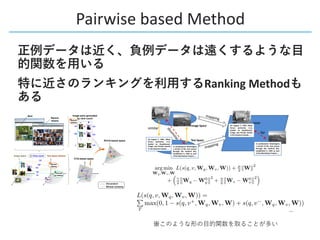
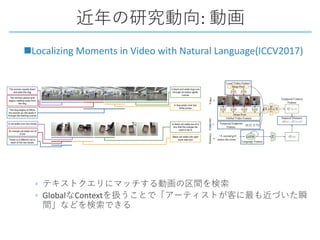
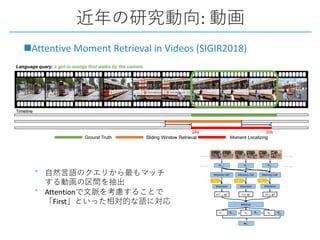
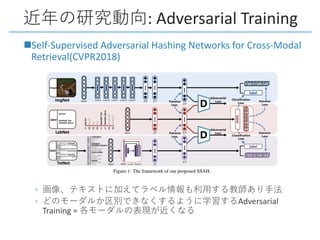
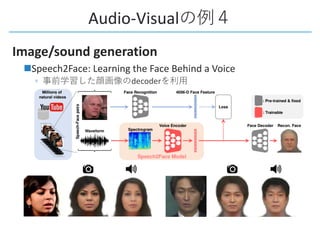
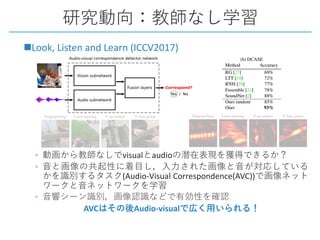
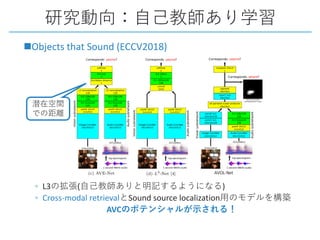
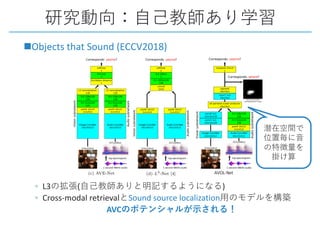
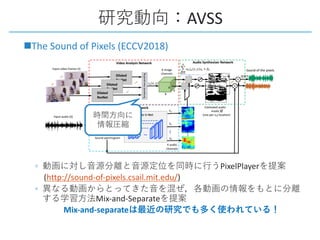
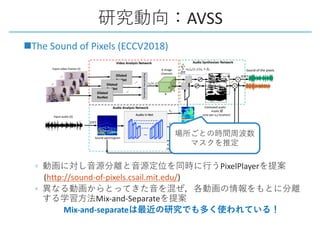
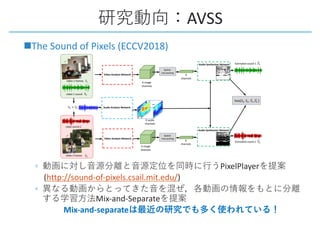
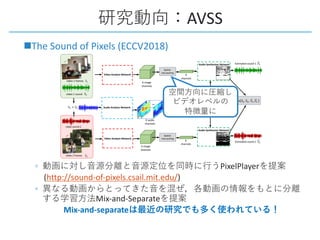
This document provides a survey of research on cross-modal embedding and retrieval between different media types such as text, images, video, and audio. It discusses several key areas including cross-modal retrieval which aims to retrieve relevant items across media types, audio-visual embedding to learn joint representations of audio and video, and applications such as sound localization, generation, and separation using audio-visual models. The document also summarizes several influential papers that use techniques such as adversarial training, consistency losses, and multimodal pretraining.






























![[DL輪読会]Convolutional Conditional Neural Processesと Neural Processes Familyの紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20191220readingpaperconvcnp-191220034420-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Multi-Modal and Multi-Domain Embedding Learning for Fashion Retrieval ...](https://cdn.slidesharecdn.com/ss_thumbnails/20181207dlpapersgoto-181207011756-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)














![[DL輪読会]The Neuro-Symbolic Concept Learner: Interpreting Scenes, Words, and Se...](https://cdn.slidesharecdn.com/ss_thumbnails/theneuro-symbolicconceptlearnerinterpretingsceneswordsandsentencesfromnaturalsupervision-190906012005-thumbnail.jpg?width=640&height=640&fit=bounds)









![[NS][Lab_Seminar_250609]Audio-Visual Semantic Graph Network for Audio-Visual ...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar250609avsgn-250609200005-6fb5812c-thumbnail.jpg?width=640&height=640&fit=bounds)




































