Download as PDF, PPTX
![1
DEEP
LEARNING
SUMMIT
London
21 September 2017
Xavier Giro-i-Nieto
xavier.giro@upc.edu
Associate Professor
Universitat Politecnica de Catalunya
Technical University of Catalonia
One Perceptron
to Rule them All:
Deep Learning for Multimedia
#REWORKDL
@DocXavi[Slides on GDrive]](https://image.slidesharecdn.com/reworklondon2017shortoneperceptrontorulethemall-170921071245/75/One-Perceptron-to-Rule-Them-All-Re-Work-Deep-Learning-Summit-London-2017-1-2048.jpg)


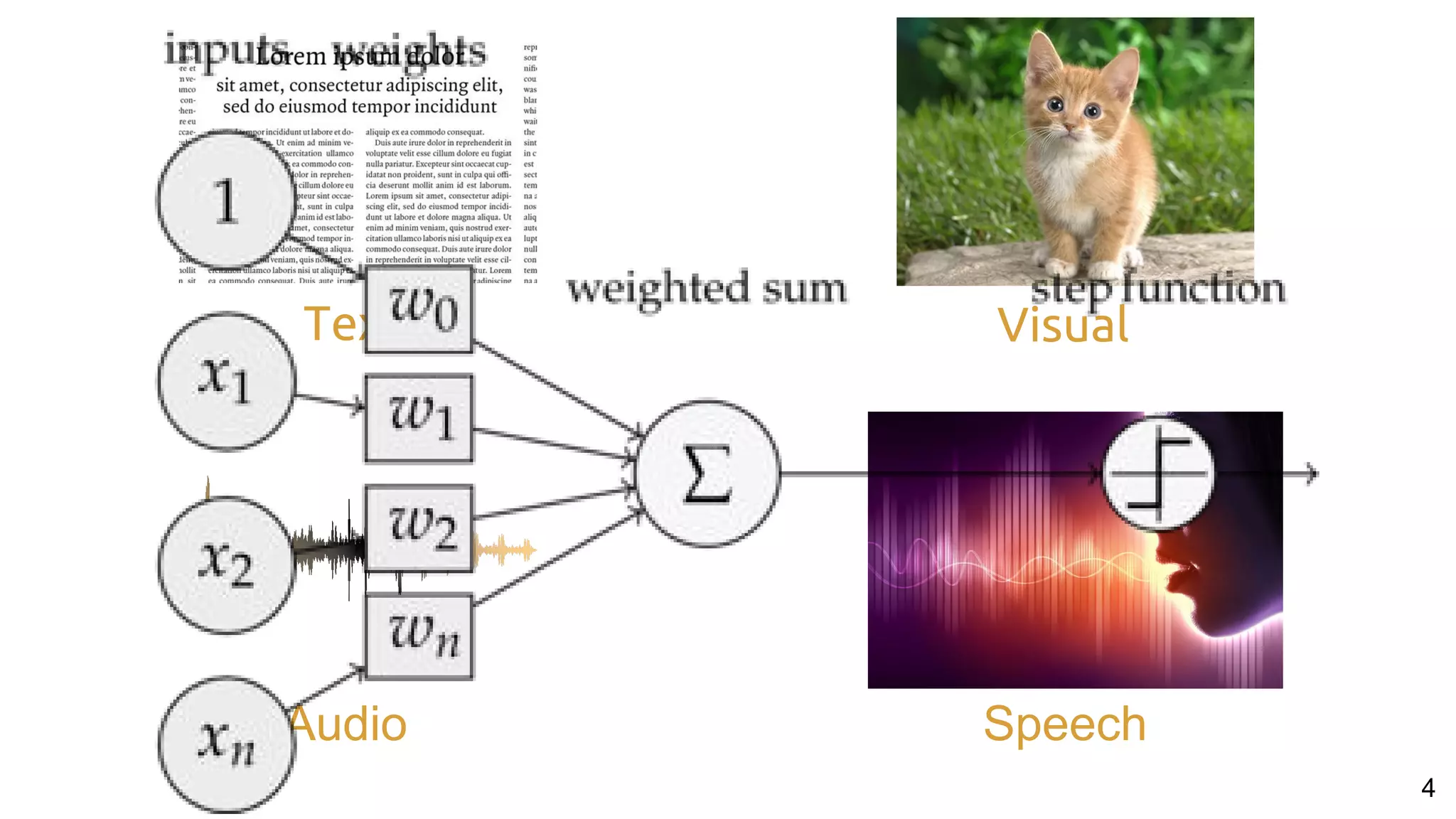
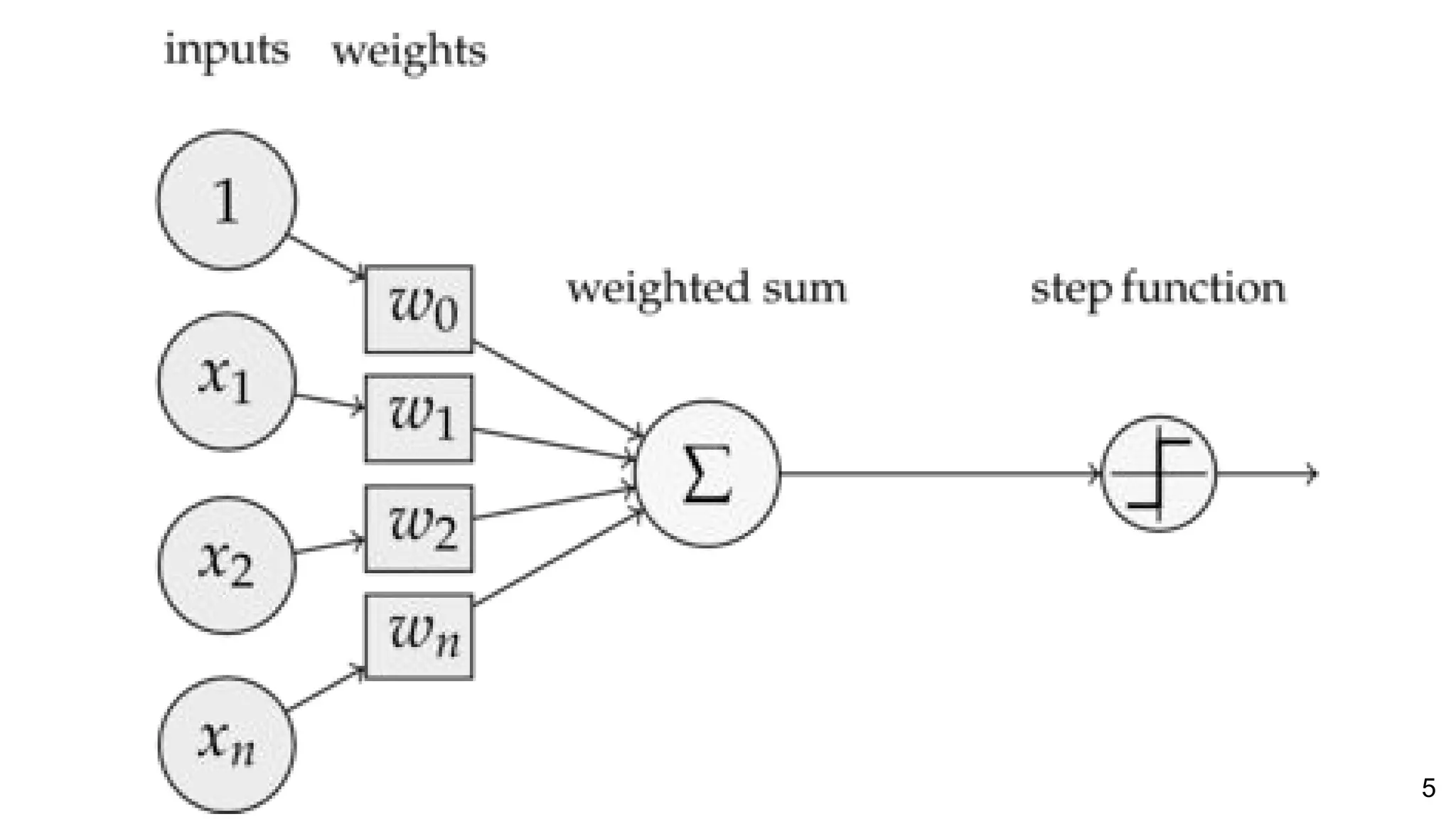
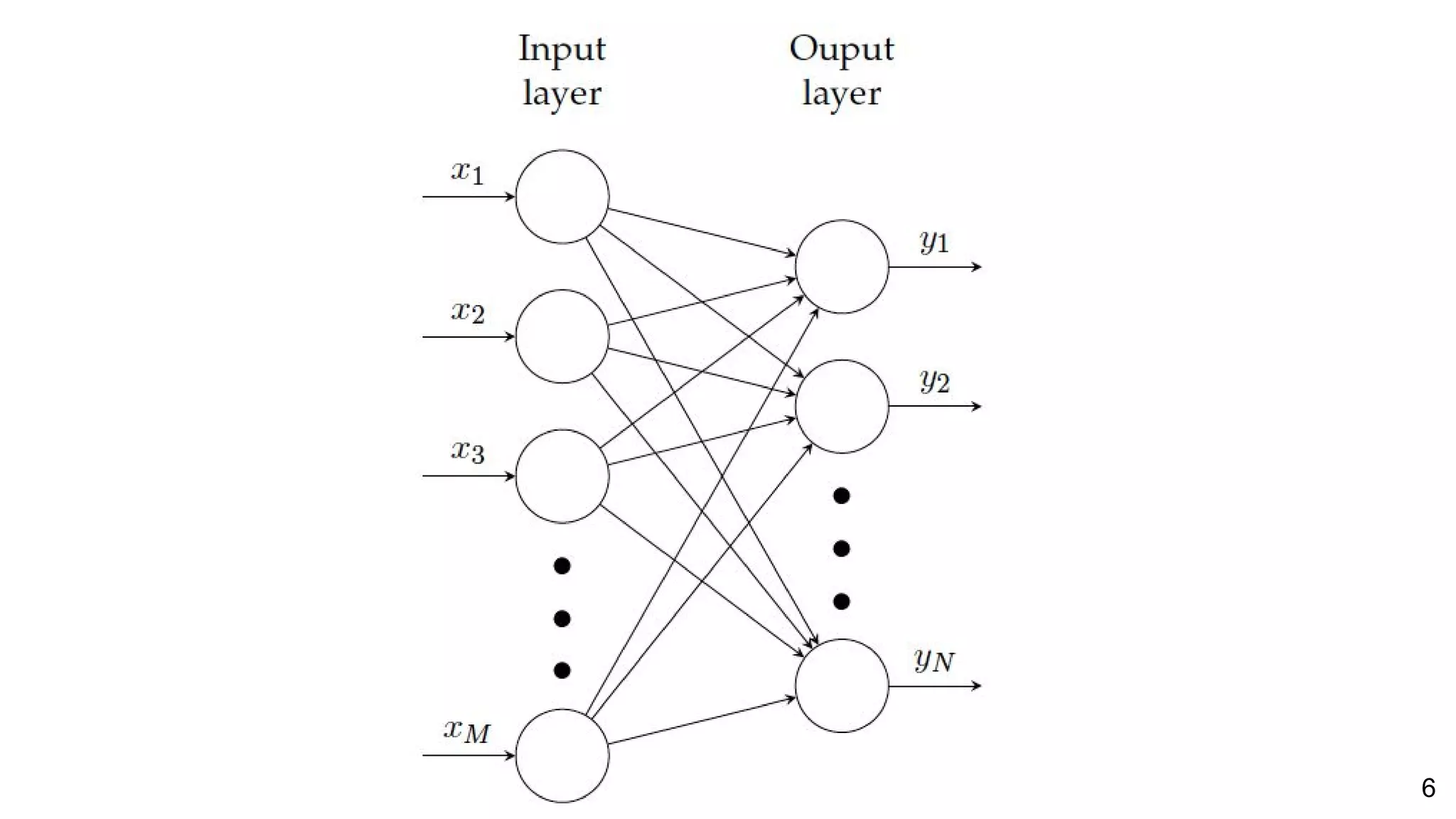
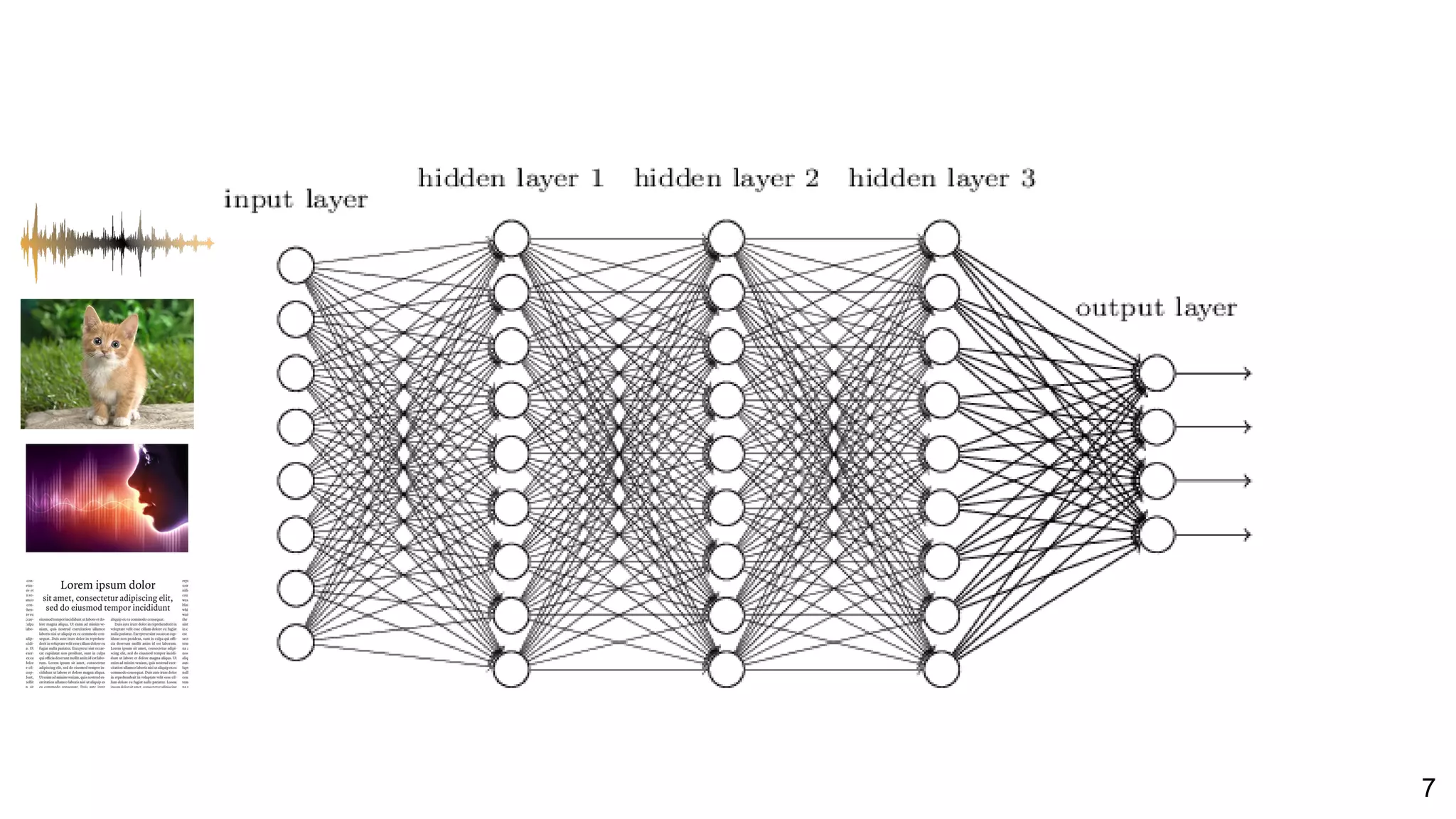









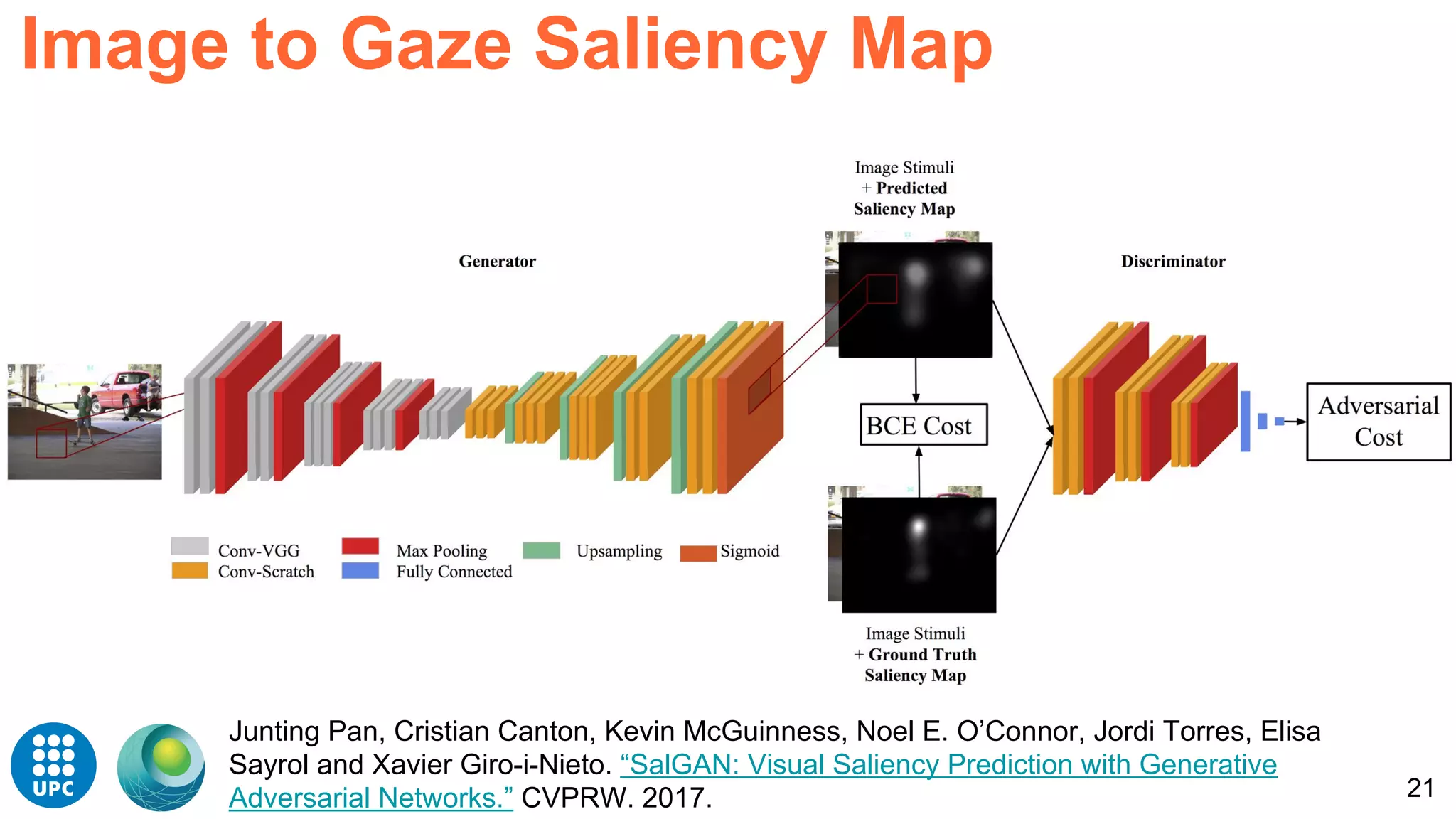
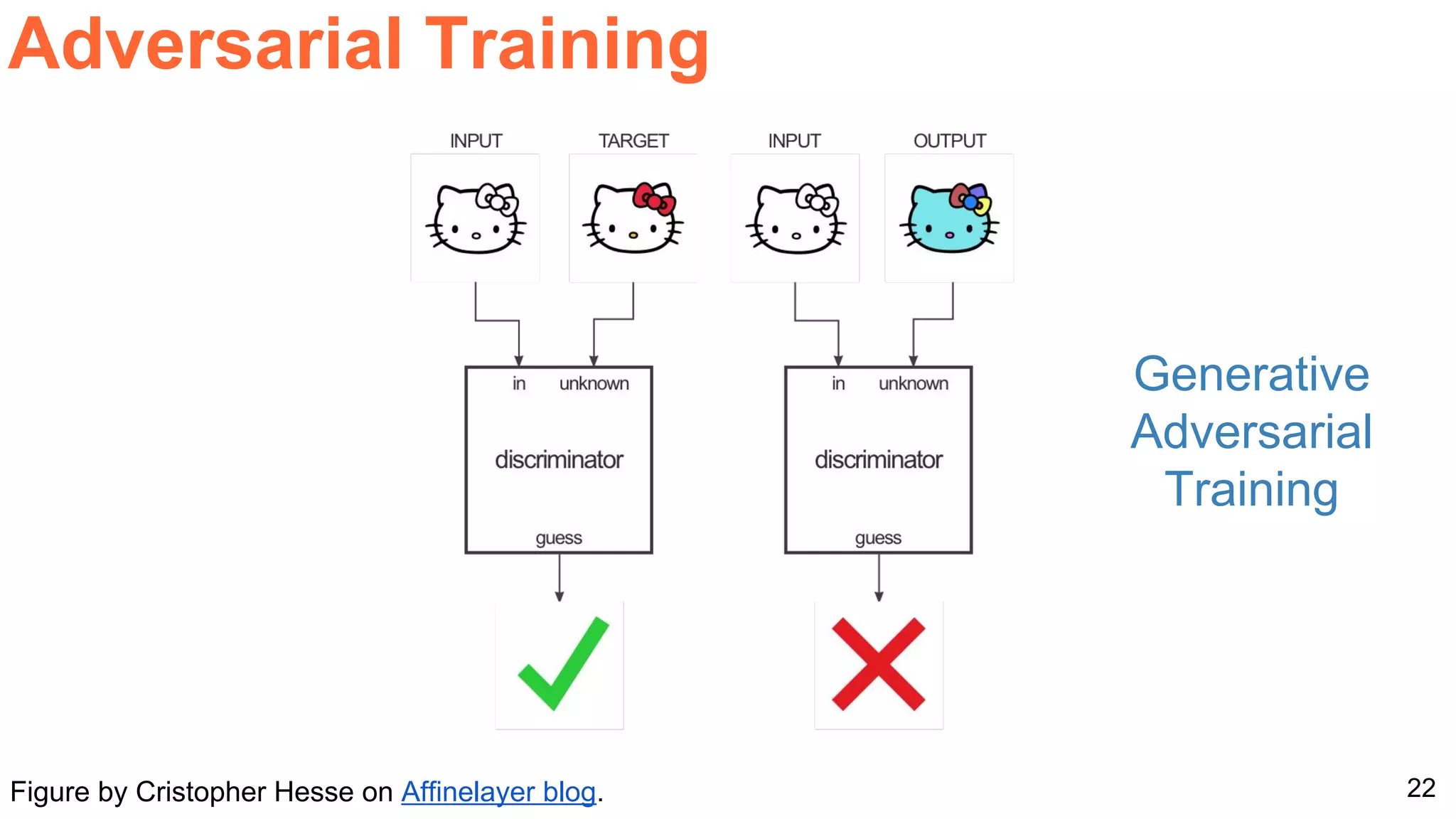


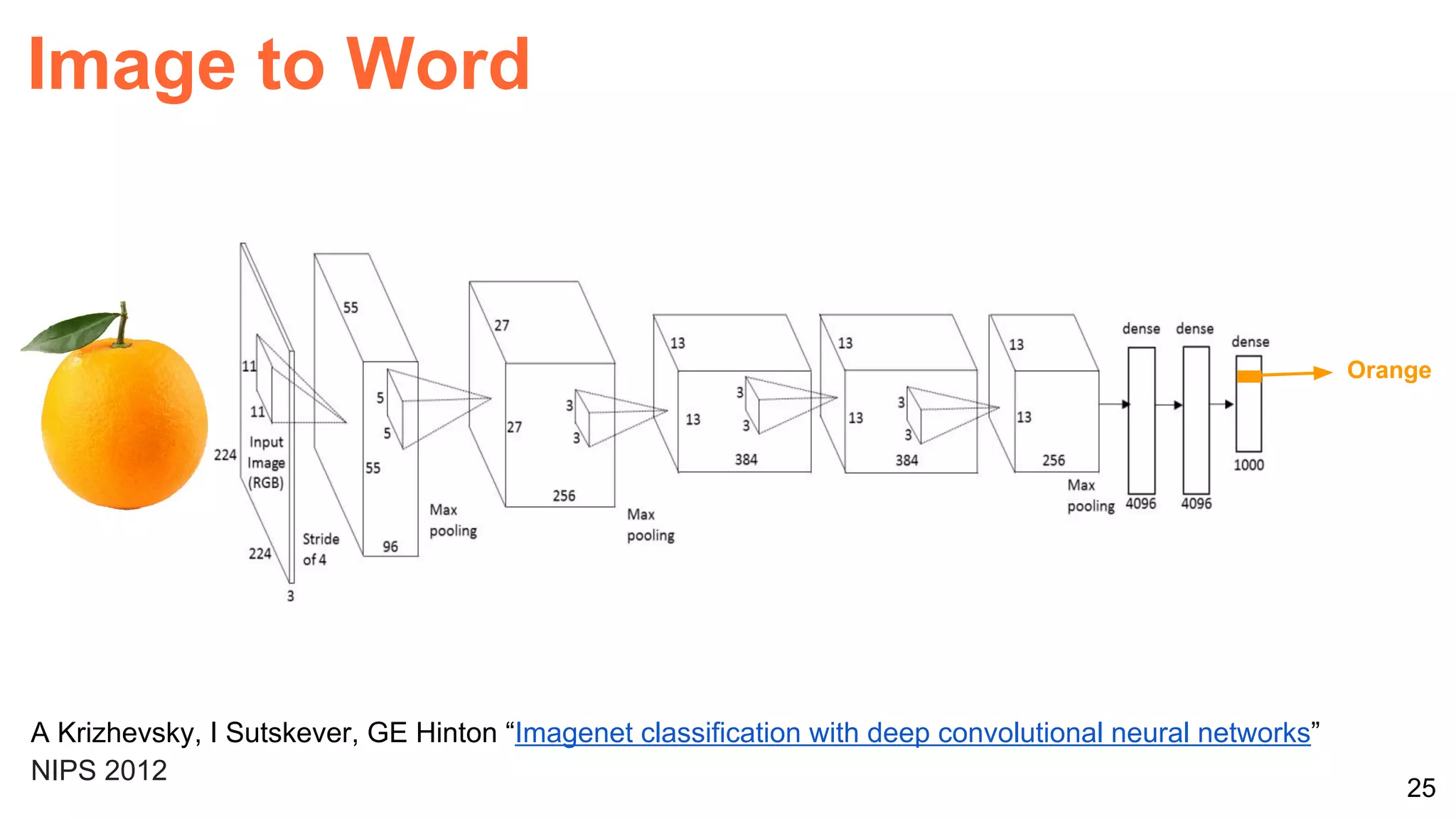
![26Perronin, F., CVPR Tutorial on LSVR @ CVPR’14, Output embedding for LSVR
[1,0,0]
[0,1,0]
[0,0,1]
One-hot
representation
Image to Word](https://image.slidesharecdn.com/reworklondon2017shortoneperceptrontorulethemall-170921071245/75/One-Perceptron-to-Rule-Them-All-Re-Work-Deep-Learning-Summit-London-2017-26-2048.jpg)
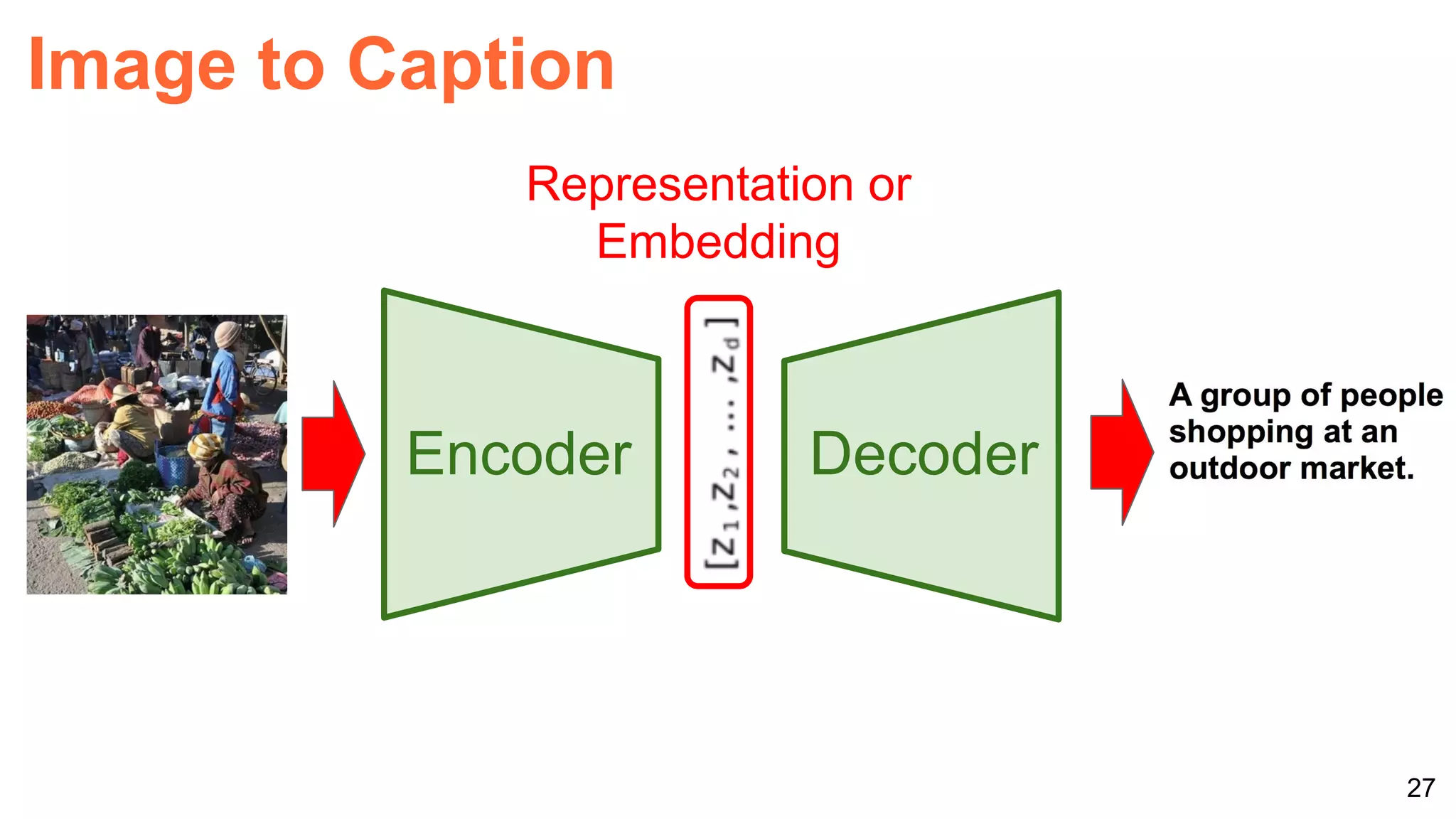



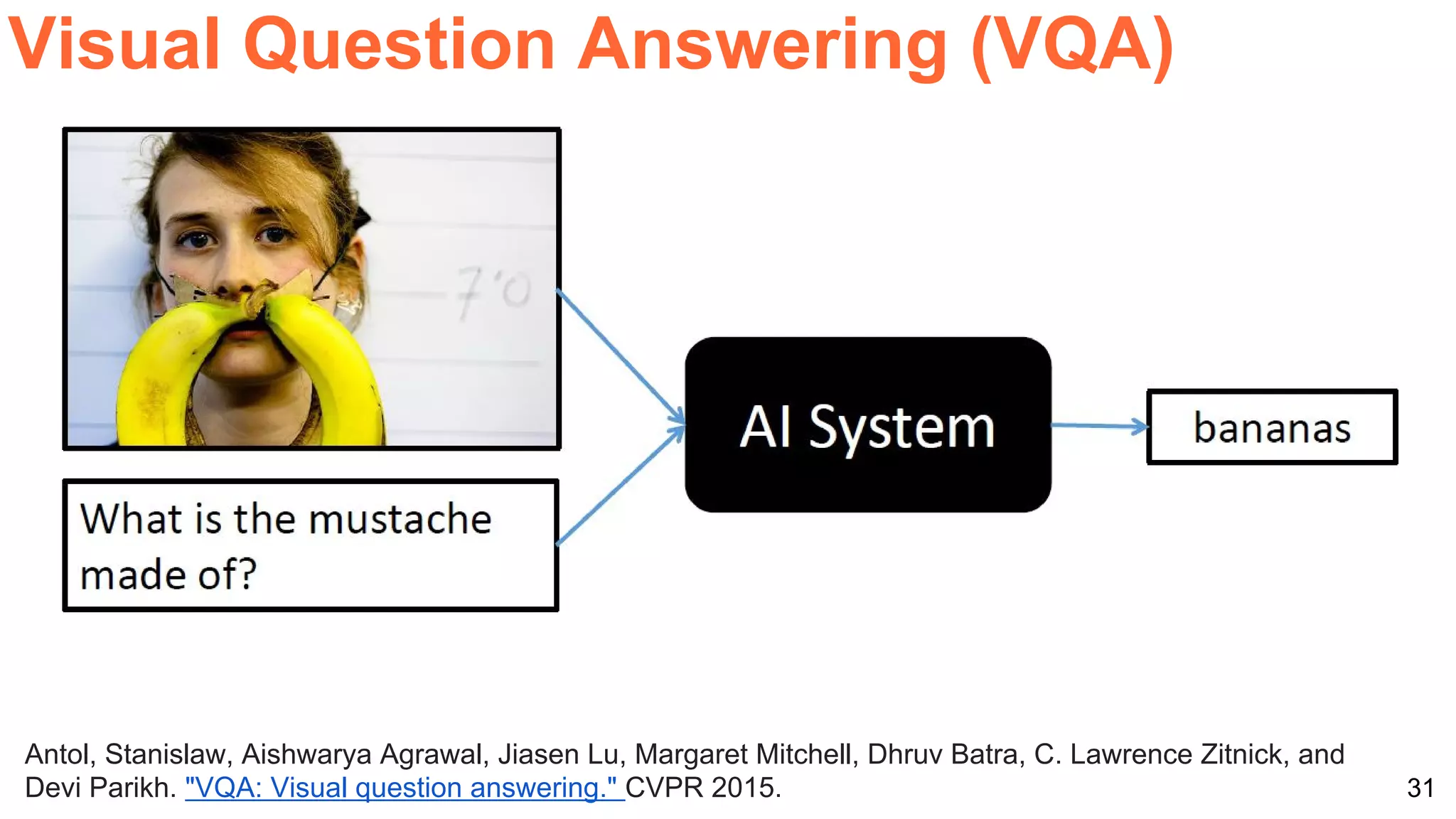
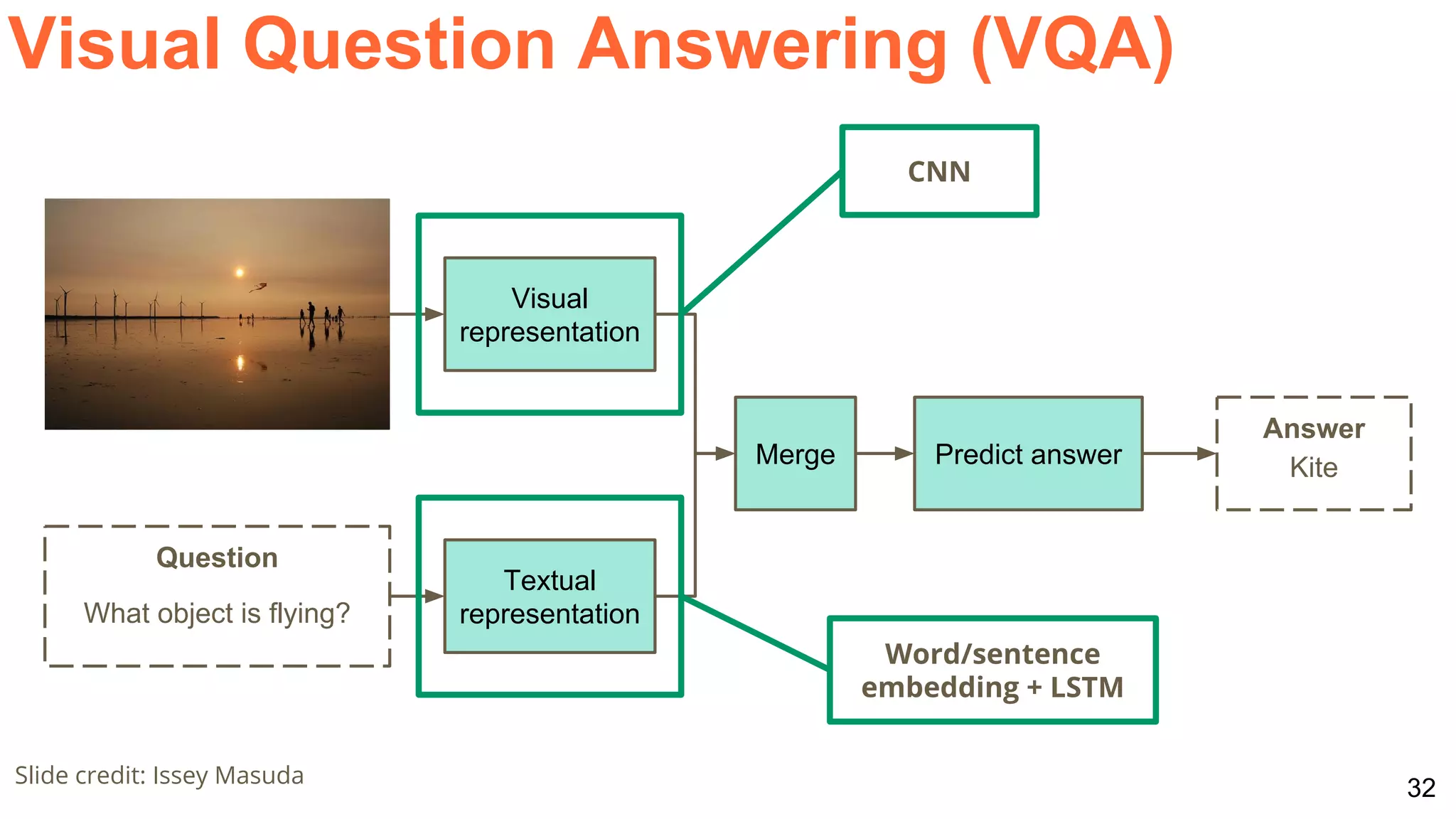
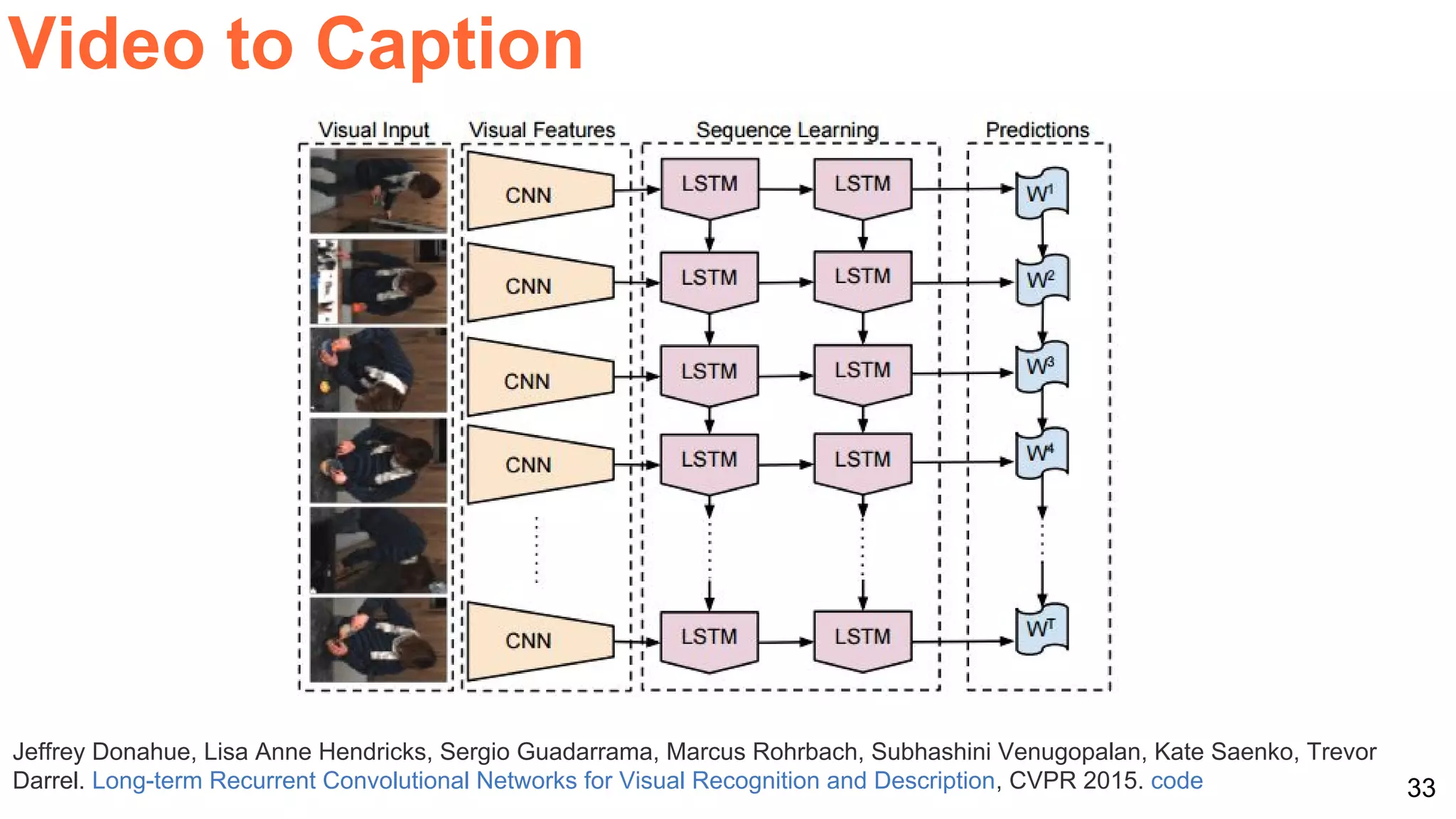
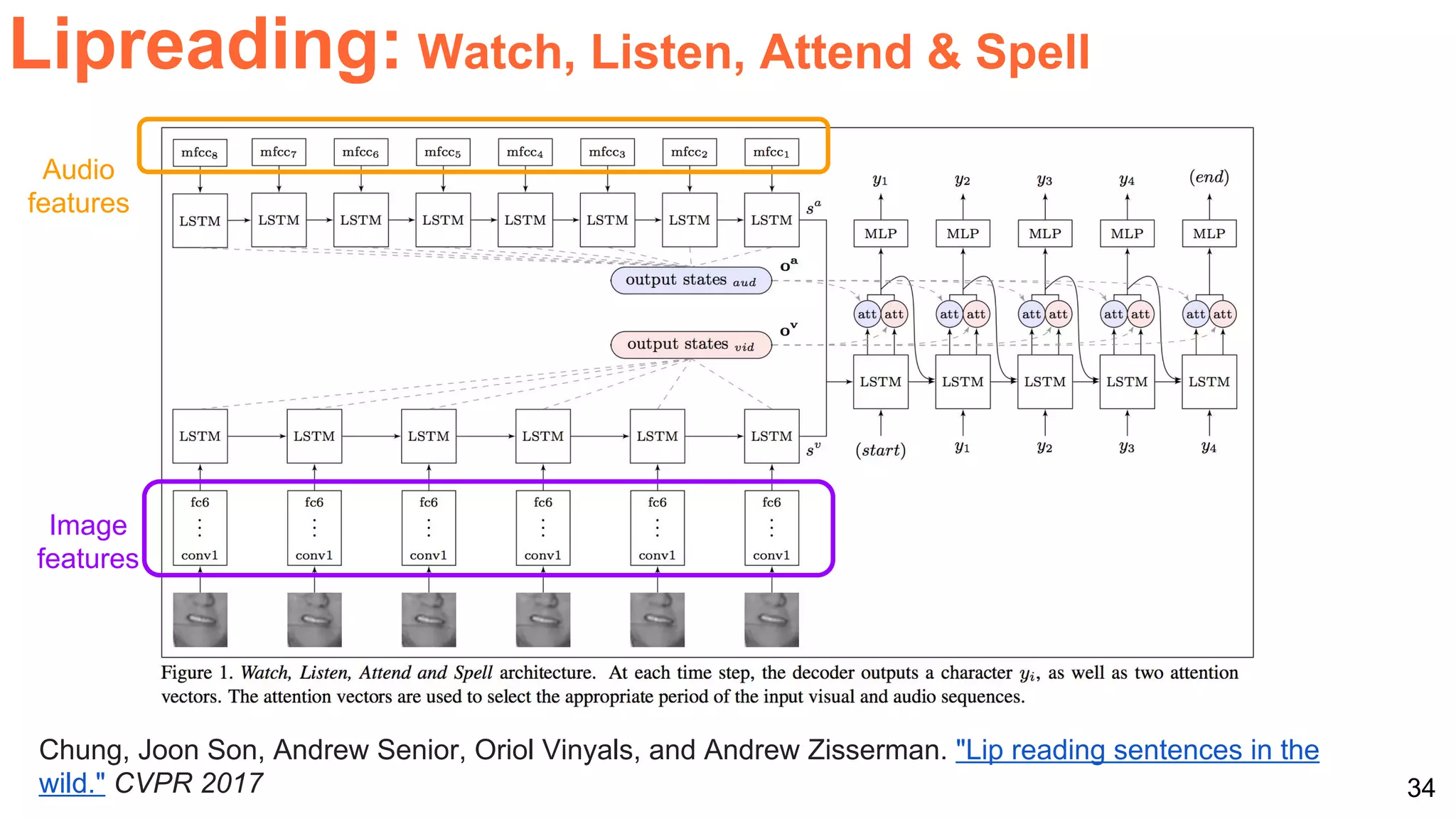


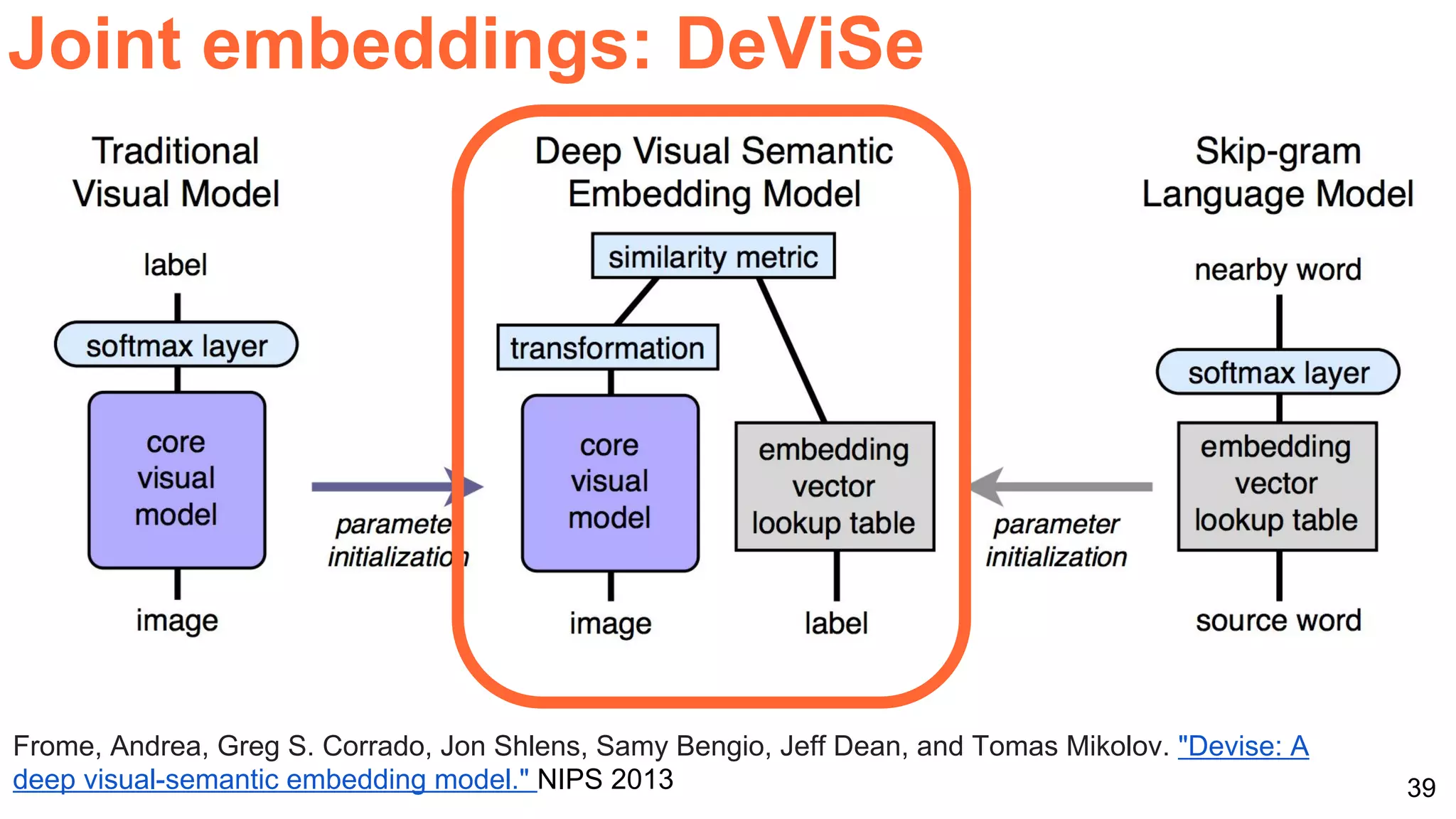
![40
Joint embeddings: DeViSe
Socher, R., Ganjoo, M., Manning, C. D., & Ng, A., Zero-shot learning through cross-modal transfer.
NIPS 2013 [slides] [code]
Zero-shot learning:
a class not present in the
training set of images
can be predicted
(...because it was
present in the training
set of words)](https://image.slidesharecdn.com/reworklondon2017shortoneperceptrontorulethemall-170921071245/75/One-Perceptron-to-Rule-Them-All-Re-Work-Deep-Learning-Summit-London-2017-40-2048.jpg)



















![77
#REWORKDL
@DocXavi[Slides on GDrive
with links]
Xavier Giro-i-Nieto
xavier.giro@upc.edu](https://image.slidesharecdn.com/reworklondon2017shortoneperceptrontorulethemall-170921071245/75/One-Perceptron-to-Rule-Them-All-Re-Work-Deep-Learning-Summit-London-2017-77-2048.jpg)

The document highlights various advancements in deep learning applications related to multimedia, covering topics such as neural machine translation, image-to-image translation, visual question answering, and video captioning. It discusses notable research papers and models in these areas, including techniques for generating audio from visual content and the integration of cross-modal representations. The content also mentions upcoming courses and workshops related to deep learning at UPC.


































































