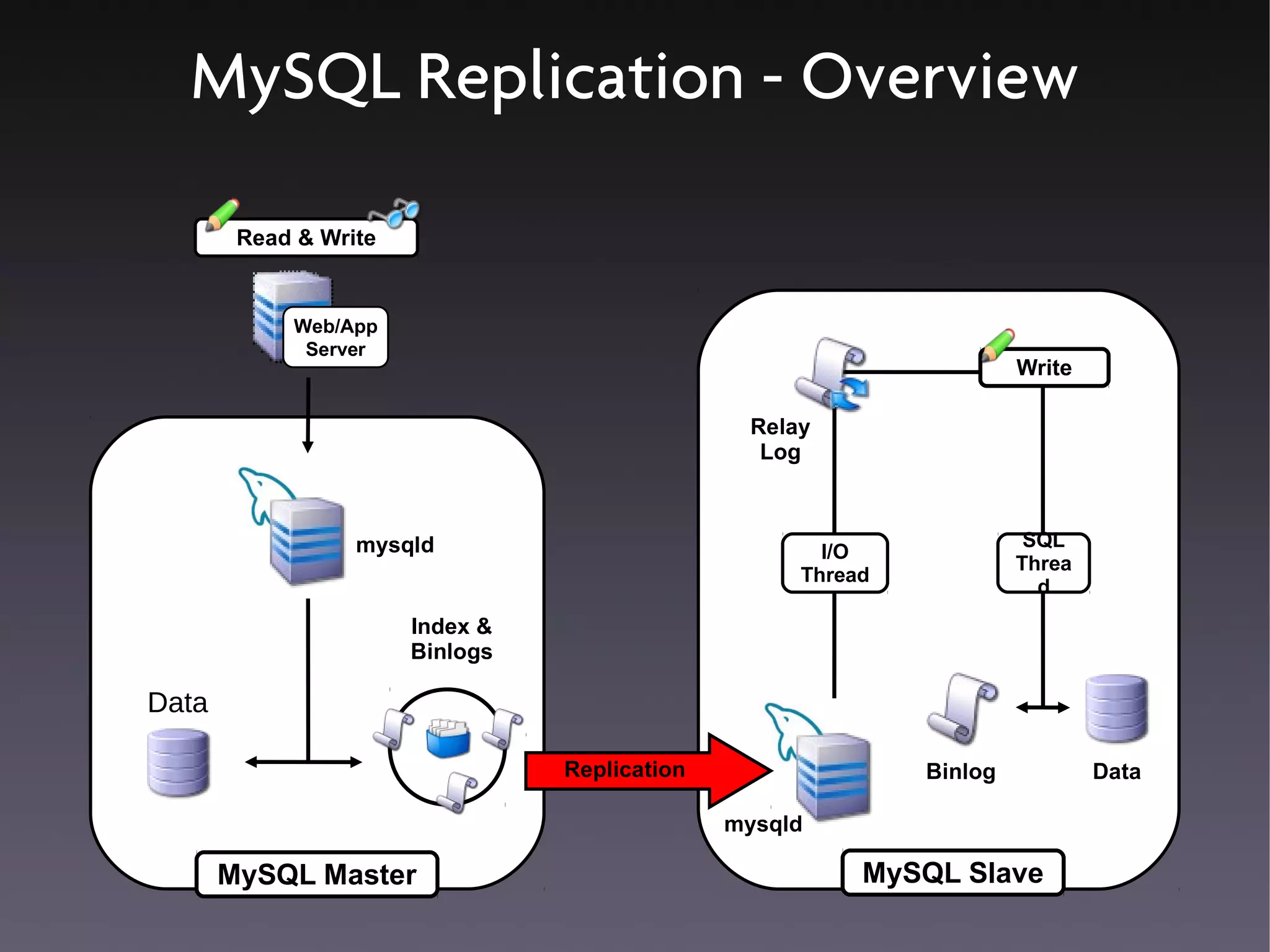


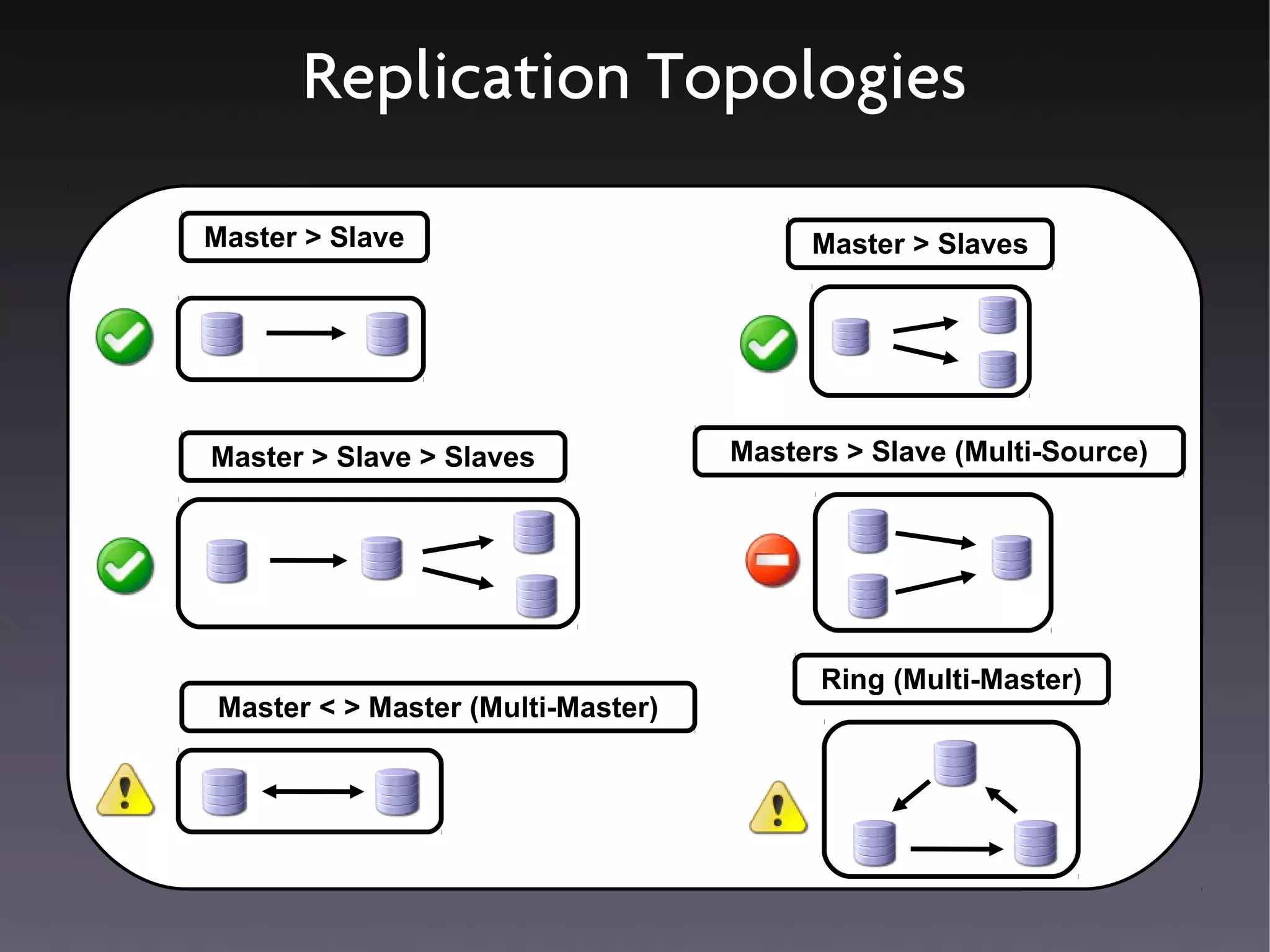






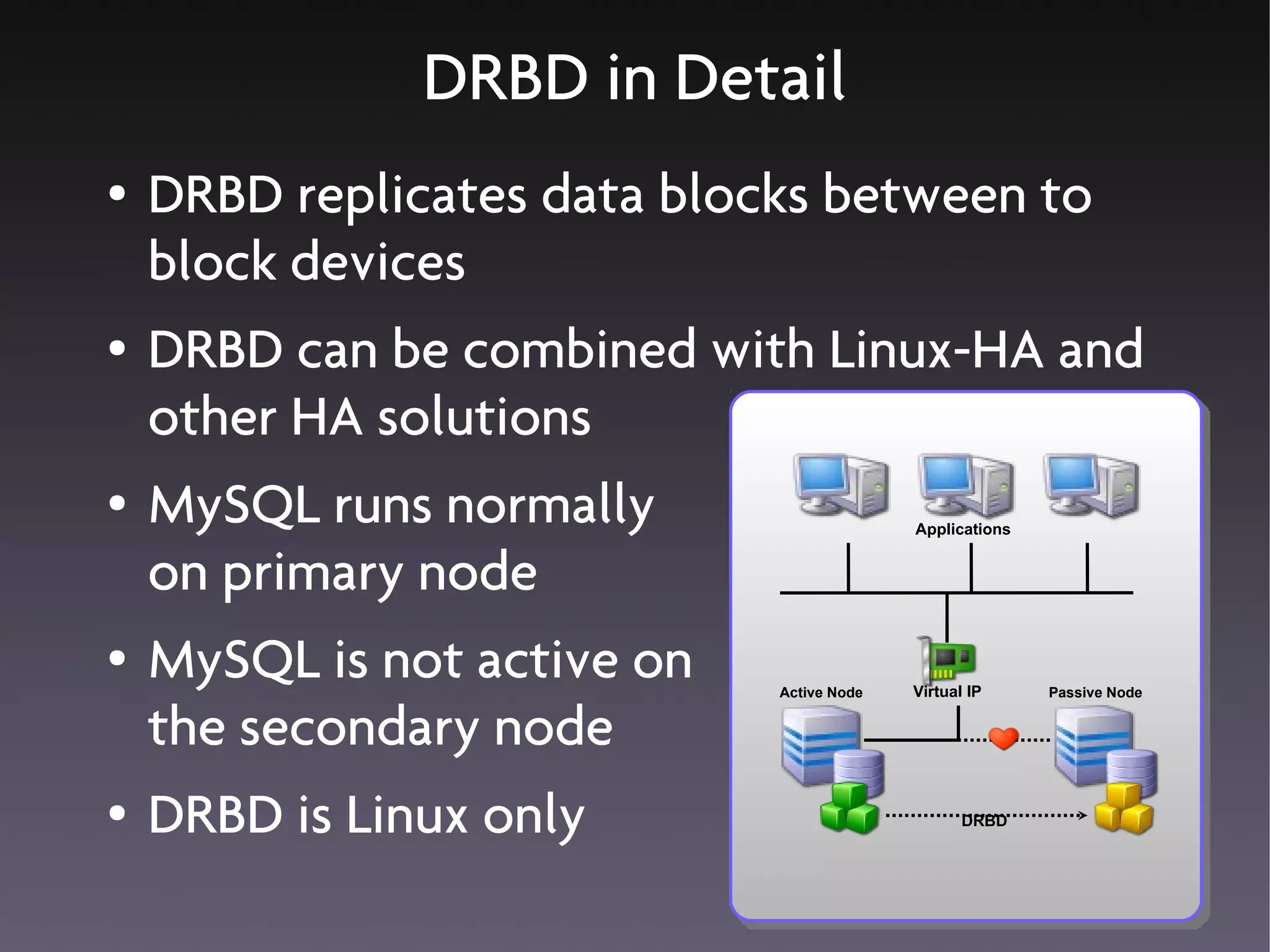
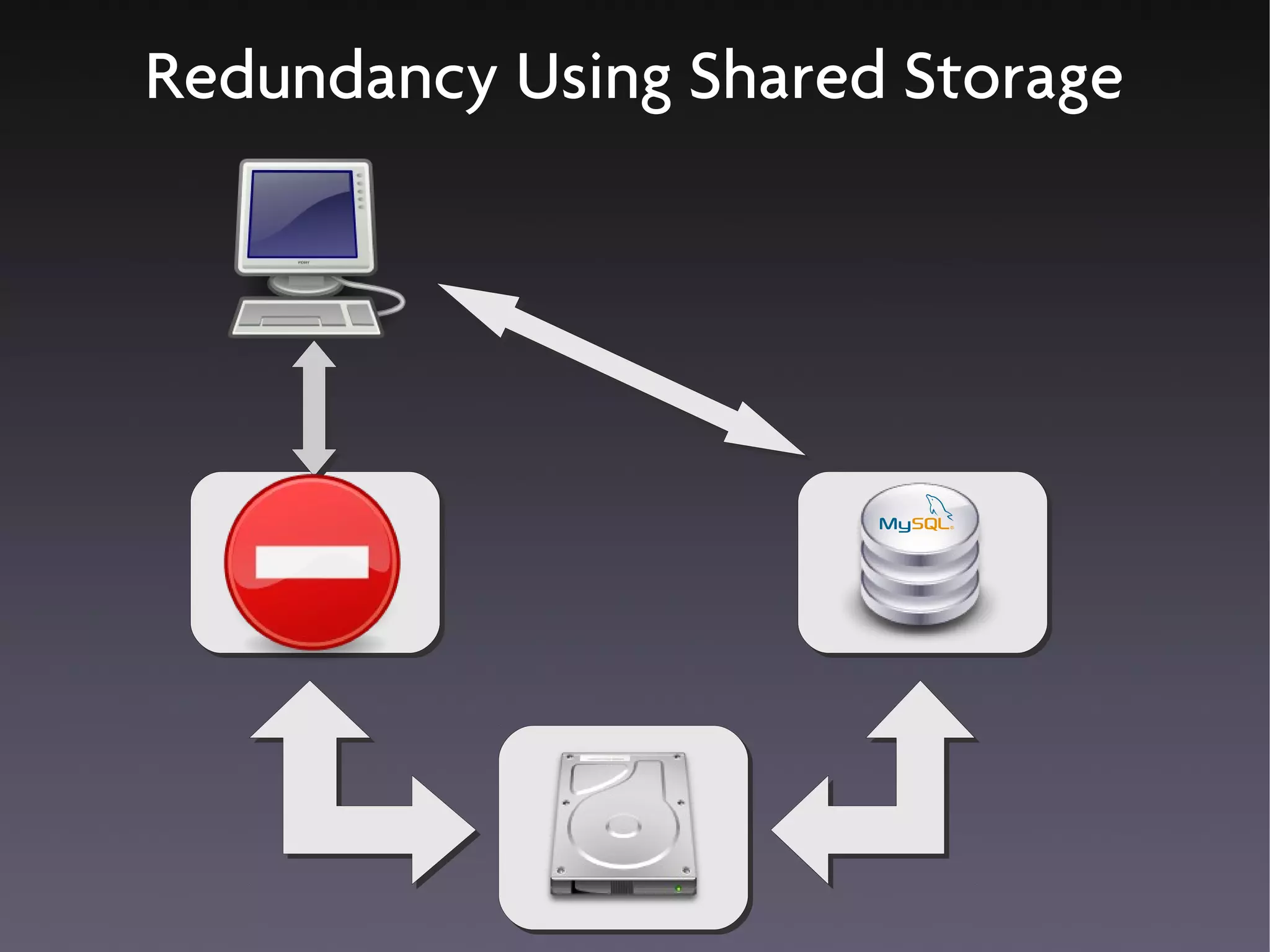

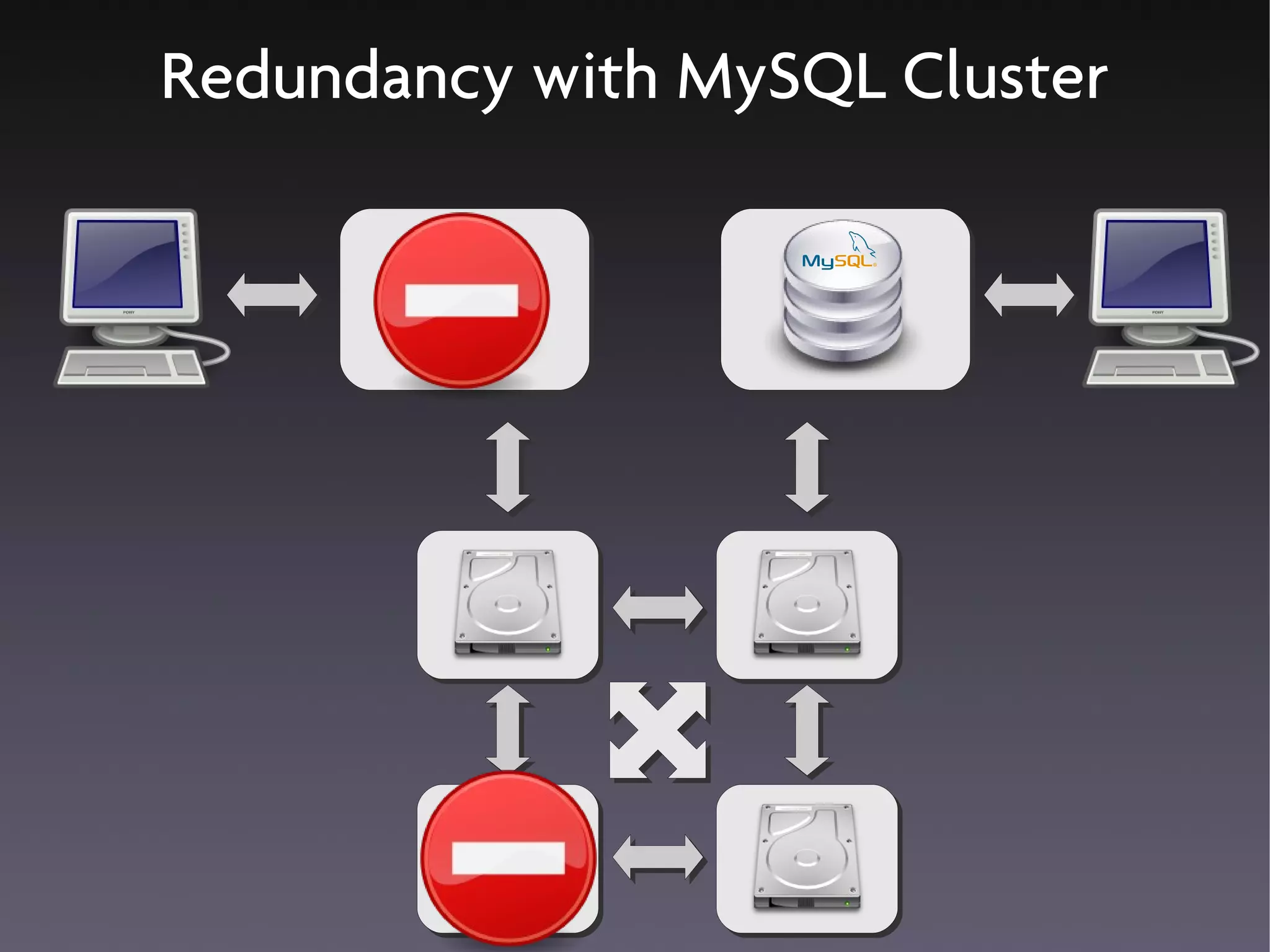


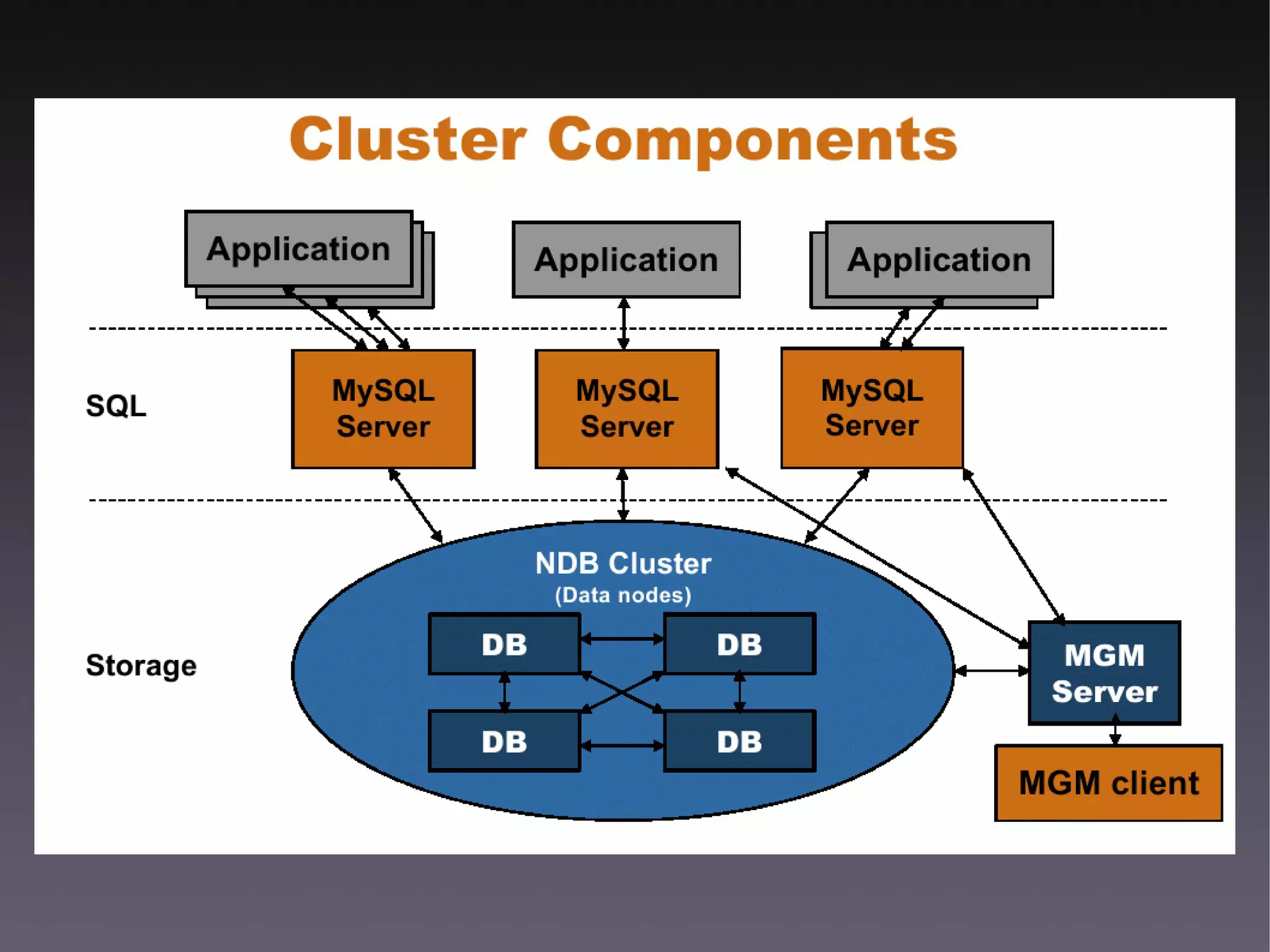

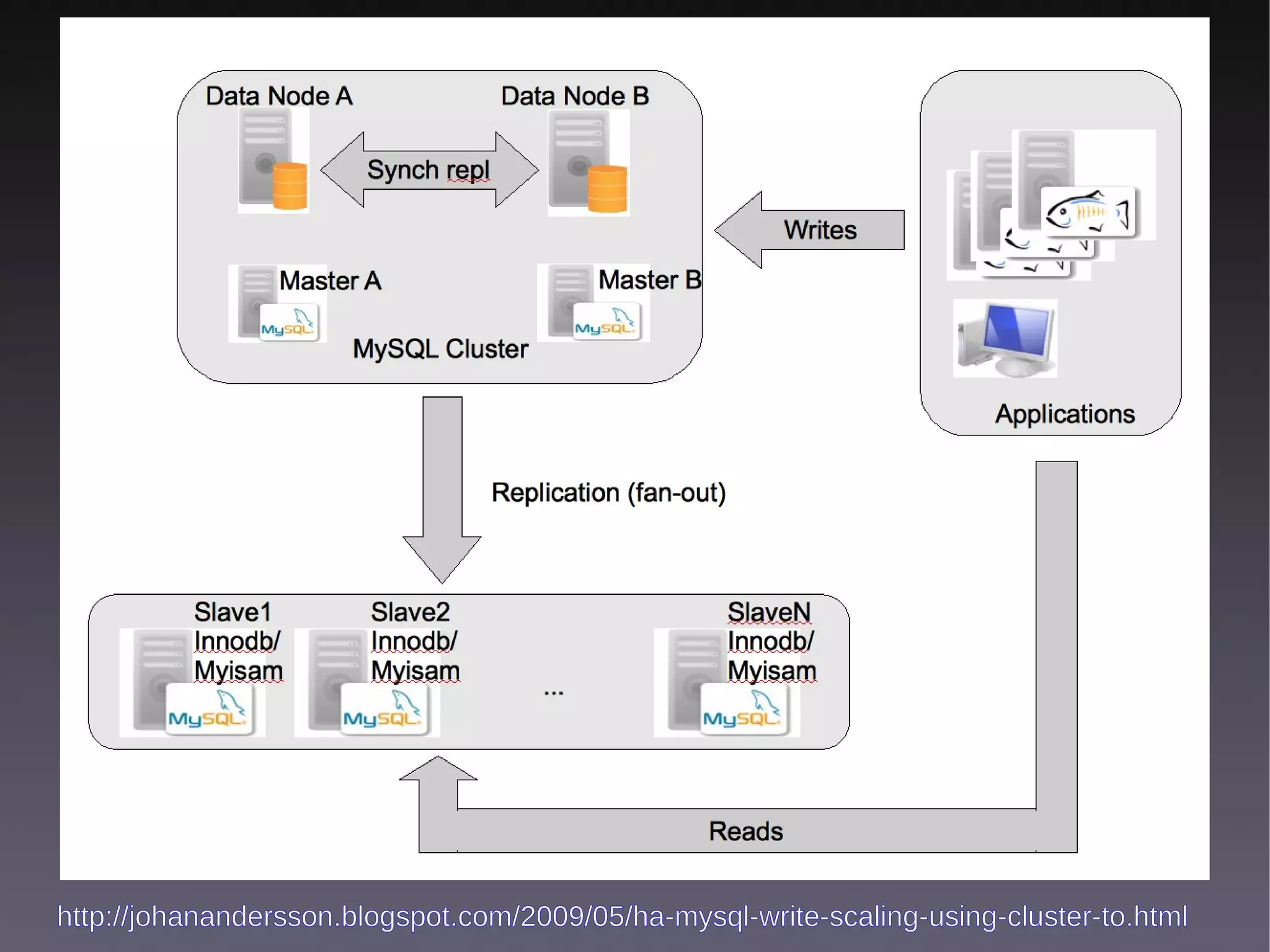








This document discusses various high availability solutions for MySQL databases. It begins with an overview of high availability concepts and considerations. It then covers MySQL replication, disk replication using DRBD, MySQL Cluster, and other tools like Pacemaker, Galera replication, MMM, Tungsten Replicator, Red Hat Cluster Suite, Solaris Cluster, and Flipper. The document provides details on how each solution works and its advantages and disadvantages for providing redundancy and high availability for MySQL databases.

























































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)

















