What is ReinforcementLearning
• RL is an area of machine learning that focuses on how you, or how
some thing (also known as an agent), might act in an environment in
order to maximize some given reward.
• Reinforcement learning algorithms study the behavior of subjects in
such environments and learn to optimize that behavior.
• An agent learns by try and error
3.
How is RLdifferent from Supervised and
unsupervised learning
• Unlike supervised learning where feedback provided to the agent is a
correct set of actions for performing a task, reinforcement learning
uses rewards and punishment as signals for positive and negative
behavior.
• While the goal in unsupervised learning is to find similarities and
differences between data points, in reinforcement learning the goal is
to find a suitable action model that would maximize the total
cumulative reward of the agent.
4.
Markov Decision Process(MDP)
• Reinforcement learning models world problems using the MDP (Markov
Decision Process) formalism.
• A Markov decision process (MDP) is a discrete time stochastic control
process. It provides a mathematical framework for modeling sequential
decision making in situations where outcomes are partly random and
partly under the control of a decision maker.
5.
Components of MDP
Inan MDP, we have a decision maker, called an agent, that interacts with the environment it's placed in. These
interactions occur sequentially over time. At each time step, the agent will get some representation of the
environment’s state. Given this representation, the agent selects an action to take. The environment is then
transitioned into a new state, and the agent is given a reward as a consequence of the previous action.
Components of an MDP:
• Agent
• Environment
• State
• Action
• Reward
6.
Throughout this process,the agent’s goal is to maximize the total
amount of rewards that it receives from taking actions in given states.
This means that the agent wants to maximize not just the immediate
reward, but the cumulative rewards it receives over time.
Expected Return (sumof rewards)
• The goal of an agent in an MDP is to maximize its cumulative rewards.
This is what makes it choose the decision it takes.
10.
Discounted return
Rather thanthe agent’s goal being to maximize the expected return of rewards, it
will instead be to maximize the expected discounted return of rewards.
The fact that the discount rate ,γ is between 0 and 1 is a mathematical trick to
make an infinite sum finite. This helps in proving the convergence of certain
algorithms.
11.
How good isa state or action? Policies and
value functions
• This will give us a way to measure “how good” it is for an agent to be
in a given state or to select a given action(the notion of policies).
• Secondly, how good is a given action or state for the agent. Selecting
one action over another in a given state may increase or decrease the
agent's rewards. This helps our agent out with deciding which actions
to take in which states(the notion of value functions).
12.
Policy
• A policy(denoted as π) is a function that maps a given state to
probabilities of selecting each possible action from that state.
• Plainly, it tells us which is the best action to take in each state
• If an agent follows policy π at time t, then π(a|s) is the probability
that At=a if St=s. This means that, at time t, under policy π, the
probability of taking action a in state s is;
π(a|s).
14.
Value functions
• Valuefunctions are functions of states, or of state-action pairs, that estimate how
good it is for an agent to be in a given state, or how good it is for the agent to
perform a given action in a given state.
• This notion of how good a state or state-action pair is given in terms of expected
return.
• Since the way an agent acts is influenced by the policy it's following, then we can
see that value functions are defined with respect to policies.
• Value functions are functions of states or state-action pairs. These formulate the
2 types of value functions, namely; state-value functions and action-value
functions respectively
16.
Action-value function
• Similarly,the action-value function for policy π, denoted as qπ, tells us
how good it is for the agent to take any given action from a given
state while following policy π.
• In other words, it gives us the value of an action under π.
17.
Conventionally, the action-valuefunction qπ is referred to as the Q-function,
and the output from the function for any given state-action pair is called a Q-value.
The letter “ Q” is used to represent the quality of taking a given action in a given state.
18.
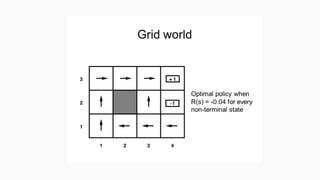
Optimal Policy
• Thegoal of a reinforcement learning algorithm is to find an optimal policy that will yield more return to the agent
than all other policies.
• In terms of return, a policy π is considered to be better than or the same as policy π if the expected return of π is
′
greater than or equal to the expected return of π for all states.
′
• vπ(s) gives the expected return for starting in state s and following π thereafter. A policy that is better than or at
least the same as all other policies is called the optimal policy.
Optimal action-value function
•Similarly, the optimal policy has an optimal action-value function, or
optimal Q-function, which we denote as q∗
21.
Bellman optimality equation
•One fundamental property of q is that it must satisfy the following equation.
∗
• This is called the Bellman optimality equation. It states that, for any state-action pair (s,a) at time t, the
expected return from starting in state s, selecting action a and following the optimal policy thereafter (AKA
the Q-value of this pair) is going to be the expected reward we get from taking action a in state s, which is
Rt+1, plus the maximum expected discounted return that can be achieved from any possible next state-action
pairs (s ,a ) at time t + 1
′ ′
23.
Q- Learning
• Q– Learning is a model-free reinforcement learning algorithm used for
learning the optimal policy in a Markov Decision Process.
• The objective of Q-learning is to find a policy that is optimal in the sense
that the expected value of the total reward over all successive steps is the
maximum achievable. In other words, the goal of Q-learning is to find the
optimal policy by learning the optimal Q-values for each state-action pair.
24.
How Q –Learning Works
• Value iteration
The Q-learning algorithm iteratively updates the Q-values for each
state-action pair using the Bellman equation until the Q-function
converges to the optimal Q-function, q . This approach is called
∗ value
iteration.
25.
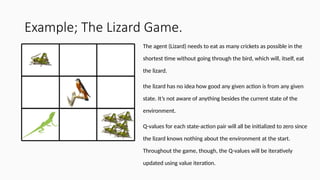
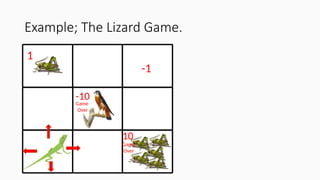
Example; The LizardGame.
The agent (Lizard) needs to eat as many crickets as possible in the
shortest time without going through the bird, which will, itself, eat
the lizard.
the lizard has no idea how good any given action is from any given
state. It’s not aware of anything besides the current state of the
environment.
Q-values for each state-action pair will all be initialized to zero since
the lizard knows nothing about the environment at the start.
Throughout the game, though, the Q-values will be iteratively
updated using value iteration.
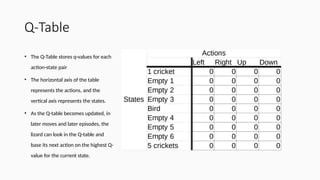
Q-Table
• The Q-Tablestores q-values for each
action-state pair
• The horizontal axis of the table
represents the actions, and the
vertical axis represents the states.
• As the Q-table becomes updated, in
later moves and later episodes, the
lizard can look in the Q-table and
base its next action on the highest Q-
value for the current state.
28.
How does thelizard move?
• Episodes
• Now, we’ll set some standard number of episodes that we want the lizard to play. Let’s
say we want the lizard to play five episodes. It is during these episodes that the learning
process will take place.
• In each episode, the lizard starts out by choosing an action from the starting state
based on the current Q-values in the table. The lizard chooses the action based on
which action has the highest Q-value in the Q-table for the current state.
29.
• But… theq-table is initialized with zero q-values for each state, how
does it choose which action to take first?
?
30.
Exploration and Exploitation
•The agent uses the concept of Exploration and Exploitation to choose
the starting action.
• Exploration is the act of exploring the environment to find out
information about it. Exploitation is the act of exploiting the
information that is already known about the environment in order to
maximize the return.
• These concepts guide how the agent chooses actions not just at the
starting point but also in general.
31.
But Wait….
….when andwhy does the agent
choose between exploration and
exploitation?
32.
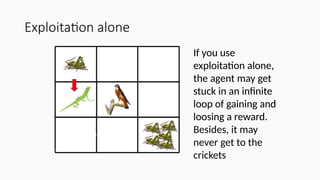
Exploitation alone
If youuse
exploitation alone,
the agent may get
stuck in an infinite
loop of gaining and
loosing a reward.
Besides, it may
never get to the
crickets
33.
Exploitation alone
If youuse
exploitation alone,
the agent may get
stuck in an infinite
loop of gaining and
loosing a reward.
If you use
exploitation alone,
the agent may get
stuck in an infinite
loop of gaining and
loosing a reward.
Besides, it may
never get to the
crickets
34.
Exploration alone
• Ifthe agent uses exploration alone, then it would miss out on
making use of known information that could help to maximize the
return.
So how do we find a balance between
exploration and exploitation?
35.
Epsilon greedy strategy
•Essentially, in each episode, the lizard starts out by choosing an action
from the starting state based on the current Q-value estimates in the
Q-table.
• But since all of the Q-values are first initialized to zero, there’s no way
for the lizard to differentiate between them at the starting state of the
first episode.
• Better yet, for subsequent states, is it really as straight-forward as just
selecting the action with the highest Q-value for the given state?
• To get the balance between exploitation and exploration, we use what
is called an epsilon greedy strategy.
36.
How epsilon greedystrategy works
• We define an exploration rate ϵ that we initially set to 1. This exploration rate is the probability that
our agent will explore the environment rather than exploit it. With ϵ=1, it is 100%certain that the
agent will start out by exploring the environment. As it explores, it updates the q-table with Q-Values.
• As the agent learns more about the environment, at the start of each new episode, ϵ will decay by
some rate that we set so that the likelihood of exploration becomes less and less probable as the
agent learns more and more about the environment. The agent will become “greedy” in terms of
exploiting the environment once it has had the opportunity to explore and learn more about it. It will
choose the action with the highest Q-value for its current state from the Q-table.
37.
To update theQ-value for the action of moving right taken from the
previous state, we use the Bellman equation that we highlighted
previously;
38.
The learning rate
•The learning rate is a number between 0 and 1, which can be thought of as how quickly the agent abandons the previous Q-value in the Q-
table for a given state-action pair for the new Q-value.
• So, for example, suppose we have a Q-value in the Q-table for some arbitrary state-action pair that the agent has experienced in a previous
time step. Well, if the agent experiences that same state-action pair at a later time step once it's learned more about the environment, the
Q-value will need to be updated to reflect the change in expectations the agent now has for the future returns.
• We don't just overwrite the old Q-value, but rather, we use the learning rate as a tool to determine how much information we keep about
the previously computed Q-value for the given state-action pair versus the new Q-value calculated for the same state-action pair at a later
time step. We’ll denote the learning rate with the symbol α, and we’ll arbitrarily set α=0.7for our lizard game example.
• The higher the learning rate, the more quickly the agent will adopt the new Q-value. For example, if the learning rate is 1, the estimate for
the Q-value for a given state-action pair would be the straight up newly calculated Q-value and would not consider previous Q-values that
had been calculated for the given state-action pair at previous time steps.
39.
Calculating the newQ-value
So, our new Q-value is equal to the sum of our old value and the learned value.
40.
Max steps
• Wecan also specify a max number of steps that our agent can take
before the episode auto-terminates. With the way the game is set up
right now, termination will only occur if the lizard reaches the state
with five crickets or the state with the bird.
• We could define some condition that states if the lizard hasn’t
reached termination by either one of these two states after 100 steps,
then terminate the game after the 100th step.
#4 Discrete time means time is measurable. It’s the opposite of continuous ()
Stochastic means randomly determined process. So the system is having a random probability distribution or pattern.
So processes occur at particular time intervals.
#7 U take action Ao in state So the transition to state S1 and receive a reward R1, ….
#12 If an agent follows policy pie at time t, then pie of a given s is … that the action at time t = a, and state at state t = s
#15 E means expected value. The value of state s, under policy pie, is the expected return starting from state s, at time t, and following policy pie thereafter.
#16 The value of action a, in state s, under policy pie is the expected return of starting in state s, then taking action a, and following policy pie thereafter.
#19 The value of each state, yielded by the optimal state-value function is the maximum value for that state under all policies.
#20 The optimal Q value for each action-state pair, yielded by the optimal q function, gives the maximum possible q value for that state-action pair for all policies.
#31 The goal of an agent is to maximize the expected return, so you might think that we want our agent to use exploitation all the time and not worry about doing any exploration. This strategy, however, isn’t quite right.
Think of our game. If our lizard got to the single cricket before it got to the group of five crickets, then only making use of exploitation, going forward the lizard would just learn to exploit the information it knows about the location of the single cricket to get single incremental points infinitely. It would then also be losing single points infinitely just to back out of the tile before it can come back in to get the cricket again.
If the lizard was able to explore the environment, however, it would have the opportunity to find the group of five crickets that would immediately win the game. If the lizard only explored the environment with no exploitation, however, then it would miss out on making use of known information that could help to maximize the return.



















































































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)









![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)
