More Related Content

PDF
ここまで来た&これから来る音声合成 (明治大学 先端メディアコロキウム) 
PDF

PPTX
独立性に基づくブラインド音源分離の発展と独立低ランク行列分析 History of independence-based blind source sep... 
PDF

PDF
HMMに基づく日本人英語音声合成における中学生徒の英語音声を用いた評価 
PPTX
音響メディア信号処理における独立成分分析の発展と応用, History of independent component analysis for sou... 
PPTX
![[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten...](https://cdn.slidesharecdn.com/ss_thumbnails/20180914iwasawa-180919025635-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Life-Long Disentangled Representation Learning with Cross-Domain Laten... What's hot

PDF
日本音響学会2017秋 ”Moment-matching networkに基づく一期一会音声合成における発話間変動の評価” 
PDF

PDF
GAN-based statistical speech synthesis (in Japanese) 
PDF

PDF

PDF
Attentionの基礎からTransformerの入門まで 
PDF

PDF

PDF

PPTX
【DL輪読会】ViT + Self Supervised Learningまとめ 
PPTX

PPTX
論文紹介 wav2vec: Unsupervised Pre-training for Speech Recognition 
PDF

PDF
環境音の特徴を活用した音響イベント検出・シーン分類 
PDF

PPTX
独立低ランク行列分析に基づく音源分離とその発展(Audio source separation based on independent low-rank... 
PDF
Transformerを用いたAutoEncoderの設計と実験 
ODP
![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)
PPTX
[DL輪読会]Flow-based Deep Generative Models 
PDF
z変換をやさしく教えて下さい (音響学入門ペディア) Viewers also liked

PPTX

PDF

PDF

PDF

PDF

PPTX
Koyama ASA ASJ joint meeting 2016 
PDF

PPTX
Discriminative SNMF EA201603 
PDF

PPTX
Koyama AES Conference SFC 2016 
PDF

PPTX
Hybrid NMF APSIPA2014 invited 
PDF
More from Shinnosuke Takamichi

PDF
リアルタイムDNN音声変換フィードバックによるキャラクタ性の獲得手法 
PDF
短時間発話を用いた話者照合のための音声加工の効果に関する検討 
PDF
JTubeSpeech: 音声認識と話者照合のために YouTube から構築される日本語音声コーパス 
PDF

PDF

PDF
差分スペクトル法に基づく DNN 声質変換の計算量削減に向けたフィルタ推定 
PDF

PDF
論文紹介 Unsupervised training of neural mask-based beamforming 
PDF
J-KAC:日本語オーディオブック・紙芝居朗読音声コーパス 
PDF
話者V2S攻撃: 話者認証から構築される 声質変換とその音声なりすまし可能性の評価 
PDF

PDF
P J S: 音素バランスを考慮した日本語歌声コーパス 
PDF
ユーザ歌唱のための generative moment matching network に基づく neural double-tracking 
PDF
音響モデル尤度に基づくsubword分割の韻律推定精度における評価 
PDF
Interspeech 2020 読み会 "Incremental Text to Speech for Neural Sequence-to-Sequ... 
PDF
End-to-end 韻律推定に向けた DNN 音響モデルに基づく subword 分割 
PDF
論文紹介 SANTLR: Speech Annotation Toolkit for Low Resource Languages 
PDF
音声合成・変換の国際コンペティションへの 参加を振り返って 
PDF
論文紹介 Building the Singapore English National Speech Corpus 
PDF
サブバンドフィルタリングに基づくリアルタイム広帯域DNN声質変換の実装と評価 Moment matching networkを用いた音声パラメータのランダム生成の検討
- 1.
- 2.
- 3.
/13
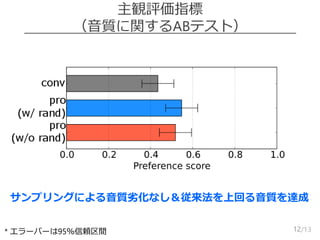
通常の音声合成
(Mean squared errorの最小化)
3
Meansquared
error
Linguistic
feats.
Static-delta
mean vectors
⋯
⋯
⋯
⋯
time
𝑡 = 1
⋯
⋯
⋯
⋯
⋯
time
𝑡 = 𝑇
⋯
Generated
speech
params.
Natural
speech
params.
Parameter
generation
⋯
[Wu et al., 2016.]
𝒚𝒚
𝒙
条件付き分布𝑃 𝒚|𝒙 として正規分布を仮定した最尤推定
- 4.
- 5.
/13
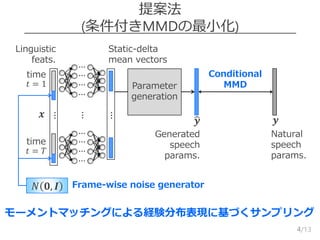
MMD (Maximum MeanDiscrepancy)
5
2つのデータセットの統計量の不一致指標
Moment-matching network [Li et al., 2015.]
– MMDを最小化するように、ノイズ入力のDNNを学習
𝑁 𝟎, 𝑰
𝒚
𝒚
MMD = Tr 𝟏 ⋅ 𝑲 𝒚,𝒚 + Tr 𝟏 ⋅ 𝑲 𝒚,𝒚 − 2Tr 𝟏 ⋅ 𝑲 𝒚,𝒚
𝒚, 𝒚 のグラム行列 𝒚, 𝒚 𝒚, 𝒚
⋯
⋯
⋯
⋯
- 6.
/13
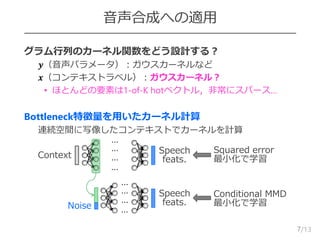
条件付きMMD (CMMD: ConditionalMMD)
条件付き分布の統計量の不一致を計算 [Ren et al., 2016.]
Conditional moment-matching network [Ren et al., 2016.]
– CMMDを最小化するように、 𝒙 &ノイズを入力とするDNNを学習
6
𝒙, 𝒙 のグラム行列の逆行列を含む行列
𝑁 𝟎, 𝑰
𝒚
𝒙
⋯
⋯
⋯
⋯
𝒚
CMMD = Tr 𝑳 𝒙 ⋅ 𝑲 𝒚,𝒚 + Tr 𝑳 𝒙 ⋅ 𝑲 𝒚,𝒚 − 2Tr 𝑳 𝒙 ⋅ 𝑲 𝒚,𝒚
𝒙
- 7.
- 8.
- 9.
/13
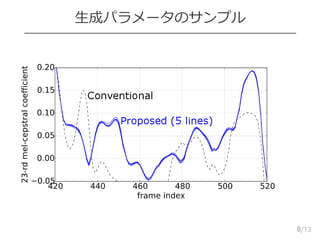
従来手法との比較
9
項目 従来法 提案法
確率密度関数Gaussian or GMM
(mixture density nets)
より複雑な分布
サンプリング 全共分散の正規分布
(trajectory model)
単純な事前分布
最適化問題 ミニマックス問題
(GAN [敵対的学習] )
最小化問題
従来法との関連 Divergenceに関連 (尤度比)
(GAN: Jensen-Shannon div.)
GV/MSに関連
(モーメント差)
Anti-spoofingの詐称 Replay-attack検出技術で検出
(最尤生成)
ランダム生成で
検出を緩和
[スペースの都合により引用を省略]
* GV/MS: 系列内変動/変調スペクトル
* GMM: 混合正規分布モデル
- 10.
- 11.
/13
実験条件
11
項目 値・設定
学習データ 音素バランス450文/話者× 5話者
評価データ 53文/話者 × 1話者
入力特徴量 274次元コンテキスト + 5次元話者ID
出力特徴量 40次元メルケプストラム+動的特徴量(計120次元)
Bottleneck特徴量 128次元
入力ノイズ 3次元/フレーム.正規分布からランダム生成
ネットワーク構造 Feed-Forward, 131 – 512×3 (ReLU) – 120 (Linear)
評価対象
conv:従来のdeep neural network音声合成で最尤生成 [Zen et al., 2013.]
pro (w/ rand): 提案法(ランダム生成)
pro (w/o rand): 提案法(ノイズ項を最尤推定で固定して生成)
- 12.
- 13.


![/13
概要
目的: 自然音声のように「同一テキストでも発話毎に
音声特徴量が異なる」音声合成システム
– 同一テキストでも発話毎にスペクトルは違う [Inukai et al., 2013.]
– この音声のランダム性(発話間変動)を合成音声に持たせたい
提案:Moment-matching networkを用いた音声合成法
– 自然音声と合成音声のモーメントを揃えるようにDNNを学習
– サンプリングによる音声パラメータ生成
2
最尤生成と比較して音質劣化なしで,サンプリング生成を可能に](https://image.slidesharecdn.com/slide-170317023315/85/Moment-matching-network-2-320.jpg)
![/13
通常の音声合成
(Mean squared errorの最小化)
3
Mean squared
error
Linguistic
feats.
Static-delta
mean vectors
⋯
⋯
⋯
⋯
time
𝑡 = 1
⋯
⋯
⋯
⋯
⋯
time
𝑡 = 𝑇
⋯
Generated
speech
params.
Natural
speech
params.
Parameter
generation
⋯
[Wu et al., 2016.]
𝒚𝒚
𝒙
条件付き分布𝑃 𝒚|𝒙 として正規分布を仮定した最尤推定](https://image.slidesharecdn.com/slide-170317023315/85/Moment-matching-network-3-320.jpg)
![/13
MMD (Maximum Mean Discrepancy)
5
2つのデータセットの統計量の不一致指標
Moment-matching network [Li et al., 2015.]
– MMDを最小化するように、ノイズ入力のDNNを学習
𝑁 𝟎, 𝑰
𝒚
𝒚
MMD = Tr 𝟏 ⋅ 𝑲 𝒚,𝒚 + Tr 𝟏 ⋅ 𝑲 𝒚,𝒚 − 2Tr 𝟏 ⋅ 𝑲 𝒚,𝒚
𝒚, 𝒚 のグラム行列 𝒚, 𝒚 𝒚, 𝒚
⋯
⋯
⋯
⋯](https://image.slidesharecdn.com/slide-170317023315/85/Moment-matching-network-5-320.jpg)
![/13
条件付きMMD (CMMD: Conditional MMD)
条件付き分布の統計量の不一致を計算 [Ren et al., 2016.]
Conditional moment-matching network [Ren et al., 2016.]
– CMMDを最小化するように、 𝒙 &ノイズを入力とするDNNを学習
6
𝒙, 𝒙 のグラム行列の逆行列を含む行列
𝑁 𝟎, 𝑰
𝒚
𝒙
⋯
⋯
⋯
⋯
𝒚
CMMD = Tr 𝑳 𝒙 ⋅ 𝑲 𝒚,𝒚 + Tr 𝑳 𝒙 ⋅ 𝑲 𝒚,𝒚 − 2Tr 𝑳 𝒙 ⋅ 𝑲 𝒚,𝒚
𝒙](https://image.slidesharecdn.com/slide-170317023315/85/Moment-matching-network-6-320.jpg)
![/13
従来手法との比較
9
項目 従来法 提案法
確率密度関数 Gaussian or GMM
(mixture density nets)
より複雑な分布
サンプリング 全共分散の正規分布
(trajectory model)
単純な事前分布
最適化問題 ミニマックス問題
(GAN [敵対的学習] )
最小化問題
従来法との関連 Divergenceに関連 (尤度比)
(GAN: Jensen-Shannon div.)
GV/MSに関連
(モーメント差)
Anti-spoofingの詐称 Replay-attack検出技術で検出
(最尤生成)
ランダム生成で
検出を緩和
[スペースの都合により引用を省略]
* GV/MS: 系列内変動/変調スペクトル
* GMM: 混合正規分布モデル](https://image.slidesharecdn.com/slide-170317023315/85/Moment-matching-network-9-320.jpg)

![/13
実験条件
11
項目 値・設定
学習データ 音素バランス450文/話者 × 5話者
評価データ 53文/話者 × 1話者
入力特徴量 274次元コンテキスト + 5次元話者ID
出力特徴量 40次元メルケプストラム+動的特徴量(計120次元)
Bottleneck特徴量 128次元
入力ノイズ 3次元/フレーム.正規分布からランダム生成
ネットワーク構造 Feed-Forward, 131 – 512×3 (ReLU) – 120 (Linear)
評価対象
conv:従来のdeep neural network音声合成で最尤生成 [Zen et al., 2013.]
pro (w/ rand): 提案法(ランダム生成)
pro (w/o rand): 提案法(ノイズ項を最尤推定で固定して生成)](https://image.slidesharecdn.com/slide-170317023315/85/Moment-matching-network-11-320.jpg)