Download to read offline



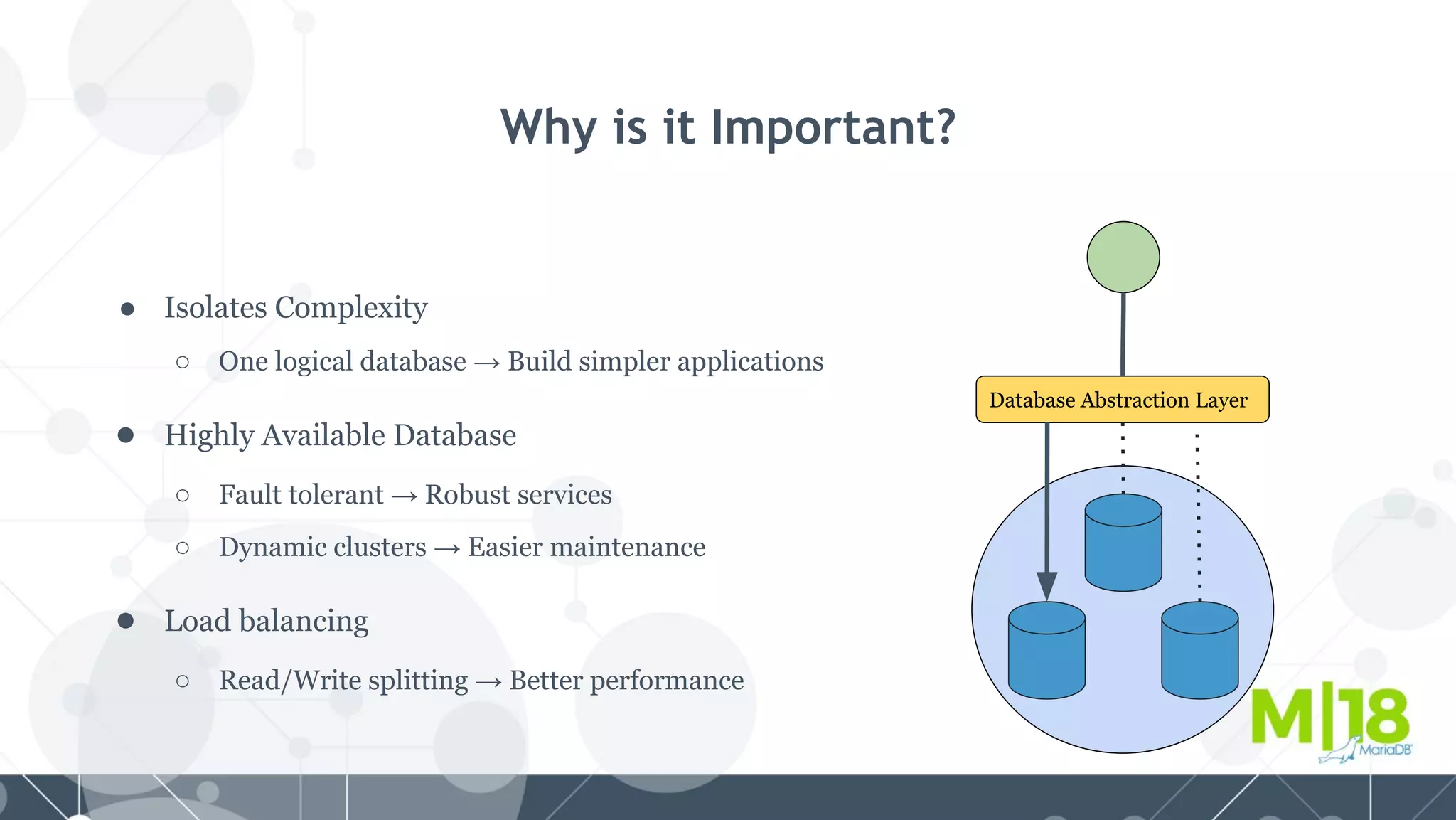
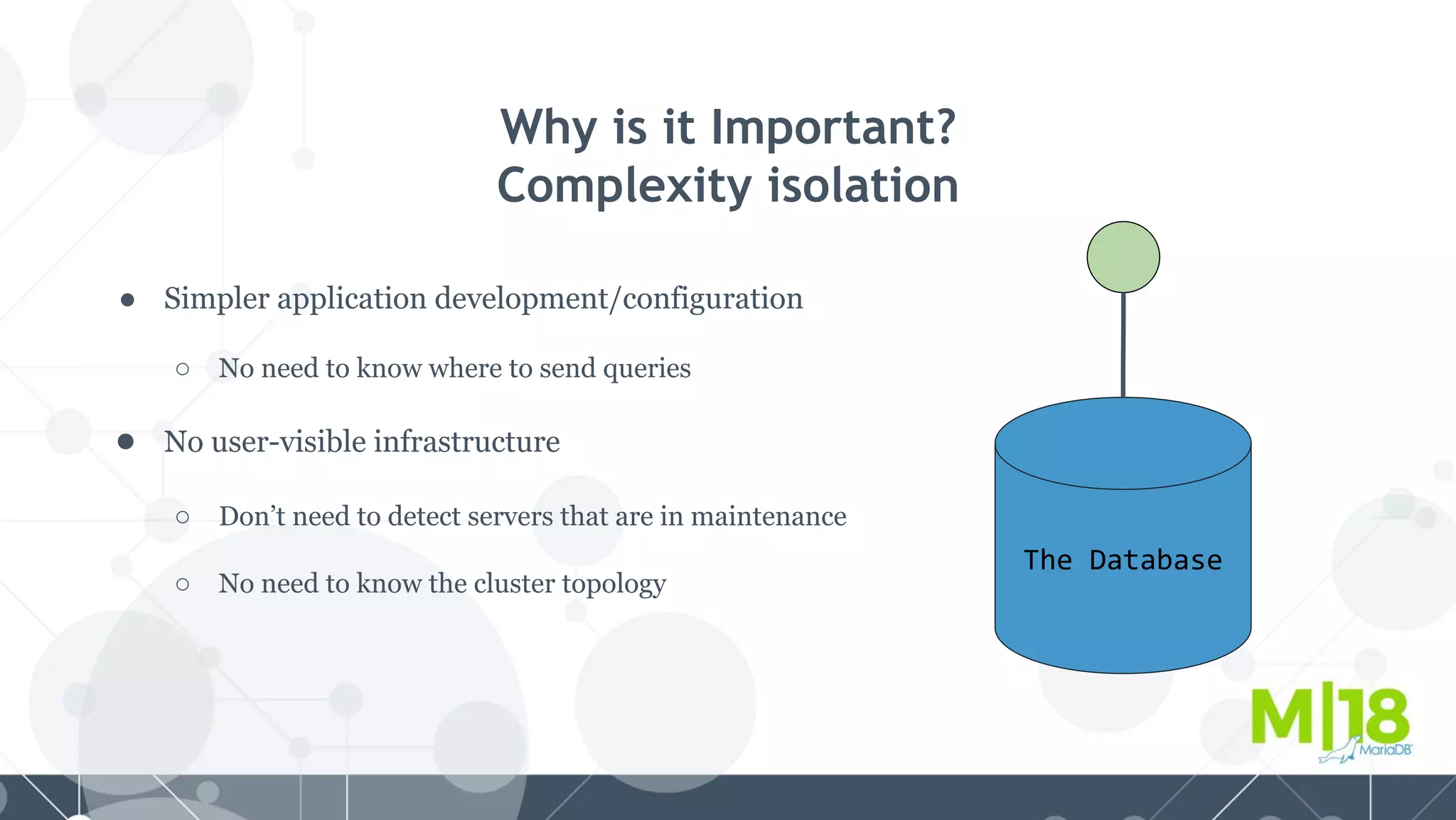
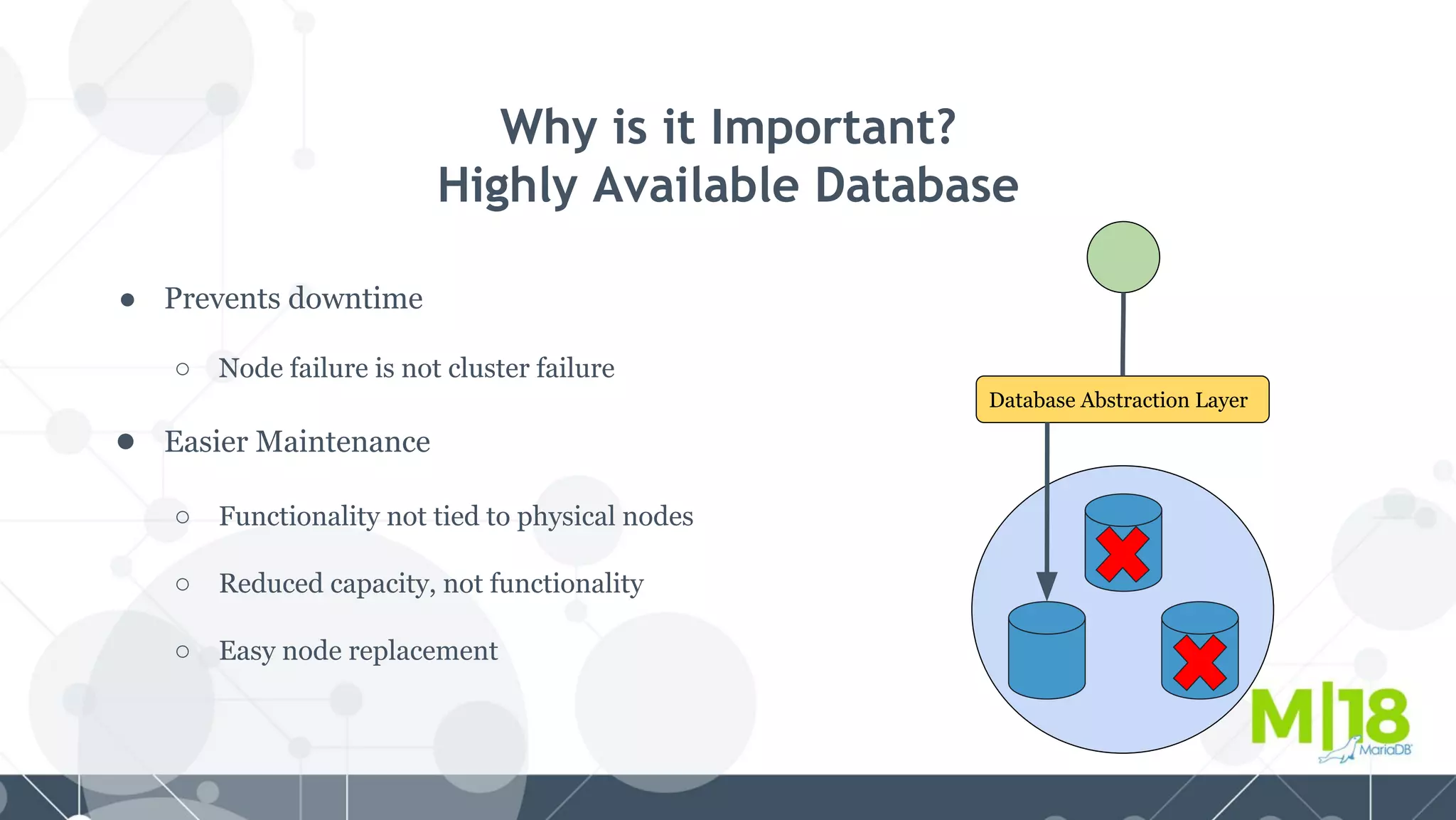
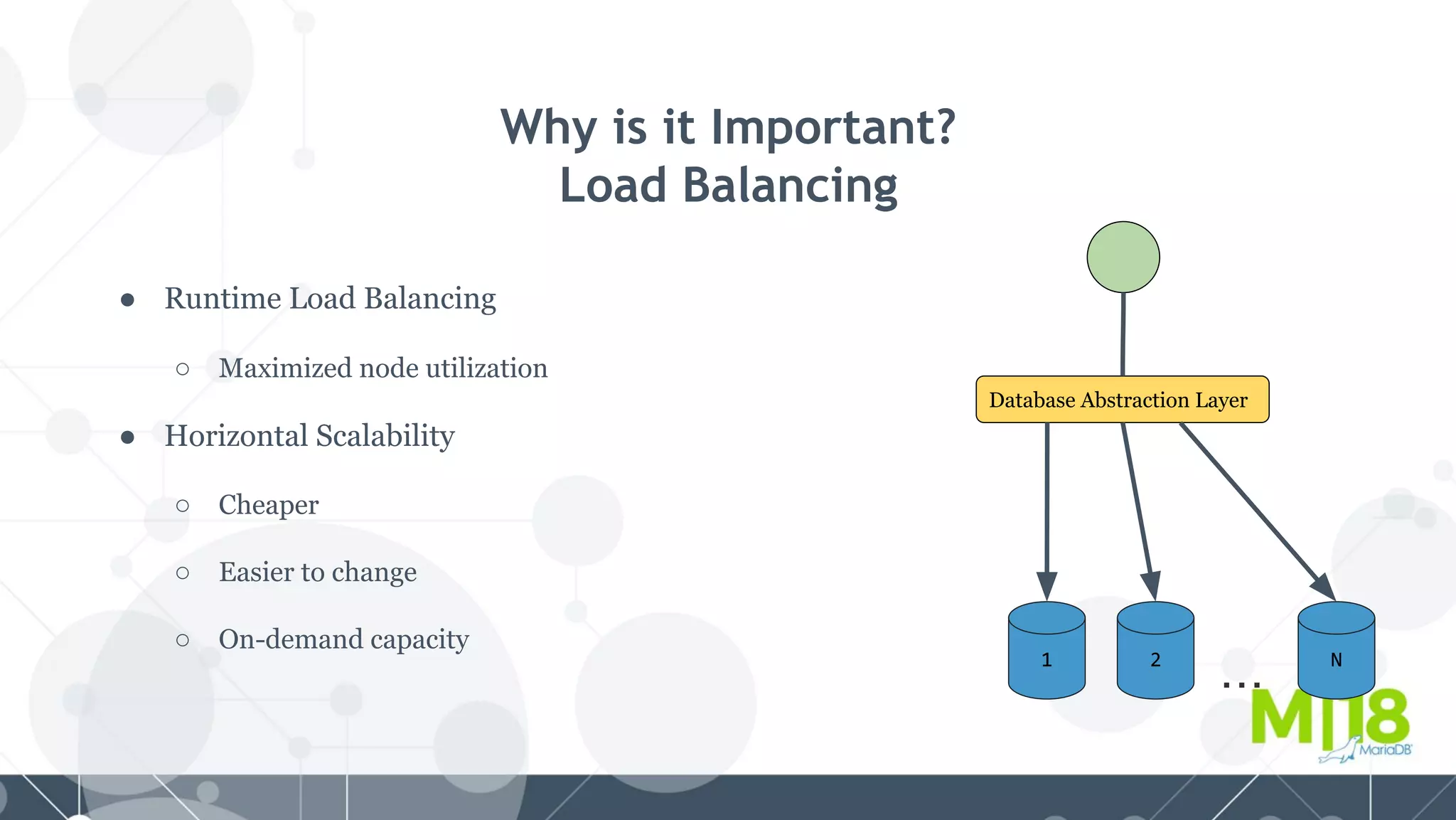

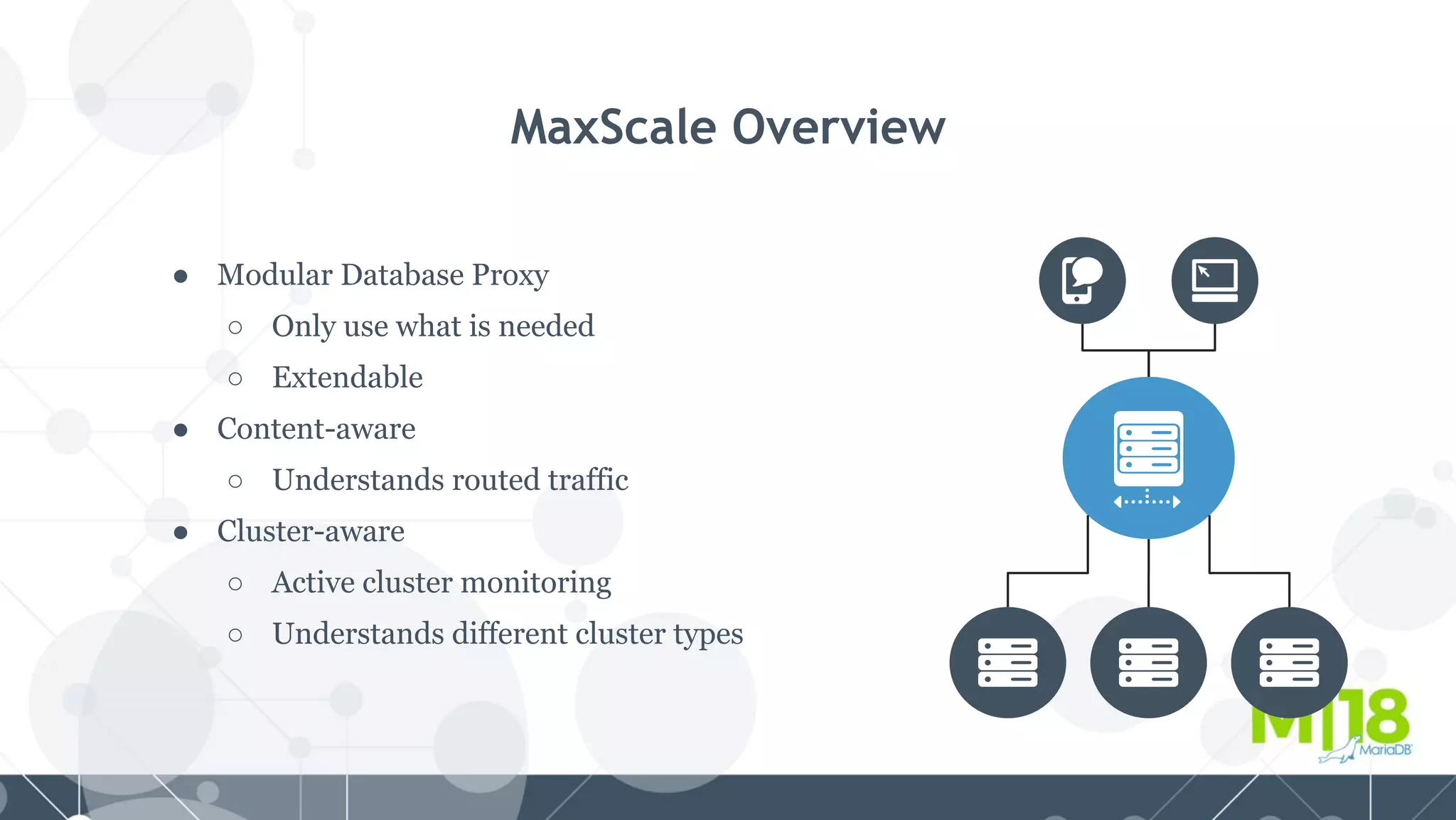
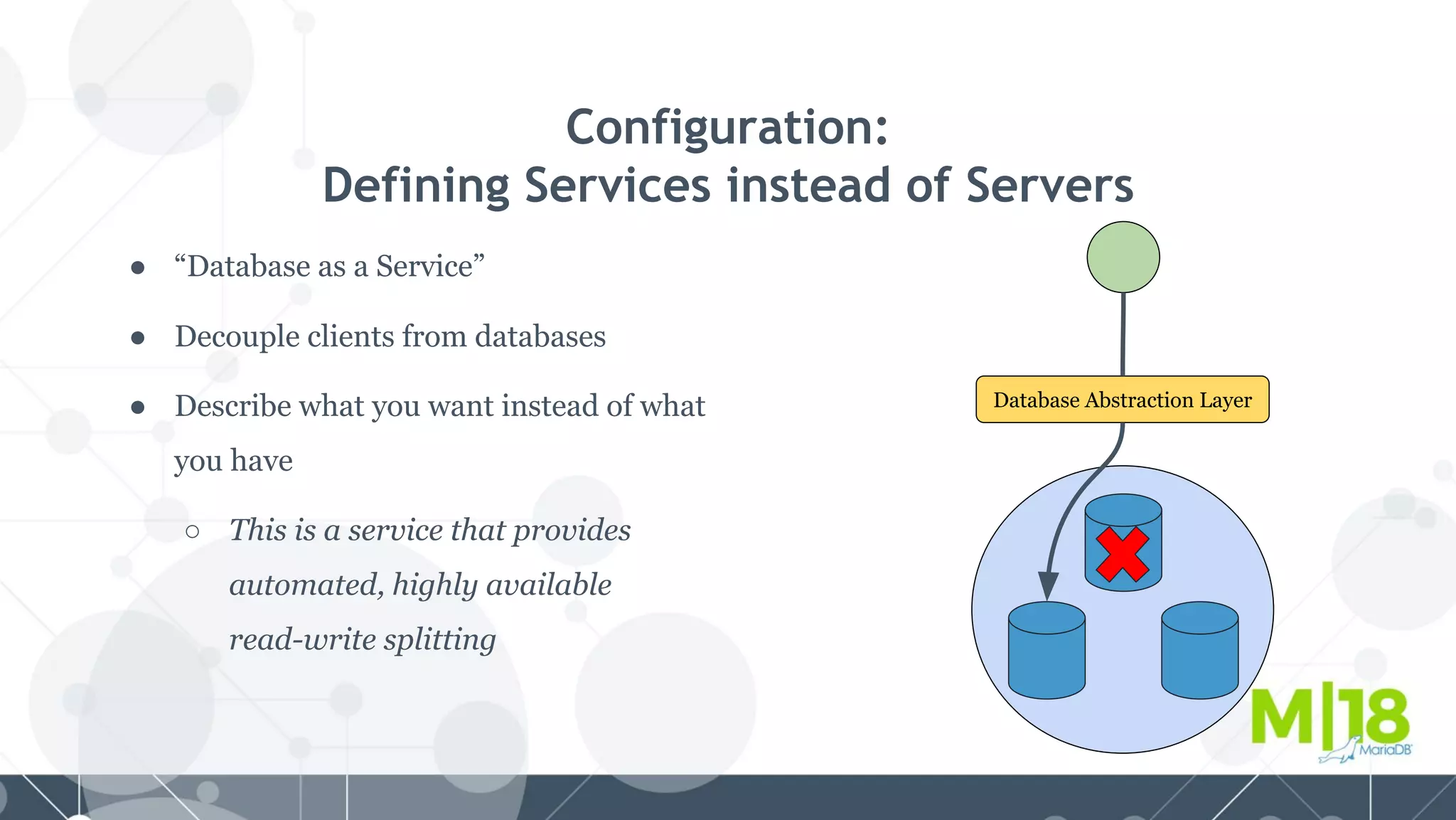


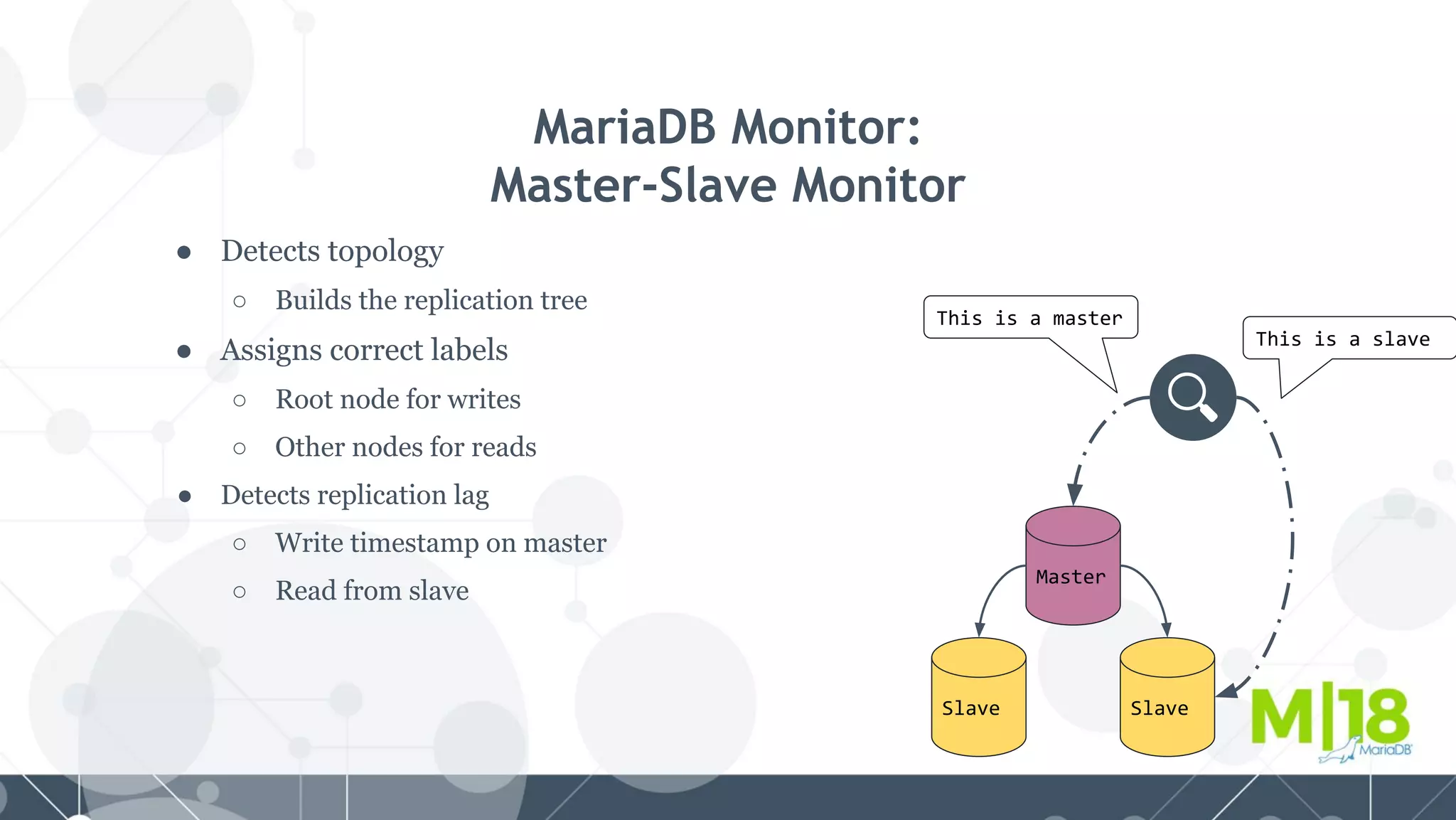
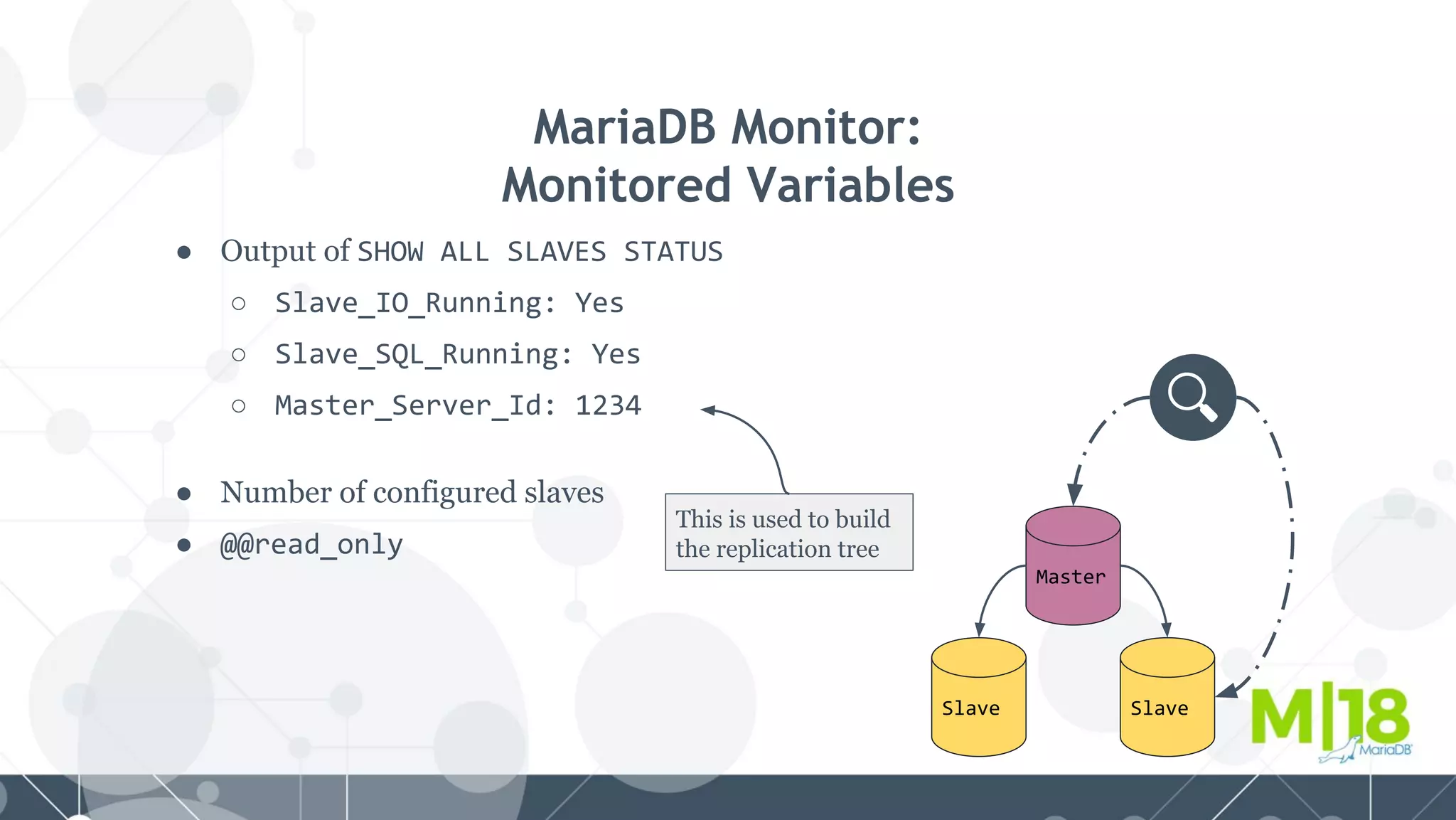
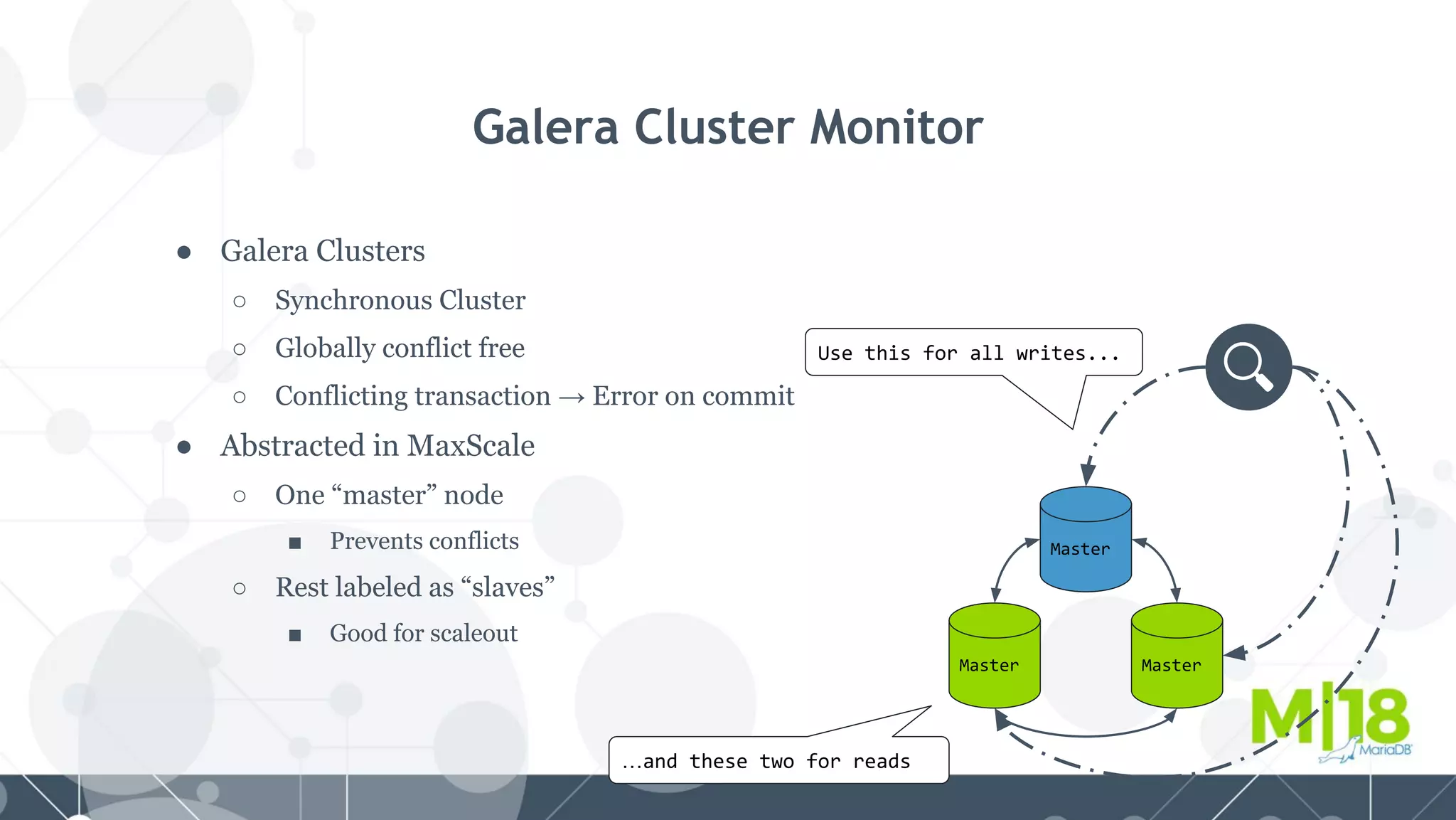
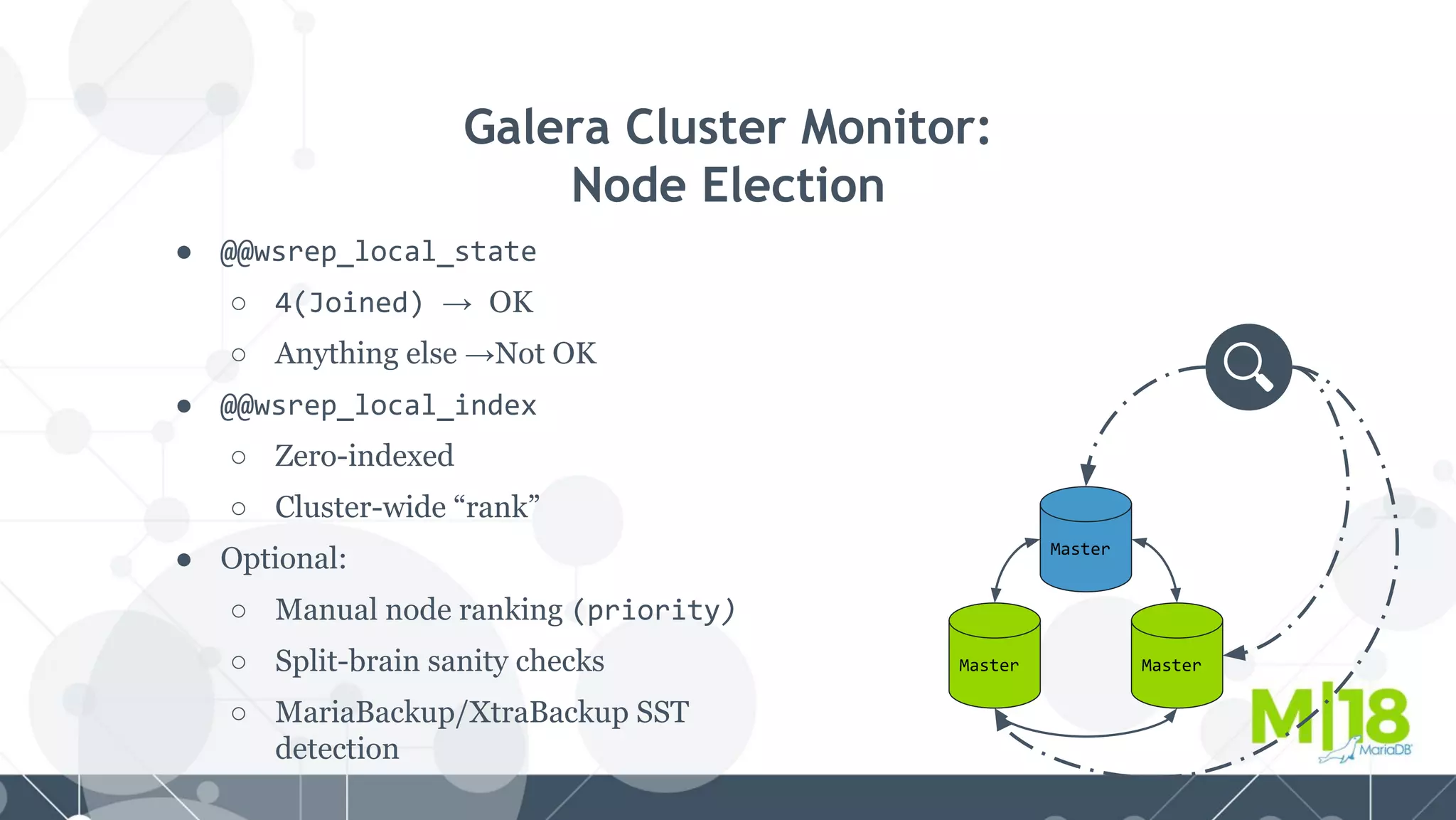






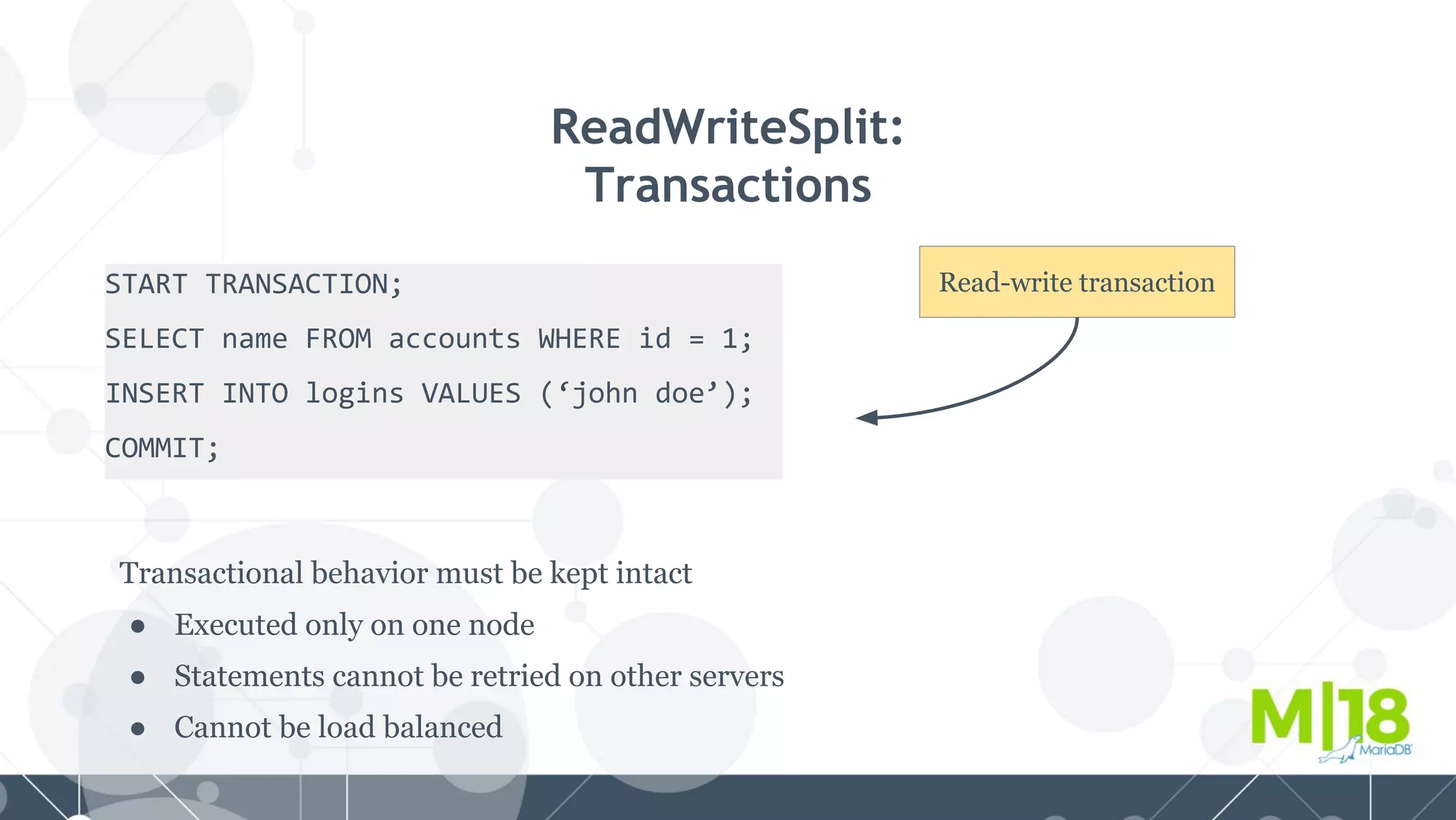









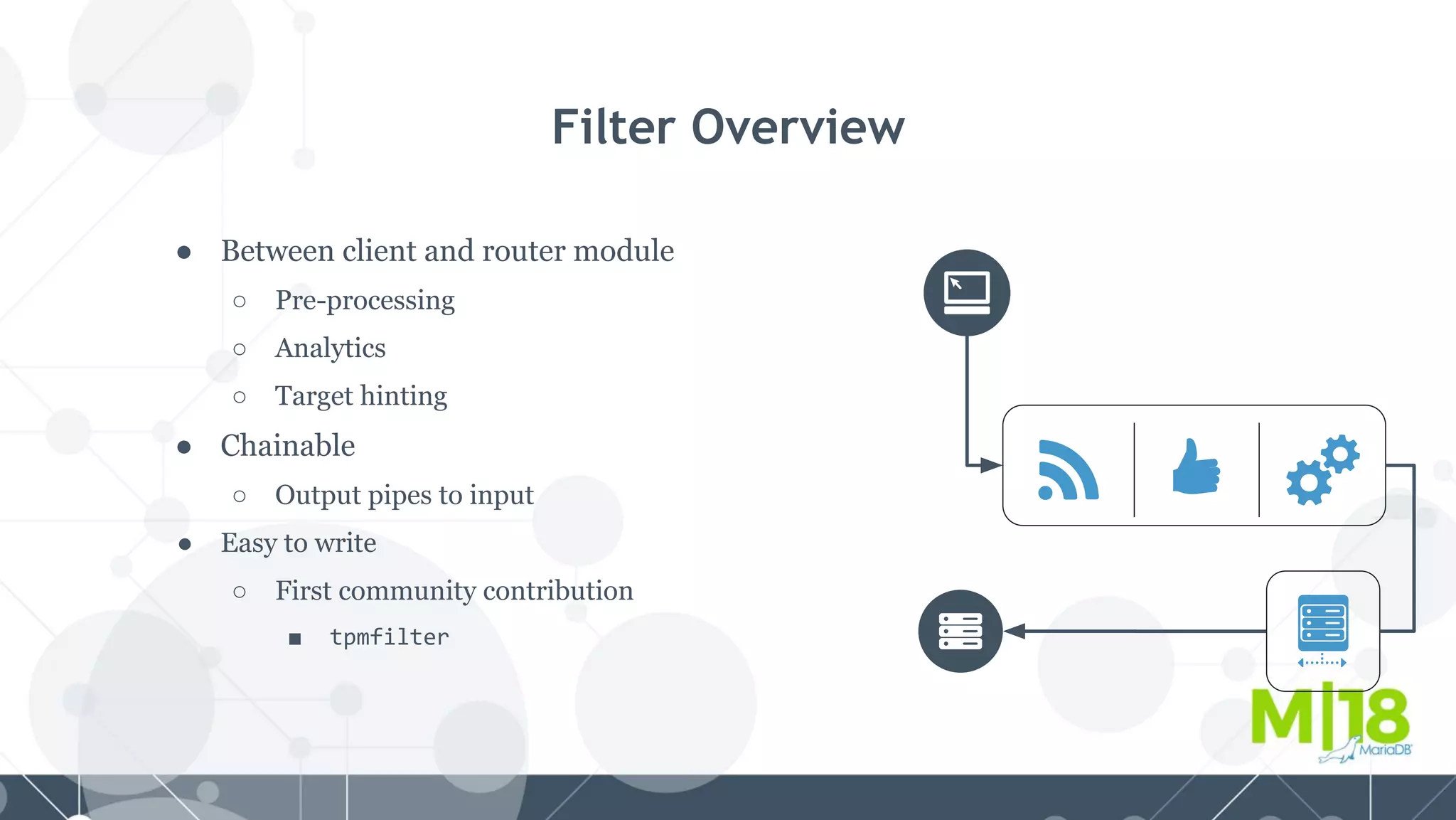








MariaDB MaxScale is a database proxy that abstracts away the underlying database infrastructure. It provides a single logical view of the database even if it is physically distributed as a cluster. This simplifies application development and management. It also provides high availability through failure tolerance and load balancing for better performance. MaxScale uses monitors to detect the cluster topology and status, classifiers to understand queries, and routers to direct traffic, hiding the physical infrastructure and enabling horizontal scalability. Filters can further extend its functionality such as for caching, analytics, or patching SQL. Overall, MaxScale abstracts database clusters to make them easier to use while preserving high performance and availability.






















































































