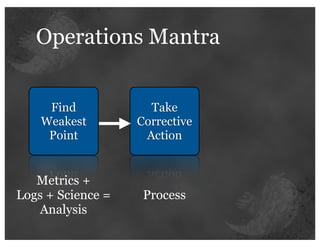
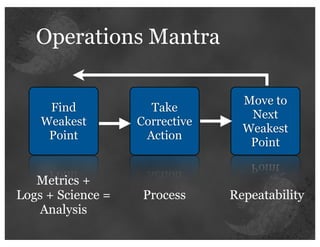
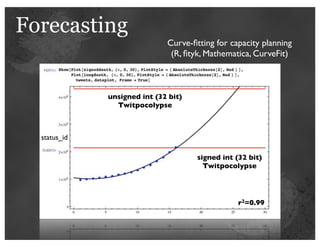
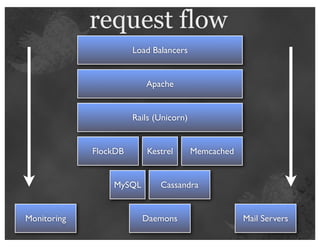
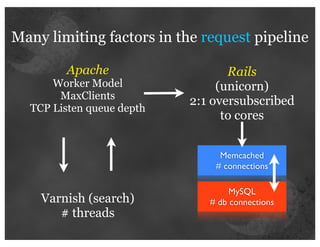
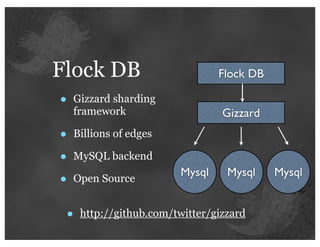
The document details insights from John Adams, an early Twitter employee, on scaling Twitter's infrastructure and operations. Topics include capacity planning, performance optimization, monitoring, and the significance of decomposing applications into services for better manageability. Key points emphasize the use of metrics for decision-making and the importance of automation and collaboration in system management.