R version 3.0.1(2013-05-16) -- "Good Sport"
Copyright (C) 2013 The R Foundation for Statistical Computing
Platform: i386-w64-mingw32/i386 (32-bit)
R は、自由なソフトウェアであり、「完全に無保証」です。
一定の条件に従えば、自由にこれを再配布することができます。
配布条件の詳細に関しては、'license()' あるいは 'licence()' と入力してください。
R は多くの貢献者による共同プロジェクトです。
詳しくは 'contributors()' と入力してください。
また、R や R のパッケージを出版物で引用する際の形式については
'citation()' と入力してください。
'demo()' と入力すればデモをみることができます。
'help()' とすればオンラインヘルプが出ます。
'help.start()' で HTML ブラウザによるヘルプがみられます。
'q()' と入力すれば R を終了します。
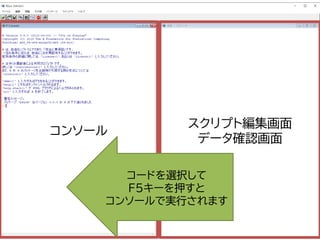
>|
← ここから入力
入力している部分は赤く表示されます










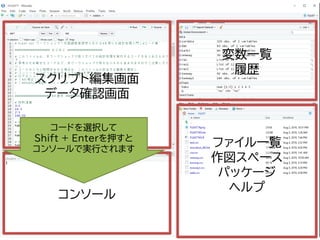








![変数に データを 代入する
• 変数の名前を書き、- と > で矢印を作る
• 右辺には、変数に入れたいデータを記入する
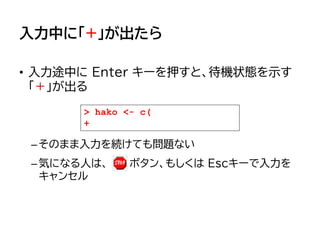
> # hakoという名の変数に 5 という数字を代入する
> hako <- 5
> # hakoという名の変数の中身を確認
> hako
[1] 5](https://image.slidesharecdn.com/fleat7ws-190806014109/85/R-20-320.jpg)
![変数の名前
• どのような名前でもOK
–2バイト文字も使用できるが、変換が面倒なので使わな
い
• 後で見返したときに、どんなデータが入っているか
わかるような名前をつける
• 既存の変数にデータを代入すると、
新しいデータで上書きされる
> hako <- 5
> hako <- 10
> hako
[1] 10](https://image.slidesharecdn.com/fleat7ws-190806014109/85/R-21-320.jpg)




![平方根を一気に
> hako <- c(1, 2, 3, 4, 5)
> sqrt(hako)
[1] 1.000000 1.414214 1.732051 2.000000
[5] 2.236068](https://image.slidesharecdn.com/fleat7ws-190806014109/85/R-27-320.jpg)






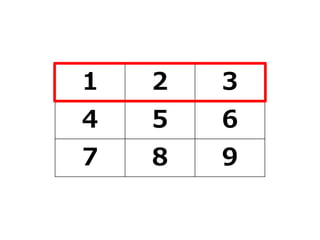

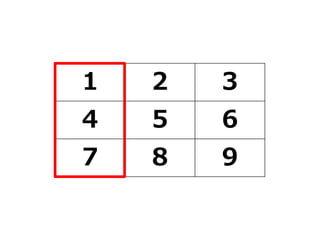
![行列の要素を取り出す
• 行列の中から、ベクトルとして取り出したい行や列を
指定
–行を取り出す:変数名[行番号,]
–列を取り出す:変数名[,列番号]
> #2列目を取り出す場合
> 変数名[,2]
[1] 2 5 8
> #2行目を取り出す場合
> 変数名[2,]
[1] 4 5 6](https://image.slidesharecdn.com/fleat7ws-190806014109/85/R-37-320.jpg)
![イメージ
[,1] [,2] [,3] [,4] [,5]
[1,]
[2,]
[3,]
[4,]
[5,]](https://image.slidesharecdn.com/fleat7ws-190806014109/85/R-38-320.jpg)
![ベクトルと行列 まとめ
• ベクトル
–数字や文字の列
• 行列
–ベクトルを縦横に並べたもの
–横方向が行、縦方向が列
–行列から必要な要素を取り出すには、変数名[行番号,列
番号]](https://image.slidesharecdn.com/fleat7ws-190806014109/85/R-39-320.jpg)

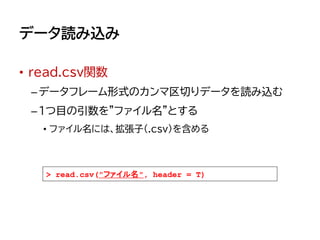
![データ読み込み
• 下準備
–getwd関数で、現在の作業ディレクトリの場所を確認
• 作業ディレクトリ:データを読み込みたいファイルを置く場所
–その作業ディレクトリに、配布したcsvファイルを移動し
てください
> getwd()
[1] "C:/Users/yusaku/Documents"](https://image.slidesharecdn.com/fleat7ws-190806014109/85/R-41-320.jpg)












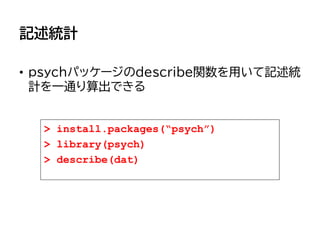
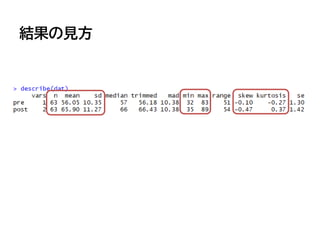
![ヒストグラムの作成
• hist関数でヒストグラム(度数分布図)を描き、事前テス
ト/事後テストの分布を観察する
–さきほどの練習で作った変数 test のデータを使う
> hist(dat[,1]) #事前テストのヒストグラム
> hist(dat[,2]) #事後テストのヒストグラム](https://image.slidesharecdn.com/fleat7ws-190806014109/85/R-59-320.jpg)
![2つのヒストグラム
事前テストの分布 事後テストの分布
Histogram of dat[, 1]
dat[, 1]
Frequency
30 40 50 60 70 80 90
0510152025
Histogram of dat[, 2]
dat[, 2]
Frequency
30 40 50 60 70 80 90
05101520](https://image.slidesharecdn.com/fleat7ws-190806014109/85/R-60-320.jpg)