Download as PDF, PPTX
![Day 4 Lecture 4
Multimodal
Deep Learning
Xavier Giró-i-Nieto
[course site]](https://image.slidesharecdn.com/dlsl2017d4l4multimodaldeeplearning-170127184643/85/Multimodal-Deep-Learning-D4L4-Deep-Learning-for-Speech-and-Language-UPC-2017-1-320.jpg)
![Day 4 Lecture 4
Multimodal
Deep Learning
Xavier Giró-i-Nieto
[course site]](https://image.slidesharecdn.com/dlsl2017d4l4multimodaldeeplearning-170127184643/75/Multimodal-Deep-Learning-D4L4-Deep-Learning-for-Speech-and-Language-UPC-2017-1-2048.jpg)









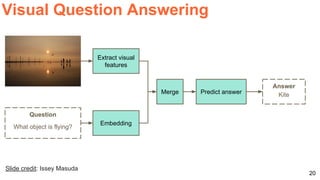
![19
Visual Question Answering
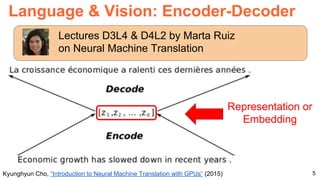
[z1
, z2
, … zN
] [y1
, y2
, … yM
]
“Is economic growth decreasing ?”
“Yes”
Encode
Encode
Decode](https://image.slidesharecdn.com/dlsl2017d4l4multimodaldeeplearning-170127184643/85/Multimodal-Deep-Learning-D4L4-Deep-Learning-for-Speech-and-Language-UPC-2017-19-320.jpg)
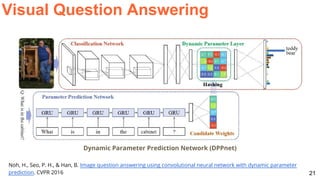


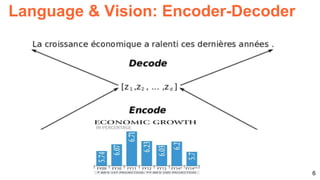
![26
100%0%
Humans
83,30%
UC Berkeley
& Sony
66,47%
Baseline
LSTM&CNN
54,06%
Baseline Nearest
neighbor
42,85%
Baseline Prior per
question type
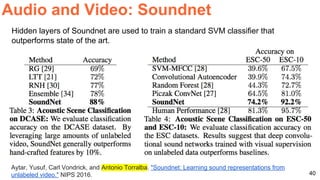
37,47%
Baseline All yes
29,88%
53,62%
I. Masuda-Mora, “Open-Ended Visual Question-Answering”. BSc ETSETB 2016. [Keras]
Challenges: Visual Question Answering](https://image.slidesharecdn.com/dlsl2017d4l4multimodaldeeplearning-170127184643/85/Multimodal-Deep-Learning-D4L4-Deep-Learning-for-Speech-and-Language-UPC-2017-26-320.jpg)
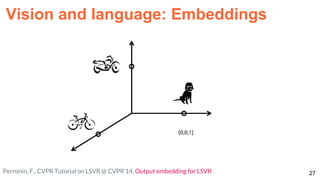
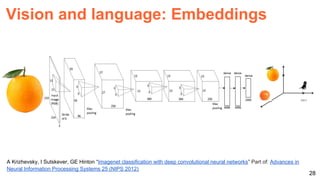

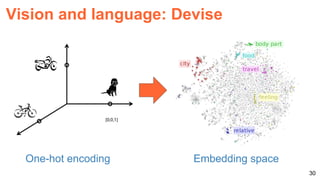
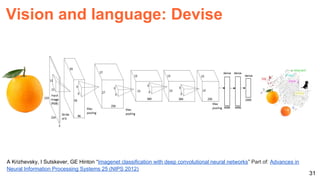








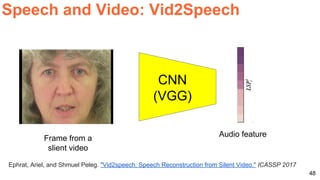

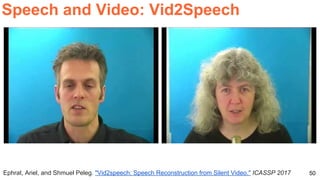

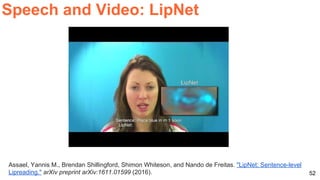
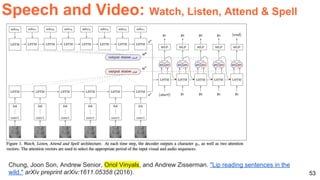
![57
Conclusions
[course site]](https://image.slidesharecdn.com/dlsl2017d4l4multimodaldeeplearning-170127184643/85/Multimodal-Deep-Learning-D4L4-Deep-Learning-for-Speech-and-Language-UPC-2017-57-320.jpg)



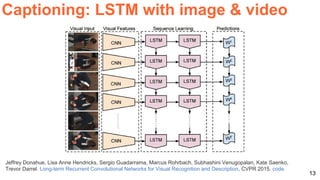
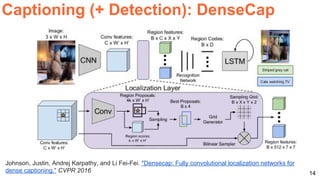
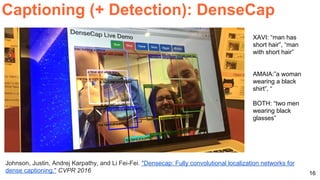
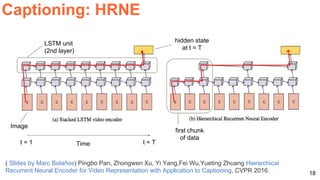
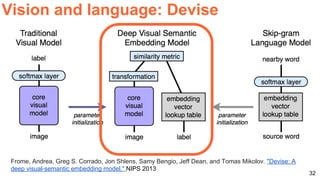
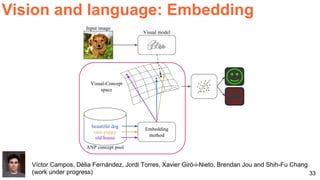
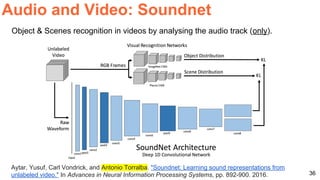
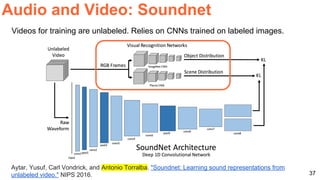
The document discusses various aspects of multimodal deep learning, including methods for combining text, audio, and visual information in tasks such as image captioning and visual question answering. It references several key research papers and techniques, such as neural machine translation, deep visual-semantic alignments, and sound representation learning. Additionally, it highlights advancements in embeddings and performance metrics across different models and techniques in the field.






























![ICASSP2017読み会 (Deep Learning III) [電通大 中鹿先生]](https://cdn.slidesharecdn.com/ss_thumbnails/icayominakashika-170628021331-thumbnail.jpg?width=640&height=640&fit=bounds)



































































