Download as PDF, PPTX



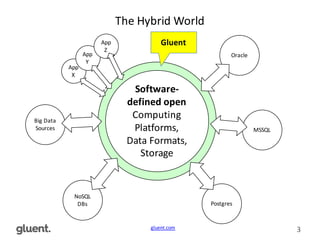

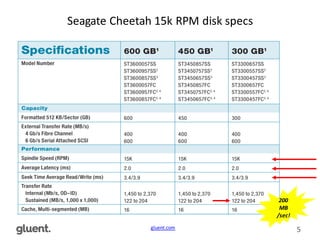


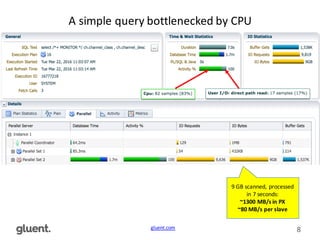
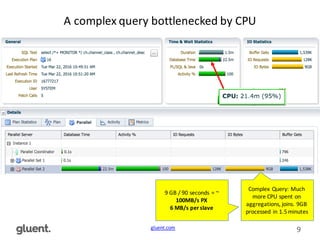







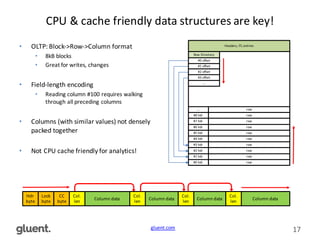
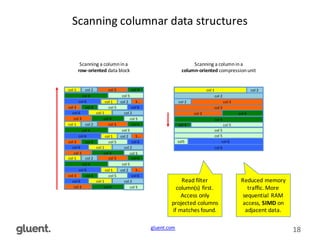




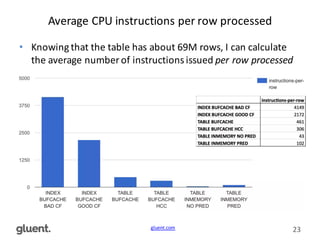
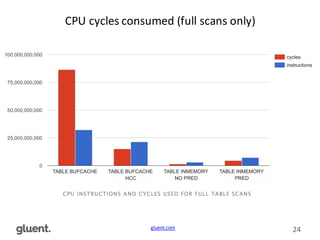
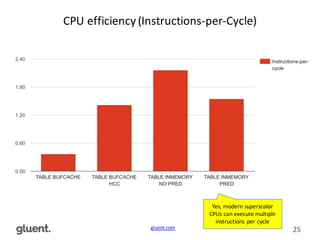

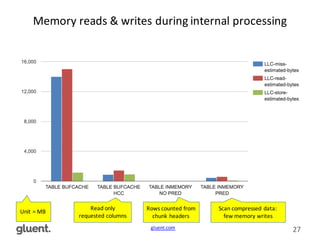







This document discusses in-memory execution for databases. It begins with introductions and background on the author. It then discusses how databases can offload data to memory to improve query performance 2-24x by analyzing storage use and access patterns. It covers concepts like how RAM access is now the performance bottleneck and how CPU cache-friendly data structures are needed. It shows examples measuring performance differences when scanning data in memory versus disk. Finally, it discusses future directions like more integrated storage and memory and new data formats optimized for CPU caches.























































































