Download as PDF, PPTX







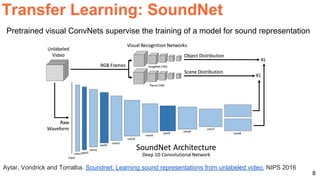
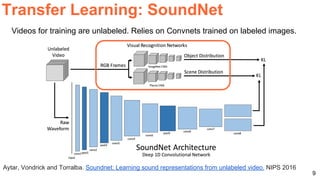




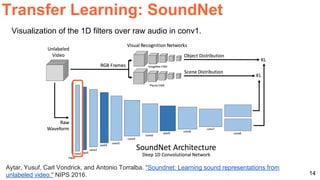

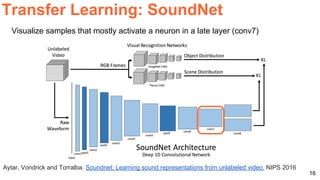




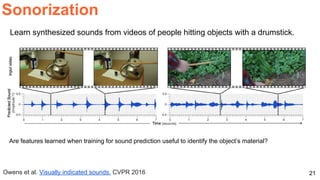


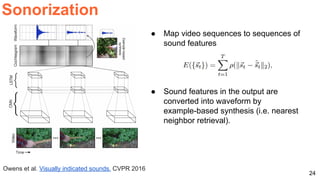






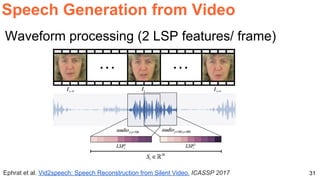



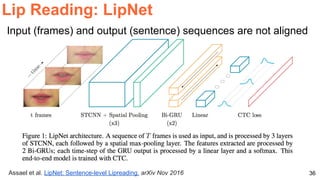



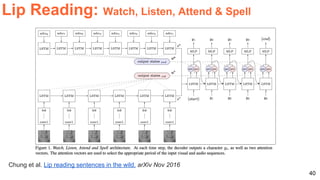
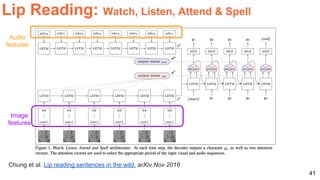
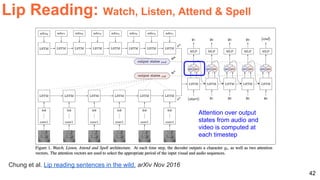
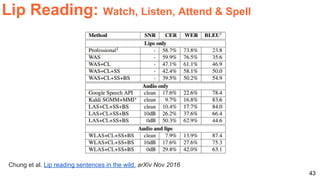
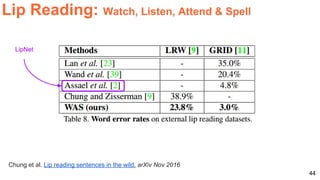
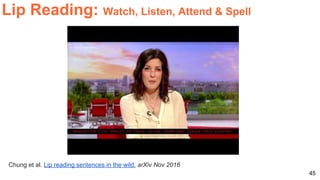


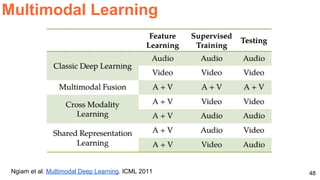
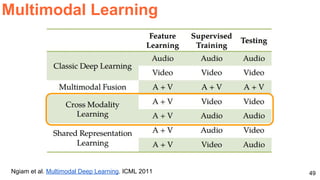
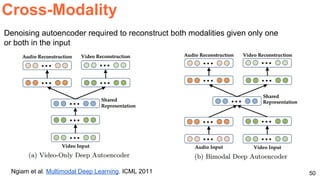

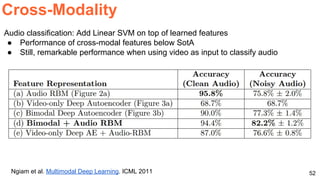
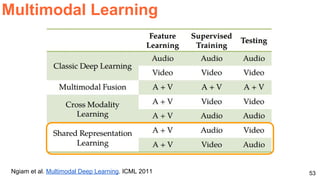
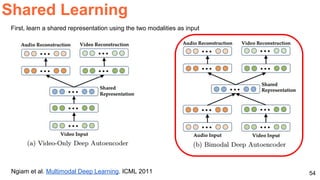
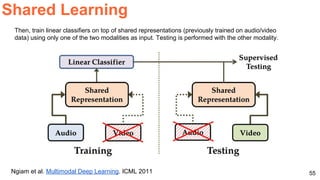
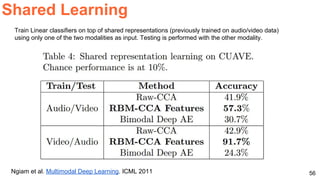

The document discusses various techniques in audio-visual learning, focusing on transfer learning, sonorization, speech generation, and lip reading. It references several studies, including SoundNet and Vid2Speech, which explore how sound can be learned from video data and vice versa. Additionally, the document highlights multimodal learning approaches and their effectiveness in improving audio and video classification tasks.




















































![[DSC Europe 25] Predrag Maletic - Scaling AI in Banking – Our Strategic Journ...](https://cdn.slidesharecdn.com/ss_thumbnails/qu2onv0aruwlvqtygmxx-predrag-maletic-scaling-ai-in-banking-260123083019-6cf1da1d-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DSC Europe 25] Ekaterina Bubenko - Behind the Curtain: How Data Roles Collab...](https://cdn.slidesharecdn.com/ss_thumbnails/anmv6x8dstqbbzchoklr-ekaterina-bubenko-behind-the-curtain-how-data-roles-collaborate-in-the-ai-era-a-260123083019-4b252ec7-thumbnail.jpg?width=640&height=640&fit=bounds)