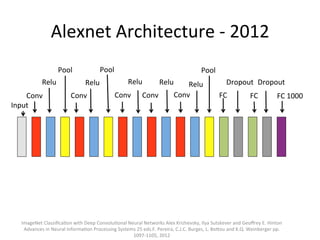
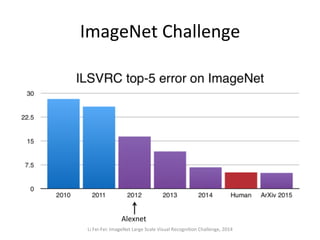
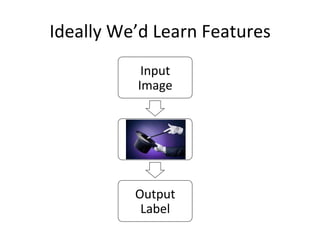
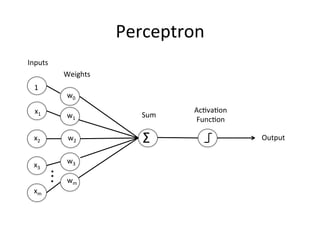
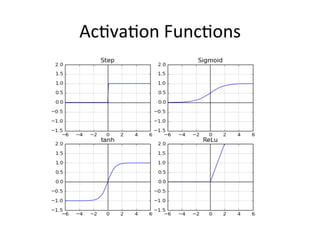
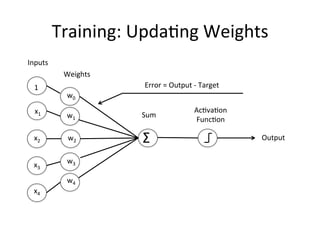
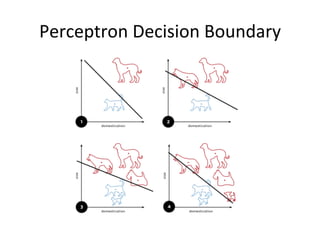
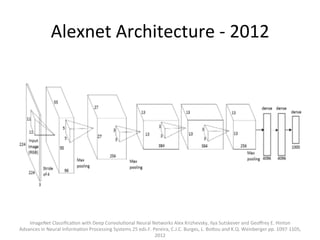
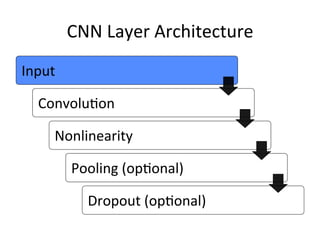
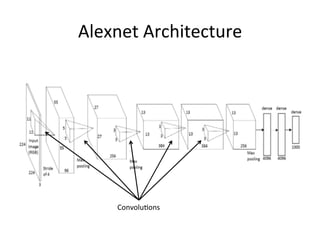
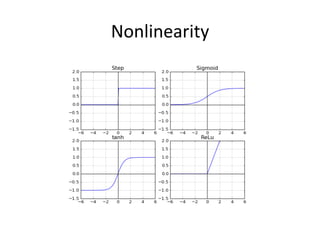
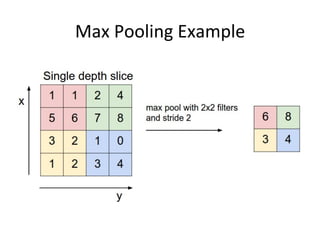
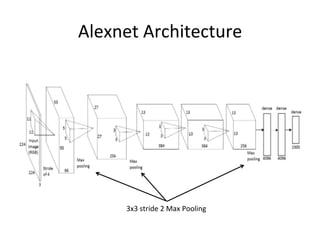
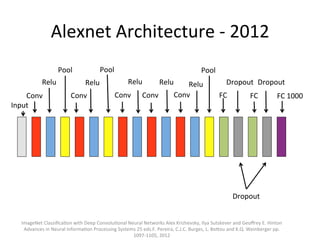
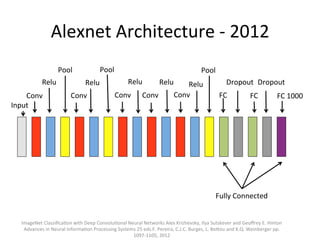
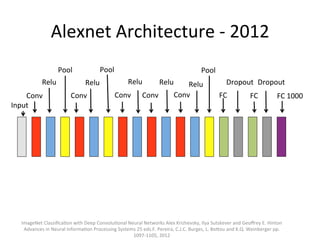
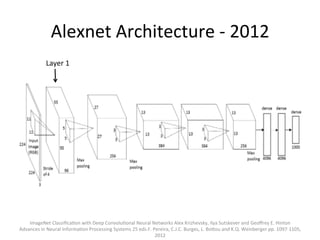
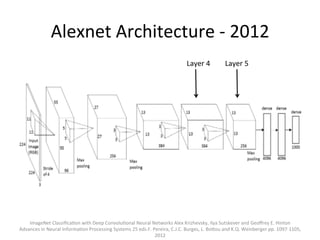
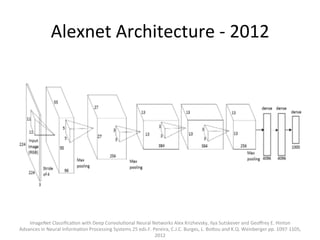
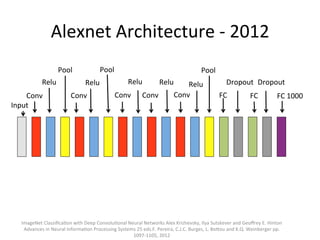
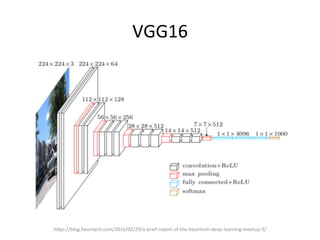
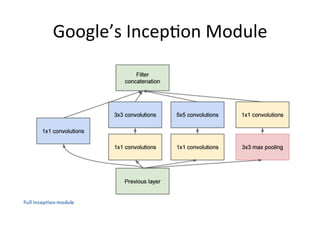
The document provides a comprehensive introduction to Convolutional Neural Networks (CNNs), describing their architecture and significance in tasks such as image classification and object recognition. It discusses key concepts like feature extraction, pooling, dropout, and the functionality of neural network layers, particularly in relation to AlexNet and other models. Additionally, the importance of learning representations in images and the evolution of performance metrics in challenges like ImageNet are highlighted.































































































![[Revised] Intro to CNN](https://cdn.slidesharecdn.com/ss_thumbnails/googletechsprinttalkcnnintro-200730141604-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragan Jerosimovic - The Anatomy of a Narrative Simulation.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vzputuprdqr6zwbrwdcw-1-dragan-jerosimovic-the-anatomy-of-a-narrative-simulation-260114111931-9d04fba2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Srba Markovic - From Pilot to Production: Overcoming AI Deplo...](https://cdn.slidesharecdn.com/ss_thumbnails/yjjmrtytmwbalxlba7px-4-srba-markovic-from-pilot-to-production-overcoming-ai-deployment-blockers-with-260114111931-4a892d44-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Ivica Milaric - The Future of Gaming and AI Tools.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/tijgzsmgse2kj2y5pzzp-5-ivica-milaric-the-future-of-gaming-x-ai-tools-260114111931-87c2b3ac-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Mijat Kustudic - Building Financial Intelligence with AI Agen...](https://cdn.slidesharecdn.com/ss_thumbnails/38y2lb5lse6wstegtvas-3-mijat-kustudic-building-financial-intelligence-with-ai-agents-260114111931-1a4783ce-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Stefan Brankovic - #ResumeIsDead. AI-Powered Interviews and C...](https://cdn.slidesharecdn.com/ss_thumbnails/qnmbsv0xq3uysdrq3sev-2-stefan-brankovic-job-bolt-260114111931-a065aa3d-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Nikola Vasiljevic - Player segmentation by combat playstyles ...](https://cdn.slidesharecdn.com/ss_thumbnails/mnvbf0yvrwaqsipzrrv3-2-nikola-vasiljevic-player-segmentation-by-playstyles-in-action-shooter-games-260114111931-b4d766cd-thumbnail.jpg?width=640&height=640&fit=bounds)


