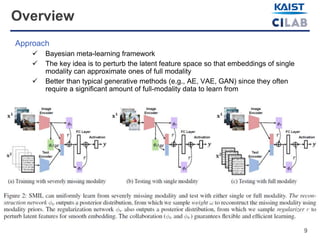
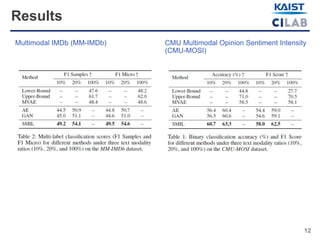
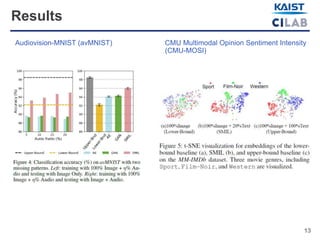
The document discusses advancements in multimodal learning techniques that effectively handle datasets with severely missing modalities, improving both flexibility and efficiency. By leveraging a Bayesian meta-learning framework, the proposed approach enables the reconstruction of missing features while maintaining performance comparable to models trained on complete datasets. The study evaluates its methods using various multimodal datasets, such as IMDb movie reviews and sentiment analysis clips.


![2
Background: Multimodal Learning
Multimodal learning utilizes complementary information contained in
multimodal data to improve the performance of various computer vision
tasks
Modality Fusion
Early fusion is a common method which fuses different modalities by
feature concatenation
Product operation allows more interactions among different modalities
during the fusion process
Missing Modalities for Multimodal Learning
Testing-time modality missing [1]
Learning with data from unpaired modalities [2]
[1] Tsai, Y.-H. H., Liang, P. P., Zadeh, A., Morency, L.-P., Salakhutdinov, R. Learning Factorized Multimodal Representations. ICLR 2019.
[2] Pham, H., et al., Found in translation: Learning robust joint representations by cyclic translations between modalities. AAAI 2019](https://image.slidesharecdn.com/multimodallearningwithseverelymissingmodality-220421043827/85/Multimodal-Learning-with-Severely-Missing-Modality-pptx-2-320.jpg)

![4
Background: Multimodal Generative
Models
Generative Models for Multimodal Learning
Cross-modal generation approaches learn a conditional generative model
over all modalities
E.g., conditional VAE (CVAE), conditional multimodal auto-encoder
Joint-modal generation approaches learn the joint distribution of
multimodal data
E.g., multimodal variational autoencoder (MVAE), multimodal VAE (JM-
VAE)
[1] Ngiam, J., Khosla, A., Kim, M., Nam, J., Lee, H., Ng, A. Y. Multimodal deep learning. ICML 2011.
[2] Tsai, Y.-H. H., Liang, P. P., Zadeh, A., Morency, L.-P., Salakhutdinov, R. Learning Factorized Multimodal Representations. ICLR 2019.
[3] Pham, H., et al., Found in translation: Learning robust joint representations by cyclic translations between modalities. AAAI 2019](https://image.slidesharecdn.com/multimodallearningwithseverelymissingmodality-220421043827/85/Multimodal-Learning-with-Severely-Missing-Modality-pptx-4-320.jpg)
![5
Multimodal Learning
Multimodal Learning
A common assumption in multimodal learning is the completeness of
training data, i.e., full modalities are available in all training examples [1]
However, such an assumption may not always hold in real world due to
privacy concerns or budget limitations
Incompleteness of test modalities [2, 3]
Incompleteness of train modalities X
Question: can we learn a multimodal model from an incomplete dataset
while its performance should as close as possible to the one that learns from
a full-modality dataset?
[1] Ngiam, J., Khosla, A., Kim, M., Nam, J., Lee, H., Ng, A. Y. Multimodal deep learning. ICML 2011.
[2] Tsai, Y.-H. H., Liang, P. P., Zadeh, A., Morency, L.-P., Salakhutdinov, R. Learning Factorized Multimodal Representations. ICLR 2019.
[3] Pham, H., et al., Found in translation: Learning robust joint representations by cyclic translations between modalities. AAAI 2019](https://image.slidesharecdn.com/multimodallearningwithseverelymissingmodality-220421043827/85/Multimodal-Learning-with-Severely-Missing-Modality-pptx-5-320.jpg)
![6
Multimodal Learning
Multimodal Learning Configurations
In [1], modalities are partially missing in testing examples
In [2], modalities are unpaired in training examples
This work consider an even more challenging setting where both training and
testing data contain samples that have missing modalities.
[1] Tsai, Y.-H. H., Liang, P. P., Zadeh, A., Morency, L.-P., Salakhutdinov, R. Learning Factorized Multimodal Representations. ICLR 2019.
[2] Pham, H., et al., Found in translation: Learning robust joint representations by cyclic translations between modalities. AAAI 2019](https://image.slidesharecdn.com/multimodallearningwithseverelymissingmodality-220421043827/85/Multimodal-Learning-with-Severely-Missing-Modality-pptx-6-320.jpg)