Download to read offline




![MILJS: JavaScript × Deep Learning
[Hidaka+, ICLR Workshop 2017]](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-5-2048.jpg)
![MILJS: JavaScript × Deep Learning
• Support for both learning and inference
• Support for nodes with GPGPUs
– Currently WebCL is utilized.
– Now working on WebGPU.
• Support for nodes w/o GPGPUs
• No requirements to install any software
– Even ResNet with 152 layers can be trained
[Hidaka+, ICLR Workshop 2017]](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-6-2048.jpg)
![WebDNN: Fastest Inference Framework on Web Browser
Optimizes trained models for inference only
• Caffe, Keras, Chainer
• IE, Edge, Safari, Chrome, Firefox on PCs and mobiles
• GPU computation
• Web camera
[Kikura+ 2017]](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-7-2048.jpg)
![Asymmetric Tri-training for Domain Adaptation
• Unsupervised domain adaptation
Trained on mnist → Works on SVHN?
– Ground-truth labels are associated with source (mnist)
– However, there are no labels for target (SVHN)
[Saito+, ICML 2017]](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-8-2048.jpg)
![Asymmetric Tri-training for Domain Adaptation
• Asymmetric Tri-training: pseudo labels for target domain
[Saito+, ICML 2017]](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-9-2048.jpg)
![Asymmetric Tri-training for Domain Adaptation
1st: Training on MNIST → Add pseudo labels for easy samples
2nd~: Training on MNIST+α→ Add more pseudo labels
eight
nine
[Saito+, ICML 2017]](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-10-2048.jpg)
![End-to-end learning for environmental sound classification
Existing methods for speech / sound recognition:
① Feature extraction: Fourier Transformation (log-mel features)
② Classification: CNN with the extracted feature map
[Tokozume+, ICASSP 2017]
①
②
Log-mel features are suitable for human speech; but for environmental sounds…?](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-11-2048.jpg)
![End-to-end learning for environmental sound classification
Proposed approach (EnvNet):
CNN for both ① feature map extraction and ② classification
[Tokozume+, ICASSP 2017]
①
②
Extracted “feature map”](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-12-2048.jpg)
![End-to-end learning for environmental sound classification
Comparison of accuracy [%] on ESC-50[Piczak, ACM MM 2015]
[Tokozume+, ICASSP 2017]
64.5 64.0
71.0
log-mel feature + CNN
[Piczak, MLSP 2015]
End-to-end CNN
(Ours)
End-to-end CNN &
log-mel feature + CNN
(Ours)
EnvNet can extract discriminative features for environmental sounds](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-13-2048.jpg)
![Multispectral Segmentation & Detection
• Robust Segmentation & Detection
– Daytime and nighttime
– Fog
• Use of multispectral images
– RGB
– Far-infrared (FIR)
– Mid-infrared (MIR)
– Near-infrared (NIR)
[Ha+, IROS 2017][Karasawa+, submitted to ACM MM 2017]
RGBMIR
NIRFIR](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-14-2048.jpg)
![• How to combine multispectral images?
– Just concatenate them to a multi-channel image?
– Develop some sophisticated methods?
• To capture multispectral images
– Develop a novel single camera
– Use different cameras
Low cost, but many problems:
• Camera parameters
• Capture timings
• Ours: Multispectral Fusion Network
– Baseline: SegNet [Badrinarayanan+, PAMI 2017]
– Independent encoders for each camera
Multispectral Segmentation & Detection[Ha+, IROS 2017][Karasawa+, submitted to ACM MM 2017]](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-15-2048.jpg)
![Multispectral Segmentation & Detection[Ha+, IROS 2017][Karasawa+, submitted to ACM MM 2017]](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-16-2048.jpg)
![Visual Question Answering (VQA)
Question answering system for
• Associated image
• Question by natural language
[Saito+, ICME 2017]
Q: Is it going to rain soon?
Ground Truth A: yes
Q: Why is there snow on one
side of the stream and clear
grass on the other?
Ground Truth A: shade](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-17-2048.jpg)
![Visual Question Answering (VQA)
After integrating for 𝑍𝐼+𝑄: usual classification
Question 𝑄
What objects are
found on the bed?
Answer 𝐴
bed sheets, pillow
Image 𝐼
Image feature
𝑥𝐼
Question feature
𝑥 𝑄
Integrated
vector
𝑧𝐼+𝑄
[Saito+, ICME 2017]
VQA = Multi-class classification](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-18-2048.jpg)
![Visual Question Answering (VQA)
Current advancement: improving how to integrate 𝑥𝐼 and 𝑥 𝑄
• Concatenation
e.g.) [Antol+, ICCV 2015]
• Summation
e.g.) Image feature (with attention) + Question feature
[Xu+Saenko, ECCV 2016]
• Multiplication
e.g.) Bilinear multiplication
[Fukui+, EMNLP 2016]
• This work: DualNet doing sum, multiply and concatenation
𝑧𝐼+𝑄 =
𝑥𝐼
𝑥 𝑄
𝑥𝐼 𝑥 𝑄
𝑥𝐼 𝑥 𝑄𝑧𝐼+𝑄 =
𝑧𝐼+𝑄 =
𝑧𝐼+𝑄 =
𝑥𝐼 𝑥 𝑄
𝑥𝐼 𝑥 𝑄
[Saito+, ICME 2017]](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-19-2048.jpg)
![Visual Question Answering (VQA)
VQA Challenge 2016 (in CVPR 2016)
Won the 1st place on abstract images w/o attention mechanism
[Saito+, ICME 2017]
Q: What fruit is yellow and brown?
A: banana
Q: How many screens are there?
A: 2
Q: What is the boy playing with?
A: teddy bear
Q: Are there any animals swimming in the
pond? A: no](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-20-2048.jpg)

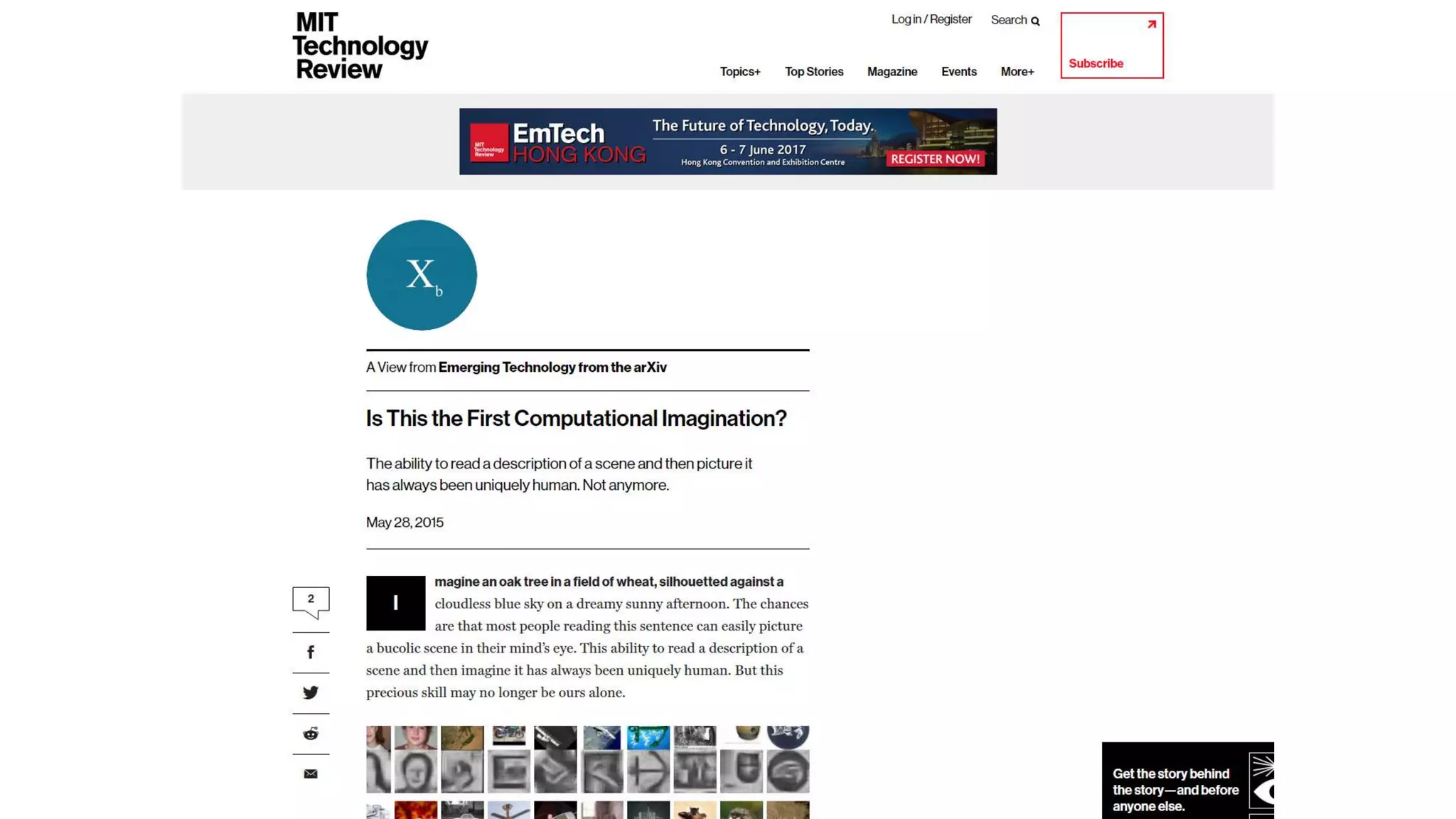
![[Ushiku+, ACMMM 2011]
Automatic Image Captioning](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-22-2048.jpg)

![Automatic Image Captioning [ACM MM 2012, ICCV 2015]
Group of people sitting
at a table with a dinner.
Tourists are standing on
the middle of a flat desert.](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-24-2048.jpg)
![Image Captioning + Sentiment Terms[Shin+, BMVC 2016]
A confused man in a
blue shirt is sitting on a
bench.
A man in a blue shirt
and blue jeans is
standing in the
overlooked water.
A zebra standing in a
field with a tree in the
dirty background.](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-25-2048.jpg)
![Image Captioning + Sentiment Terms
Two steps for adding a sentiment term
1. Usual image captioning using CNN+RNN
[Shin+, BMVC 2016]
The most probable noun is memorized](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-26-2048.jpg)
![Image Captioning + Sentiment Terms
Two steps for adding a sentiment term
1. Usual image captioning using CNN+RNN
2. Forced to predict sentiment term before the noun
[Shin+, BMVC 2016]](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-27-2048.jpg)
![Beyond Caption to Narrative
A man is holding a box of doughnuts.
Then he and a woman are standing next each other.
Then she is holding a plate of food.
[Shin+, ICIP 2016]](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-28-2048.jpg)
![Beyond Caption to Narrative [Shin+, ICIP 2016]
A man is
holding a box
of doughnuts.
he and a
woman are
standing next
each other.
she is holding
a plate of food. Narrative](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-29-2048.jpg)
![Beyond Caption to Narrative
A boat is floating on the water near a mountain.
And a man riding a wave on top of a surfboard.
Then he on the surfboard in the water.
[Shin+, ICIP 2016]](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-30-2048.jpg)
![Image Reconstruction [Kato+, CVPR 2014]
1d2d
3d
md
jd
kd
Nd
);( θdp
1d
2d 3d md
kd
Nd
jd Cat
𝐱𝑗 = 𝑓(𝛉𝑗)
Camera
Traditional pipeline for image classification
Extracting
local descriptors
Collecting
descriptors
Calculating
Global feature
Classifying
images](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-32-2048.jpg)
![Image Reconstruction [Kato+, CVPR 2014]
1d2d
3d
md
jd
kd
Nd
);( θdp
1d
2d 3d md
kd
Nd
jd Cat
𝐱𝑗 = 𝑓(𝛉𝑗)
Camera
Inversed problem: Image reconstruction from a label
Pot](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-33-2048.jpg)
![Image Reconstruction [Kato+, CVPR 2014]
cat (bombay) camera grand piano headphone joshua treepyramid wheel chairgramophone
Pot
Optimized arrangement using:
Global location cost + Adjacency cost
Other examples](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-34-2048.jpg)
![Video Generation
• Image generation is still challenging
Only successful for controlled settings:
– Human faces
– Birds
– Flowers
• Video generation is …
– Additionally requiring temporal consistency
– Extremely challenging
[Yamamoto+, ACMMM 2016]
[Vondrick+, NIPS 2016]
BEGAN
[Berthelot+, 2017 Mar.]
StackGAN
[Zhang+, 2016 Dec.]](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-36-2048.jpg)
![Video Generation
• This work: generating easy videos
– C3D (3D convolutional neural network)
for conditional generation with an input label
– tempCAE (temporal convolutional auto-encoder)
for regularizing video to improve its naturalness
[Yamamoto+, ACMMM 2016]](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-37-2048.jpg)
![Video Generation [Yamamoto+, ACMMM 2016]
Ours
(C3D+tempCAE)
Only C3D
Ours
(C3D+tempCAE)
Only C3D
Car runs
to left
Rocket
flies up](https://image.slidesharecdn.com/20170429machinelearning15minutes-170505012843/75/Recognize-Describe-and-Generate-Introduction-of-Recent-Work-at-MIL-38-2048.jpg)


The document discusses recent advancements in machine intelligence, particularly in automated journalism, object recognition, and content generation at the University of Tokyo. It highlights various techniques such as deep learning for classification, end-to-end learning for sound classification, multi-spectral image processing, and visual question answering systems. Additionally, the document covers applications in image and video captioning, reconstruction, and video generation, emphasizing the integration of machine intelligence in various domains.


![SSII2021 [OS2-03] 自己教師あり学習における対照学習の基礎と応用](https://cdn.slidesharecdn.com/ss_thumbnails/os2-04-210605061641-thumbnail.jpg?width=640&height=640&fit=bounds)













































![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)




![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)





![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)


