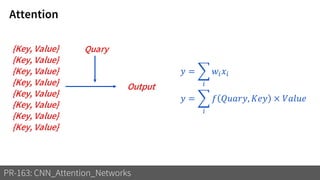
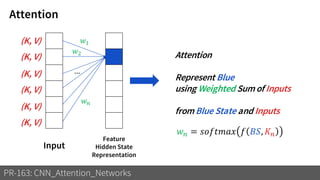
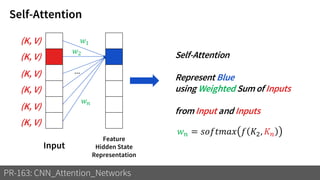
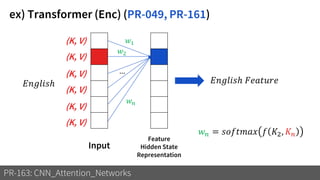
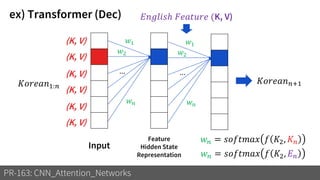
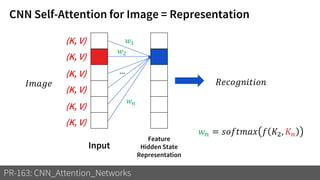
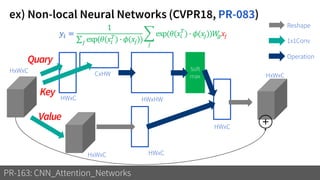
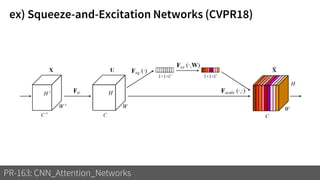
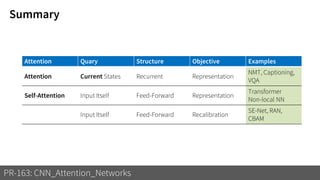
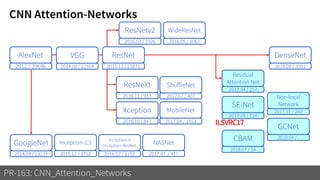
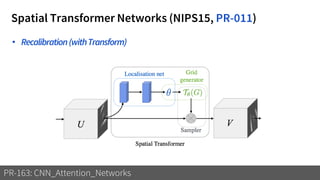
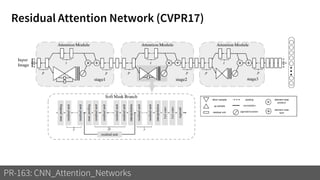
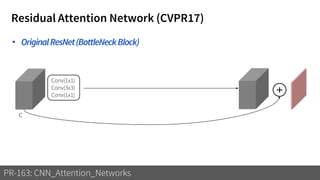
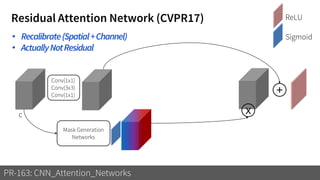
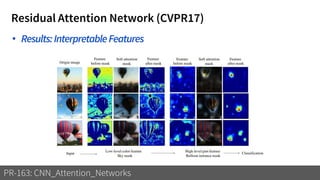
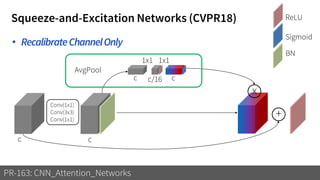
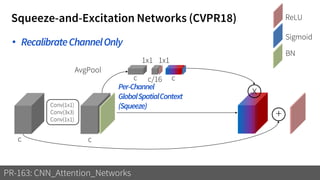
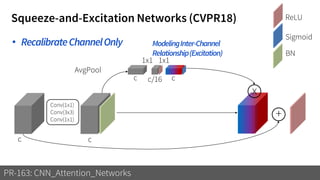
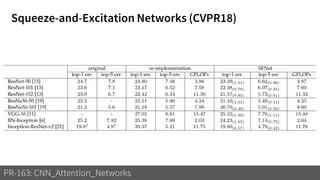
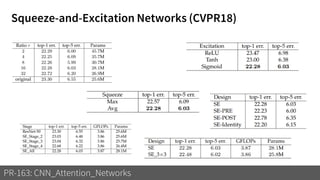
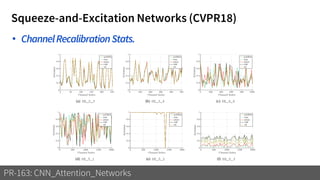
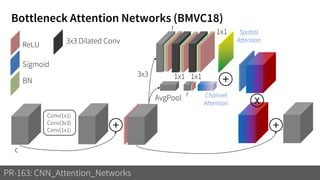
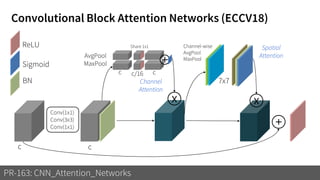
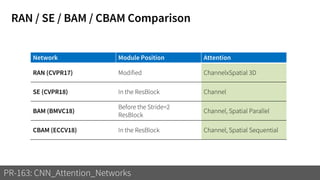
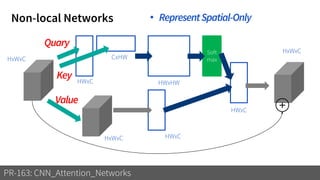
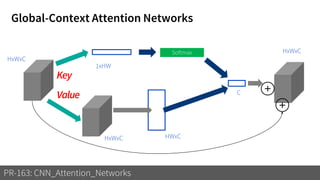
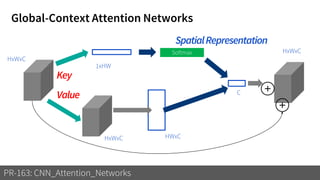
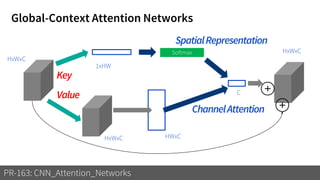
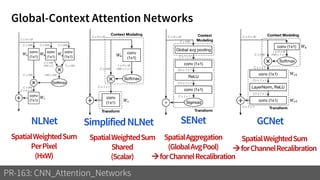
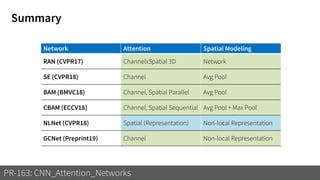
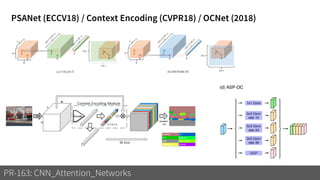
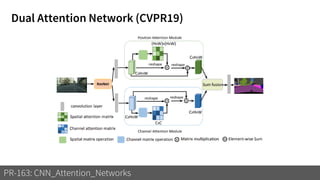
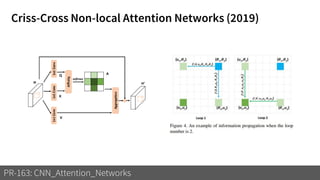
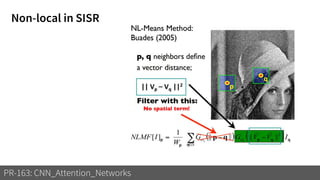
1) The document discusses different types of attention mechanisms in CNNs including self-attention and simplified attention for recalibration.
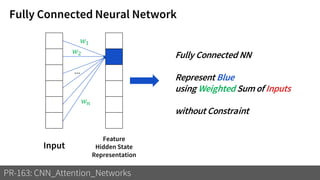
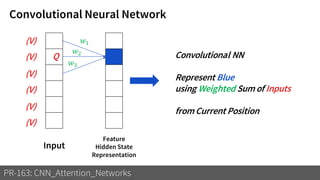
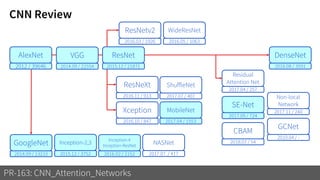
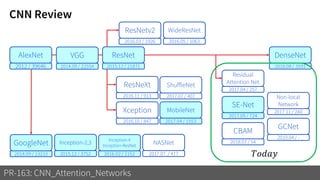
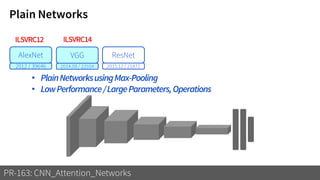
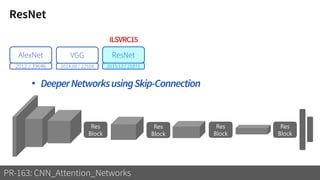
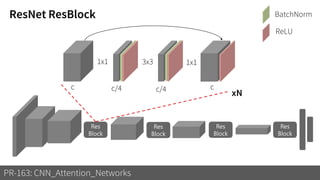
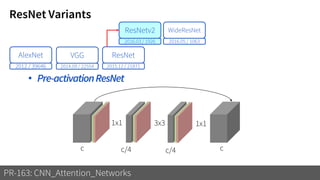
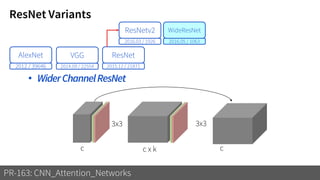
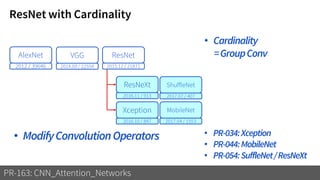
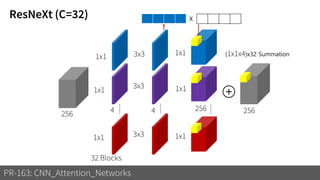
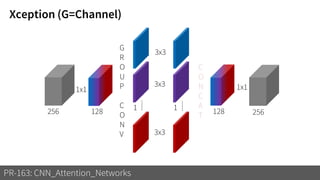
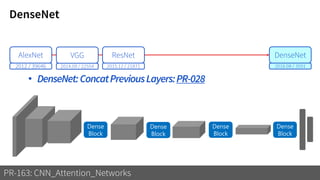
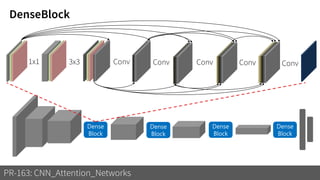
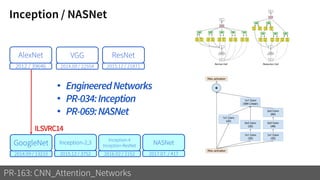
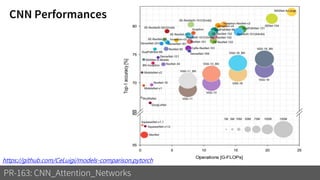
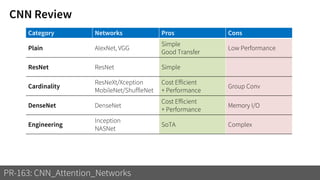
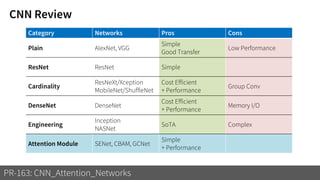
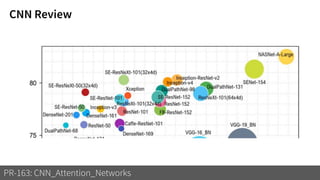
2) It reviews the evolution of CNN architectures including AlexNet, VGG, ResNet and variants, DenseNet, ResNeXt, Xception, MobileNet and ShuffleNet.
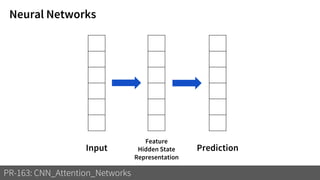
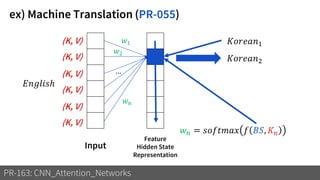
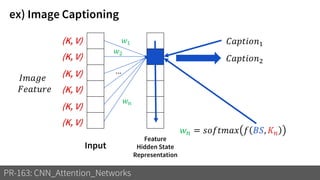
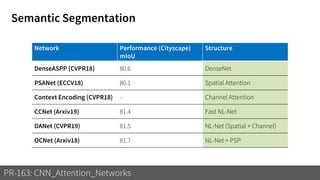
3) These attention mechanisms and CNN architectures are applied to tasks like image recognition, machine translation and image captioning.



































































![[CVPR 2018] OCR](https://cdn.slidesharecdn.com/ss_thumbnails/cvpr2018ocr-180817015947-thumbnail.jpg?width=640&height=640&fit=bounds)



























