My sql fabric ha and sharding solutions
•
2 likes•1,395 views

MySQL Fabric is a clustering solution for MySQL introduced by Oracle after acquiring MySQL. It can provide high availability (HA) capabilities for MySQL through clustering and can also provide data sharding functionality. The HA mode relies on MySQL 5.6's GTID replication capability, while data sharding can be implemented using techniques like range-based or hash-based sharding. Fabric demonstrates Oracle's commitment to advancing MySQL towards mature enterprise-grade applications.

Recommended
More Related Content
What's hot
What's hot (20)
Similar to My sql fabric ha and sharding solutions
Similar to My sql fabric ha and sharding solutions (20)
More from Louis liu
More from Louis liu (20)
Recently uploaded
Recently uploaded (20)
My sql fabric ha and sharding solutions
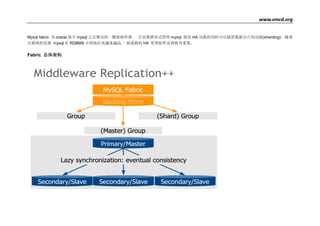
- 1. www.vmcd.org MySQL Fabric 为 Oracle 接手 MySQL 之后推出的一颗重磅炸弹。 它以集群形式管理 MySQL 提供 HA 功能的同时可以提供数据分片的功能 (Sharding)。其中 HA 模式依赖 MySQL5.6+的 GTID 功能,数据分片可以使用多种方式如 Range,Hash 等。随着互联网的发展 MySQL 在 RDBMS 中的地位也越来越高.以目前 Oracle 的态度来说,MySQL 在将来将是一颗重要的棋子,在内部 Oracle 也在积极推动部分的 Cluster 朝 MySQL cluster 的转移。包括最新的 12c RAC Clusterware 套件也将会支持 MySQL。Fabric 的推出表明了 Oracle 推进 MySQL 向成熟化企业级应用发展的决心。 Fabric 总体架构
- 2. www.vmcd.org MySQL Fabric 需要安装的组件: ●MySQL Fabric: Prerequisites ●MySQL Servers (version 5.6.10 or later) ●Backing store database server ●Application databaseservers ●Python 2.6 or 2.7 ●No support for 3.x yet ●MySQL Utilities 1.4 ●Available at https://dev.MySQL.com/downloads/tools/utilities ●MySQL-connect-python-1.2.2-1.e16.noarch $MySQL --socket=/data/MySQL3334/data/MySQL.sock Welcome to the MySQL monitor. Commands end with ; or g. Your MySQL connection id is 57 Server version: 5.6.16-log MySQL Community Server (GPL) Copyright (c) 2000, 2014, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or 'h' for help. Type 'c' to clear the current input statement. MySQL>
- 3. www.vmcd.org 我们的环境为: MySQL Fabric + DB : 10.0.128.115:3334 MySQL5.6.16 MySQL server : 10.0.128.116-117:3334 10.0.128.254:3334 MySQL5.6.16 先创建 Fabric 用户注意 这个用户所在的 DB 为 localhost 即 Fabric manage 所在主机的 DB: MySQL> show grants for 'Fabric'@'127.0.0.1'; +---------------------------------------------------------------------------------------------------------------+ | Grants for Fabric@127.0.0.1 | +---------------------------------------------------------------------------------------------------------------+ | GRANT USAGE ON *.* TO 'Fabric'@'127.0.0.1' IDENTIFIED BY PASSWORD '*14E65567ABDB5135D0CFD9A70B3032C179A49EE7' | | GRANT ALL PRIVILEGES ON `Fabric`.* TO 'Fabric'@'127.0.0.1' | +---------------------------------------------------------------------------------------------------------------+ 2 rows in set (0.00 sec) MySQL> show grants for 'Fabric'@'localhost'; +---------------------------------------------------------------------------------------------------------------+ | Grants for Fabric@localhost | +---------------------------------------------------------------------------------------------------------------+ | GRANT USAGE ON *.* TO 'Fabric'@'localhost' IDENTIFIED BY PASSWORD '*14E65567ABDB5135D0CFD9A70B3032C179A49EE7' | | GRANT ALL PRIVILEGES ON `Fabric`.* TO 'Fabric'@'localhost' | +---------------------------------------------------------------------------------------------------------------+ 2 rows in set (0.00 sec)
- 4. www.vmcd.org 配置 Fabric 参数文件: $cat /etc/MySQL/Fabric.cfg [DEFAULT] prefix = sysconfdir = /etc logdir = /var/log [statistics] prune_time = 3600 [logging] url = file:///var/log/Fabric.log level = INFO [storage] auth_plugin = MySQL_native_password database = Fabric user = Fabric address = localhost:3334 connection_delay = 1 connection_timeout = 6 password = secret connection_attempts = 6
- 5. www.vmcd.org [failure_tracking] notification_interval = 60 notification_clients = 50 detection_timeout = 1 detection_interval = 6 notifications = 300 detections = 3 failover_interval = 0 prune_time = 3600 [servers] password = Fabric user = Fabric [connector] ttl = 1 [client] password = [protocol.xmlrpc] disable_authentication = no ssl_cert = realm = MySQL Fabric ssl_key = ssl_ca =
- 6. www.vmcd.org threads = 5 user = admin address = 10.0.128.115:32274 password = admin [executor] executors = 5 [Sharding] MySQLdump_program = /usr/bin/MySQLdump MySQLclient_program = /usr/bin/MySQL 直接初始化 Fabric 注意 执行命令会后将在 Fabric 节点 MySQL database 建立相关的 table: MySQLFabric manage setup --param=storage.user=Fabric --param=storage.password=secret MySQL> use Fabric; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A
- 7. www.vmcd.org Database changed MySQL> show tables; +-------------------+ | Tables_in_Fabric | +-------------------+ | checkpoints | | error_log | | group_replication | | group_view | | groups | | log | | permissions | | proc_view | | role_permissions | | roles | | servers | | shard_maps | | shard_ranges | | shard_tables | | shards | | user_roles | | users | +-------------------+ 17 rows in set (0.00 sec)
- 8. www.vmcd.org 启动 Fabric manage: Nohup MySQLFabric manage start & [INFO] 1402648110.182016 - MainThread - Initializing persister: user (Fabric), server (localhost:3334), database (Fabric). [INFO] 1402648110.190860 - MainThread - Loading Services. [INFO] 1402648110.226332 - MainThread - Fabric node starting. [INFO] 1402648110.300123 - MainThread - Starting Executor. [INFO] 1402648110.300557 - MainThread - Setting 5 executor(s). [INFO] 1402648110.301763 - Executor-0 - Started. [INFO] 1402648110.303667 - Executor-1 - Started. [INFO] 1402648110.307275 - Executor-2 - Started. [INFO] 1402648110.310304 - Executor-3 - Started. [INFO] 1402648110.315261 - MainThread - Executor started. [INFO] 1402648110.316525 - Executor-4 - Started. [INFO] 1402648110.332045 - MainThread - Starting failure detector. [INFO] 1402648110.333889 - XML-RPC-Server - XML-RPC protocol server ('10.0.128.115', 32274) started. [INFO] 1402648110.335377 - XML-RPC-Server - Setting 5 XML-RPC session(s). [INFO] 1402648110.336328 - XML-RPC-Session-0 - Started XML-RPC-Session. [INFO] 1402648110.340544 - XML-RPC-Session-1 - Started XML-RPC-Session. [INFO] 1402648110.342567 - XML-RPC-Session-2 - Started XML-RPC-Session. [INFO] 1402648110.345735 - XML-RPC-Session-3 - Started XML-RPC-Session. [INFO] 1402648110.348399 - XML-RPC-Session-4 - Started XML-RPC-Session.
- 9. www.vmcd.org Fabric 的全部命令 (后面利用 add group 等命令可以添加激活 Fabric 集群) #MySQLFabric help commands statistics node Retrieve statistics on the Fabric node. statistics group Retrieve statistics on Procedures. statistics procedure Retrieve statistics on Procedures. group activate Activate failure detector for server(s) in a group. group description Update group's description. group deactivate Deactivate failure detector for server(s) in a group. group create Create a group. group remove Remove a server from a group. group add Add a server into group. group health Check if any server within a group has failed and report health information. group lookup_servers Return information on existing server(s) in a group. group destroy Remove a group. group demote Demote the current master if there is one. group promote Promote a server into master. group lookup_groups Return information on existing group(s). dump Fabric_nodes Return a list of Fabric servers. dump shard_index Return information about the index for all mappings matching any of the patterns provided. dump Sharding_information Return all the Sharding information about the tables passed as patterns. dump servers Return information about servers.
- 10. www.vmcd.org dump shard_tables Return information about all tables belonging to mappings matching any of the provided patterns. dump shard_maps Return information about all shard mappings matching any of the provided patterns. manage teardown Teardown Fabric Storage System. manage stop Stop the Fabric server. manage setup Setup Fabric Storage System. manage ping Check whether Fabric server is running or not. manage start Start the Fabric server. manage logging_level Set logging level. server set_weight Set a server's weight. server clone Clone the objects of a given server into a destination server. server lookup_uuid Return server's uuid. server set_mode Set a server's mode. server set_status Set a server's status. role list List roles and associated permissions user roles Change roles for a Fabric user * protocol: Protocol of the user (for example 'xmlrpc') * roles: Comma separated list of roles, IDs or names (see `role list`) user usercommand Base class for all user commands user list List users and their roles user add Add a new Fabric user. user password Change password of a Fabric user. user delete Delete a Fabric user. threat report_error Report a server error.
- 11. www.vmcd.org threat report_failure Report with certantity that a server has failed or is unreachable. Sharding list_definitions Lists all the shard mapping definitions. Sharding remove_definition Remove the shard mapping definition represented by the Shard Mapping ID. Sharding move_shard Move the shard represented by the shard_id to the destination group. Sharding disable_shard Disable a shard. Sharding remove_table Remove the shard mapping represented by the Shard Mapping object. Sharding split_shard Split the shard represented by the shard_id into the destination group. Sharding create_definition Define a shard mapping. Sharding add_shard Add a shard. Sharding add_table Add a table to a shard mapping. Sharding lookup_table Fetch the shard specification mapping for the given table Sharding enable_shard Enable a shard. Sharding remove_shard Remove a Shard. Sharding list_tables Returns all the shard mappings of a particular Sharding_type. Sharding prune_shard Given the table name prune the tables according to the defined Sharding specification for the table. Sharding lookup_servers Lookup a shard based on the give Sharding key. event trigger Trigger an event. event wait_for_procedures Wait until procedures, which are identified through their uuid in a list and separated by comma, finish their execution.
- 12. www.vmcd.org Fabric HA 测试: 直接添加 GROUP: MySQLFabric group create pajk_group 在 MySQL server 中 (data node) 加入 Fabric 用户: Grant all privileges on *.* to ‘Fabric’@’%’ identified by ‘Fabric’; 在 group 中添加 node: MySQLFabric group add pajk_group 10.0.128.254:3334 MySQLFabric group add pajk_group 10.0.128.116:3334 MySQLFabric group add pajk_group 10.0.128.117:3334 激活 GROUP 选举出 PRIAMRY 节点 MySQLFabric group promote pajk_group --slave_id=10.0.128.116:3334 MySQLFabric group activate pajk_group
- 13. www.vmcd.org 查看节点选举情况: #MySQLFabric group lookup_servers pajk_group Command : { success = True return = [{'status': 'SECONDARY', 'server_uuid': 'c05867d3-f2cd-11e3-b224-5254009c6d0c', 'mode': 'READ_ONLY', 'weight': 1.0, 'address': '10.0.128.254:3334'}, {'status': 'PRIMARY', 'server_uuid': 'e2ca75e1-d65f-11e3-b8c2-525400d3350c', 'mode': 'READ_WRITE', 'weight': 1.0, 'address': '10.0.128.116:3334'}, {'status': 'SECONDARY', 'server_uuid': 'e90d3e07-f2cd-11e3-b225-525400991d01', 'mode': 'READ_ONLY', 'weight': 1.0, 'address': '10.0.128.117:3334'}] activities = } 可以看到 已经成功建立了复制集合 注意需要使用 GTID Kill 掉主节点 PRIMARY [WARNING] 1403000877.240037 - FailureDetector(pajk_group) - Server (e2ca75e1-d65f-11e3-b8c2-525400d3350c) in group (pajk_group) is unreachable. [WARNING] 1403000879.259873 - FailureDetector(pajk_group) - Server (e2ca75e1-d65f-11e3-b8c2-525400d3350c) in group (pajk_group) is unreachable. [WARNING] 1403000881.279679 - FailureDetector(pajk_group) - Server (e2ca75e1-d65f-11e3-b8c2-525400d3350c) in group (pajk_group) is unreachable. [WARNING] 1403000881.458935 - Executor-2 - Reported issue (FAULTY) for server (e2ca75e1-d65f-11e3-b8c2-525400d3350c). [INFO] 1403000881.463634 - Executor-2 - Master (e2ca75e1-d65f-11e3-b8c2-525400d3350c) in group (pajk_group) has been lost. [WARNING] 1403000882.248376 - Executor-2 - Error (<server(uuid=e90d3e07-f2cd-11e3-b225-525400991d01, address=10.0.128.117:3334, mode=READ_ONLY, status=SECONDARY>) trying to process transactions in the relay log for candidate (Error waiting for slave to catch up. Binary log (MySQL-bin.000018, 2050964).). [INFO] 1403000882.990106 - Executor-2 - Master has changed from e2ca75e1-d65f-11e3-b8c2-525400d3350c to e90d3e07-f2cd-11e3-b225-525400991d01.
- 14. www.vmcd.org 主节点切换到了 10.0.128.117 #MySQLFabric group lookup_servers pajk_group Command : { success = True return = [{'status': 'SECONDARY', 'server_uuid': 'c05867d3-f2cd-11e3-b224-5254009c6d0c', 'mode': 'READ_ONLY', 'weight': 1.0, 'address': '10.0.128.254:3334'}, {'status': 'FAULTY', 'server_uuid': 'e2ca75e1-d65f-11e3-b8c2-525400d3350c', 'mode': 'READ_WRITE', 'weight': 1.0, 'address': '10.0.128.116:3334'}, {'status': 'PRIMARY', 'server_uuid': 'e90d3e07-f2cd-11e3-b225-525400991d01', 'mode': 'READ_WRITE', 'weight': 1.0, 'address': '10.0.128.117:3334'}] activities = } 重新启动 10.0.128.116 加入 group #MySQLFabric group remove pajk_group 10.0.128.116:3334 Procedure : { uuid = 62961ea5-3aef-4ab0-9502-07ef08bef6d3, finished = True, success = True, return = True, activities = }
- 15. www.vmcd.org #MySQLFabric group add pajk_group 10.0.128.116:3334 Procedure : { uuid = 873e43e1-e1fd-4b17-a73f-e665b8353108, finished = True, success = True, return = True, activities = } [root@pajk-t-MySQL-master1 /root] #MySQLFabric group lookup_servers pajk_group Command : { success = True return = [{'status': 'SECONDARY', 'server_uuid': 'c05867d3-f2cd-11e3-b224-5254009c6d0c', 'mode': 'READ_ONLY', 'weight': 1.0, 'address': '10.0.128.254:3334'}, {'status': 'SECONDARY', 'server_uuid': 'e2ca75e1-d65f-11e3-b8c2-525400d3350c', 'mode': 'READ_ONLY', 'weight': 1.0, 'address': '10.0.128.116:3334'}, {'status': 'PRIMARY', 'server_uuid': 'e90d3e07-f2cd-11e3-b225-525400991d01', 'mode': 'READ_WRITE', 'weight': 1.0, 'address': '10.0.128.117:3334'}] activities = } 10.0.128.116 重新加入了集群管理。
- 17. www.vmcd.org 创建 3 个 Sharding 组: Fabric_test1_global: 存放 metadata 信息 复制 DDL 语句 以及不在 Sharding set 组里的复制 分为两个 Sharding Fabric_test1_shard1: 存放 emp_no < 10000 的数据 Fabric_test1_shard2: 存放 emp_no >=10000 的数据 添加 global group: #MySQLFabric group create Fabric_test1_global Procedure : { uuid = 69e8b16f-a42c-4759-b642-d3e0ead1ca3a, finished = True, success = True, return = True, activities = } [root@pajk-t-MySQL-master1 /Fabric] #MySQLFabric group add Fabric_test1_global 10.0.128.254:3334 Procedure :
- 18. www.vmcd.org { uuid = be0e470f-fa65-4b77-a49a-173898eba7ec, finished = True, success = True, return = True, activities = } [root@pajk-t-MySQL-master1 /Fabric] #MySQLFabric group create Fabric_test1_shard1 Procedure : { uuid = 3877fbb9-cf3a-4dd2-ae73-0592303915a1, finished = True, success = True, return = True, activities = } 添加两个 Sharding group: [root@pajk-t-MySQL-master1 /Fabric] #MySQLFabric group create Fabric_test1_shard1 Procedure : { uuid = 3877fbb9-cf3a-4dd2-ae73-0592303915a1, finished = True, success = True,
- 19. www.vmcd.org return = True, activities = } [root@pajk-t-MySQL-master1 /Fabric] #MySQLFabric group add Fabric_test1_shard1 10.0.128.116:3334 Procedure : { uuid = e1b2ef20-3329-4e5f-97cb-d9fc7372b210, finished = True, success = True, return = True, activities = } [root@pajk-t-MySQL-master1 /Fabric] #MySQLFabric group promote Fabric_test1_shard1 Procedure : { uuid = 1d1834c5-53f1-40d0-b0d6-a15cc128bc21, finished = True, success = True, return = True, activities = } [root@pajk-t-MySQL-master1 /Fabric] #MySQLFabric group create Fabric_test1_shard2
- 20. www.vmcd.org Procedure : { uuid = 05a1ef78-f8a9-4c10-8afd-2fb9dc85626b, finished = True, success = True, return = True, activities = } [root@pajk-t-MySQL-master1 /Fabric] #MySQLFabric group add Fabric_test1_shard2 10.0.128.117:3334 Procedure : { uuid = 984c95dd-1031-4d0c-ae37-8ff91dc94993, finished = True, success = True, return = True, activities = } [root@pajk-t-MySQL-master1 /Fabric] # MySQLFabric group promote Fabric_test1_shard2 Procedure : { uuid = 804c1c0a-d474-4c4e-8a9d-494103fb5317, finished = True, success = True, return = True, activities = }
- 21. www.vmcd.org 添加 shard 定义 (只用 range 分区 employees emp_no column) #MySQLFabric Sharding create_definition RANGE Fabric_test1_global Procedure : { uuid = 8d0cf317-8cc9-40e5-a8b8-aa4ded985a86, finished = True, success = True, return = 1, activities = } 创建 mapping 使用 definition 的 return 值 #MySQLFabric Sharding add_table 1 employees.employees emp_no Procedure : { uuid = 6702a70b-f32d-452c-af2d-df0da291109f, finished = True, success = True, return = True, activities = }
- 22. www.vmcd.org 创建 Sharding range 条件 #MySQLFabric Sharding add_shard 1 Fabric_test1_shard1/0,Fabric_test1_shard2/10000 --state=ENABLED Procedure : { uuid = 07d49de6-9778-4d53-b240-a5579a6ec740, finished = True, success = True, return = True, activities = } 最终关系为: 10.0.128.254 作为 global group 负责存放 Sharding metadata 负责复制 DDL 到 slaves(10.0.128.117,10.0.128.116) 但是不存放实际数 据,slave 根据 Sharding 条件存放实际数据, 对于没有 Sharding 关系的表, 整个 Fabric 集群存在正常的复制关系 即 Master->slave MySQL> select * from groups; +---------------------+-------------+--------------------------------------+----------------------------+--------+ | group_id | description | master_uuid | master_defined | status | +---------------------+-------------+--------------------------------------+----------------------------+--------+ | Fabric_test1_global | NULL | fbfac317-f62b-11e3-881b-5254009c6d0c | 2014-06-18 03:19:44.000000 | | | Fabric_test1_shard1 | NULL | fefe406d-f62c-11e3-8821-525400bead34 | 2014-06-18 03:20:28.000000 | | | Fabric_test1_shard2 | NULL | fd54cafa-f632-11e3-8848-525400991d01 | 2014-06-18 03:20:54.000000 | | +---------------------+-------------+--------------------------------------+----------------------------+--------+ 3 rows in set (0.00 sec)
- 23. www.vmcd.org MySQL> select * from servers; +--------------------------------------+-------------------+------+--------+--------+---------------------+ | server_uuid | server_address | mode | status | weight | group_id | +--------------------------------------+-------------------+------+--------+--------+---------------------+ | fbfac317-f62b-11e3-881b-5254009c6d0c | 10.0.128.254:3334 | 3 | 3 | 1 | Fabric_test1_global | | fd54cafa-f632-11e3-8848-525400991d01 | 10.0.128.117:3334 | 3 | 3 | 1 | Fabric_test1_shard2 | | fefe406d-f62c-11e3-8821-525400bead34 | 10.0.128.116:3334 | 3 | 3 | 1 | Fabric_test1_shard1 | +--------------------------------------+-------------------+------+--------+--------+---------------------+ 3 rows in set (0.00 sec) MySQL> select * from shard_ranges; +------------------+-------------+----------+ | shard_mapping_id | lower_bound | shard_id | +------------------+-------------+----------+ | 1 | 0 | 3 | | 1 | 10000 | 4 | +------------------+-------------+----------+ 2 rows in set (0.00 sec) MySQL> select * from shard_maps; +------------------+-----------+---------------------+ | shard_mapping_id | type_name | global_group | +------------------+-----------+---------------------+ | 1 | RANGE | Fabric_test1_global | +------------------+-----------+---------------------+ 1 row in set (0.00 sec)
- 24. www.vmcd.org MySQL> select * from shard_tables -> ; +------------------+---------------------+-------------+ | shard_mapping_id | table_name | column_name | +------------------+---------------------+-------------+ | 1 | employees.employees | emp_no | +------------------+---------------------+-------------+ 1 row in set (0.00 sec) MySQL> select * from shards; +----------+---------------------+---------+ | shard_id | group_id | state | +----------+---------------------+---------+ | 3 | Fabric_test1_shard1 | ENABLED | | 4 | Fabric_test1_shard2 | ENABLED | +----------+---------------------+---------+ 2 rows in set (0.00 sec)
- 25. www.vmcd.org Code example: TEST.LIU 不存在 Sharding 关系 直接为 MS 复制: MySQL> desc test.liu; +-------+---------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+---------+------+-----+---------+-------+ | id | int(11) | YES | | NULL | | +-------+---------+------+-----+---------+-------+ 1 row in set (0.00 sec) #cat test1.py #!/usr/bin/python #****************************************************************# # ScriptName: test.py # Create Date: 2014-06-13 17:18 # Modify Date: 2014-06-13 17:18 #***************************************************************# import MySQL.connector from MySQL.connector import Fabric conn = MySQL.connector.connect( Fabric={"host" : "10.0.128.115", "port" : 32274, "username": "admin", "password" : "admin" },
- 26. www.vmcd.org user="Oracle", password="Oracle", autocommit=True ) conn.set_property(group="Fabric_test1_global", mode=Fabric.MODE_READWRITE) cur = conn.cursor() cur.execute("USE test") cur.execute( "insert into liu values (1),(2),(3),(4)") [MySQL@pajk-t-MySQL-slave1 /home/MySQL] $MySQL --socket=/data/MySQL3334/data/MySQL.sock -e "select * from test.liu" +------+ | id | +------+ | 1 | | 2 | | 3 | | 4 | | 1 | | 2 | | 3 | | 4 | +------+ [MySQL@pajk-super-master /home/MySQL] $MySQL --socket=/data/MySQL3334/data/MySQL.sock -e "select * from test.liu"
- 27. www.vmcd.org +------+ | id | +------+ | 1 | | 2 | | 3 | | 4 | | 1 | | 2 | | 3 | | 4 | +------+ [MySQL@pajk-t-MySQL-master2 /home/MySQL] $MySQL --socket=/data/MySQL3334/data/MySQL.sock -e "select * from test.liu" +------+ | id | +------+ | 1 | | 2 | | 3 | | 4 | | 1 | | 2 | | 3 | | 4 | +------+
- 28. www.vmcd.org 此时为简单的 MS 关系: MySQL> show slave statusG; *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 10.0.128.254 Master_User: Fabric Master_Port: 3334 Connect_Retry: 60 Master_Log_File: MySQL-bin.000001 Read_Master_Log_Pos: 441 Relay_Log_File: GSS-01-relay-bin.000002 Relay_Log_Pos: 651 Relay_Master_Log_File: MySQL-bin.000001 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0
- 29. www.vmcd.org Exec_Master_Log_Pos: 441 Relay_Log_Space: 856 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0 Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 10 Master_UUID: fbfac317-f62b-11e3-881b-5254009c6d0c Master_Info_File: /data/MySQL3334/relaylog/master.info SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it Master_Retry_Count: 86400 Master_Bind:
- 30. www.vmcd.org Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: fbfac317-f62b-11e3-881b-5254009c6d0c:1-2 Executed_Gtid_Set: fbfac317-f62b-11e3-881b-5254009c6d0c:1-2 Auto_Position: 1 1 row in set (0.00 sec) EMPLOYEES.EMPLOYEES 存在 Sharding 关系 #cat test6.py #!/usr/bin/python #****************************************************************# # ScriptName: test6.py # Create Date: 2014-06-18 00:49 # Modify Date: 2014-06-18 00:49 #***************************************************************# import MySQL.connector from MySQL.connector import Fabric #def add_subscriber(conn, emp_no, first_name, last_name): # cur = conn.cursor() # sql=""" INSERT INTO employees.employees VALUES (%s, %s, %s) """ % (emp_no, first_name, last_name) # cur.execute(sql)
- 31. www.vmcd.org # Address of the Fabric node, rather than the actual MySQL Server. conn = MySQL.connector.connect( Fabric={"host" : "10.0.128.115", "port" : 32274,"username": "admin","password": "admin"}, user="Oracle", database="employees", password="Oracle", autocommit=True ) conn.set_property(tables=["employees.employees"],key=10000, mode=Fabric.MODE_READWRITE) #def add_subscriber(conn, emp_no, first_name, last_name): cur = conn.cursor() emp_no=10000 first_name="Fabric" last_name="Fabric" sql=""" INSERT INTO employees.employees VALUES ('%s', '%s', '%s') """ % (emp_no, first_name, last_name) print sql cur.execute(sql) conn.commit() 此时 Master global group 不存放数据 [MySQL@pajk-super-master /home/MySQL] $MySQL --socket=/data/MySQL3334/data/MySQL.sock -e "select * from employees.employees" 实际数据根据 Sharding 条件 存放在 Sharding 节点: [MySQL@pajk-t-MySQL-master2 /home/MySQL]
- 32. www.vmcd.org $MySQL --socket=/data/MySQL3334/data/MySQL.sock -e "select * from employees.employees" +----------+------------+-----------+ | emp_no | first_name | last_name | +----------+------------+-----------+ | 5000000 | liu | yang | | 50000000 | Fabric | Fabric | | 10000 | Fabric | Fabric | +----------+------------+-----------+ [MySQL@pajk-t-MySQL-slave1 /home/MySQL] $MySQL --socket=/data/MySQL3334/data/MySQL.sock -e "select * from employees.employees" +--------+------------+-----------+ | emp_no | first_name | last_name | +--------+------------+-----------+ | 3 | billy | fish | | 3 | billy | fish | | 3 | liu | yang | | 3 | liu | yang | +--------+------------+-----------+ 对 10000 这条记录做 update 操作 sql=”update employees.employees set emp_no=10001 where emp_no=10000”
- 33. www.vmcd.org $MySQL --socket=/data/MySQL3334/data/MySQL.sock -e "select * from employees.employees" +----------+------------+-----------+ | emp_no | first_name | last_name | +----------+------------+-----------+ | 5000000 | liu | yang | | 50000000 | Fabric | Fabric | | 10001 | Fabric | Fabric | +----------+------------+-----------+ 对 表做 DDL 操作: Sql=”alter table employees.employees add nickname varchar(20)” #cat test10.py #!/usr/bin/python #****************************************************************# # ScriptName: test.py # Create Date: 2014-06-13 17:18 # Modify Date: 2014-06-13 17:18 #***************************************************************# import MySQL.connector from MySQL.connector import Fabric conn = MySQL.connector.connect( Fabric={"host" : "10.0.128.115", "port" : 32274, "username": "admin", "password" : "admin"
- 34. www.vmcd.org }, user="Oracle", password="Oracle", autocommit=True ) conn.set_property(group="Fabric_test1_global", mode=Fabric.MODE_READWRITE) cur = conn.cursor() cur.execute("USE employees") cur.execute( "alter table employees add nickname varchar(20)") [MySQL@pajk-super-master /home/MySQL] $MySQL --socket=/data/MySQL3334/data/MySQL.sock -e "desc employees.employees" +------------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +------------+-------------+------+-----+---------+-------+ | emp_no | int(11) | YES | | NULL | | | first_name | varchar(20) | YES | | NULL | | | last_name | varchar(20) | YES | | NULL | | | nickname | varchar(20) | YES | | NULL | | +------------+-------------+------+-----+---------+-------+
- 35. www.vmcd.org [MySQL@pajk-t-MySQL-master2 /home/MySQL] $MySQL --socket=/data/MySQL3334/data/MySQL.sock -e "desc employees.employees" +------------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +------------+-------------+------+-----+---------+-------+ | emp_no | int(11) | YES | | NULL | | | first_name | varchar(20) | YES | | NULL | | | last_name | varchar(20) | YES | | NULL | | | nickname | varchar(20) | YES | | NULL | | +------------+-------------+------+-----+---------+-------+ End: Mysq Fabric 结合了传统架构的 HA 方案与互联网 Sharding 方案 但是 Sharding 灵活性还不够。个人认为是 MHA+TDDL 方案的简集,在中小企业中可以 得到广泛的应用。 Ref: http://dev.MySQL.com/doc/MySQL-utilities/1.4/en/Fabric-quick-start-replication.html http://www.clusterdb.com/MySQL-Fabric/MySQL-Fabric-adding-high-availability-and-scaling-to-MySQL http://dev.MySQL.com/doc/MySQL-utilities/1.4/en/connector-j-Fabric-env.html http://docs.Oracle.com/cd/E17952_01/MySQL-utilities-1.4-en/connector-j-Fabric-env.html http://www.clusterdb.com/MySQL-Fabric/MySQL-Fabric-add-scaling-to-MySQL http://www.luocs.com/archives/862.html