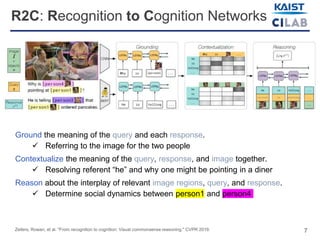
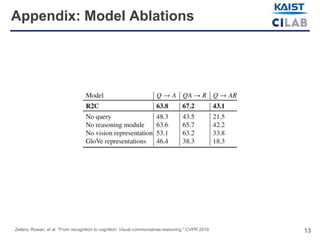
The document discusses visual commonsense reasoning (VCR), a new task combining visual question answering with rationales to improve machine understanding of images. It highlights the introduction of the VCR dataset containing 290k question-answer-rationale pairs, emphasizing the challenges faced by state-of-the-art models compared to human accuracy. A new model called R2C (recognition to cognition networks) aims to improve performance, successfully narrowing the gap between human and machine understanding.























![[NS][Lab_Seminar_240729]VQA-GNN: Reasoning with Multimodal Knowledge via Grap...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar240729vqa-gnn-240806103318-b8ebf4d7-thumbnail.jpg?width=640&height=640&fit=bounds)










































