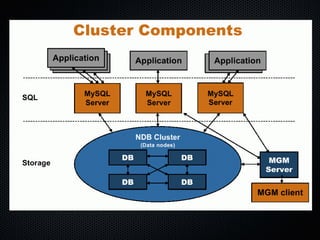
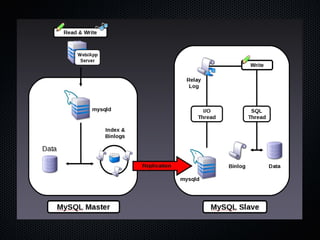
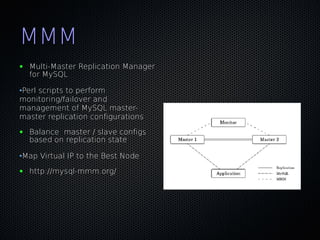
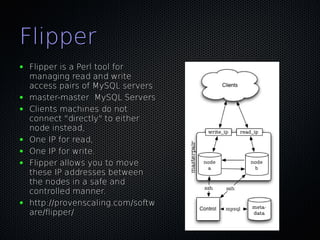
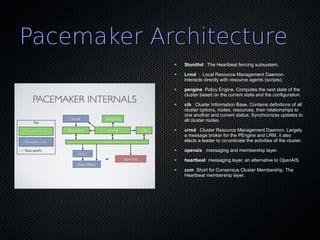
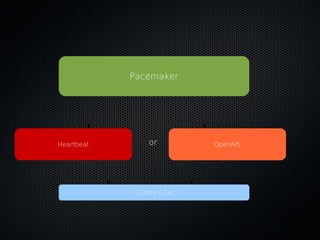
This document discusses using Pacemaker with MySQL for high availability (HA). It covers key concepts in HA including eliminating single points of failure. It then discusses various MySQL HA solutions like replication, DRBD, MySQL Cluster, and using Linux HA tools like Pacemaker. Pacemaker manages resources across nodes to ensure services are always running, and can monitor and migrate MySQL and other services in an HA cluster. The document provides configuration examples and best practices for setting up MySQL HA with Pacemaker.



































![Configuring Heartbeat
heartbeat::hacf {"clustername":
hosts => ["host-a","host-b"],
hb_nic => ["bond0"],
hostip1 => ["10.0.128.11"],
hostip2 => ["10.0.128.12"],
ping => ["10.0.128.4"],
}
heartbeat::authkeys {"ClusterName":
password => “ClusterName ",
}
http://github.com/jtimberman/puppet/tree/master/heartbeat/](https://image.slidesharecdn.com/buytaertkrismysql-pacemaker-120606052427-phpapp01/85/Buytaert-kris-my_sql-pacemaker-42-320.jpg)







































































































