Download as PDF, PPTX


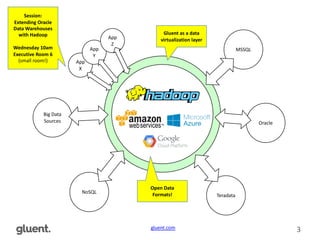


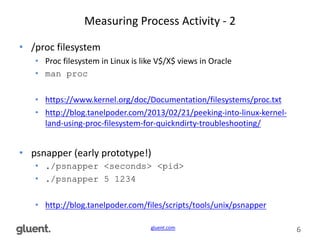






The document presents a discussion on modern Linux performance tools, particularly focusing on advanced measuring techniques for processes, IO, memory, and CPU. It emphasizes practical applications that can be utilized in production environments, referencing various tools like strace, sysdig, iostat, and perf. The author, Tanel Poder, shares personal expertise while promoting resources and a session on extending Oracle data warehouses with Hadoop.



















































![The power of linux advanced tracer [POUG18]](https://cdn.slidesharecdn.com/ss_thumbnails/thepoweroflinuxadvancedtracer-180909125236-thumbnail.jpg?width=640&height=640&fit=bounds)



































