Downloaded 129 times























![April 2-6, 2017 in Las Vegas, NV USA #C17LV
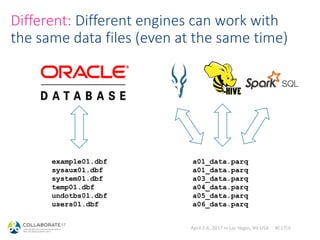
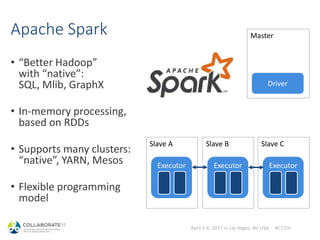
Same: Queries are optimized
sql> explain select count(1) from sh.times;
+----------------------------------------------------------+
| Explain String |
+----------------------------------------------------------+
| Estimated Per-Host Requirements: Memory=10.00MB VCores=1 |
| |
| 03:AGGREGATE [FINALIZE] |
| | output: count:merge(1) |
| | |
| 02:EXCHANGE [UNPARTITIONED] |
| | |
| 01:AGGREGATE |
| | output: count(1) |
| | |
| 00:SCAN HDFS [sh.times] |
| partitions=16/16 files=32 size=500.45KB |
+----------------------------------------------------------+](https://image.slidesharecdn.com/hadoopdatabasesfororacledba-170404165932/85/Hadoop-databases-for-oracle-DBAs-27-320.jpg)




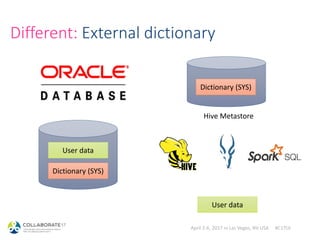
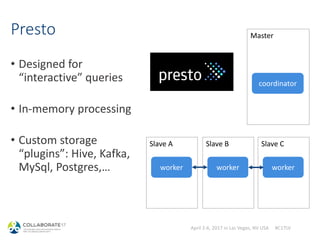
![April 2-6, 2017 in Las Vegas, NV USA #C17LV
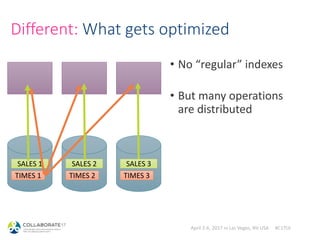
Same: “sqlplus-like” clients
> impala-shell -i 10.0.0.1
[10.0.0.1:21000] > select prod_id, count(1)
from sh.sales group by prod_id order by 2 desc limit 1;
+-----------------------+----------+
| prod_id | count(1) |
+-----------------------+----------+
| 48.000000000000000000 | 74026 |
+-----------------------+----------+
> beeline –u 'jdbc:hive2://10.0.0.1:10000'
0: jdbc:hive2://10.0.0.1:1> select prod_id, count(1)
from sh.sales group by prod_id order by 2 desc limit 1;](https://image.slidesharecdn.com/hadoopdatabasesfororacledba-170404165932/85/Hadoop-databases-for-oracle-DBAs-34-320.jpg)


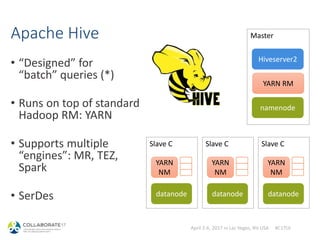
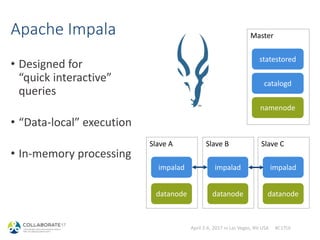












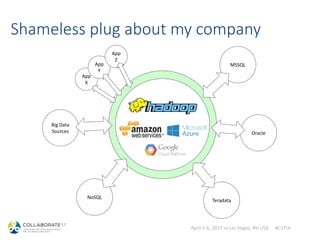
The document outlines a session on Hadoop databases led by Maxym Kharchenko, covering topics such as the nature of Hadoop, comparisons between Hadoop databases like Hive and Impala and traditional relational databases, and guidance on getting started with the Hadoop ecosystem. It discusses the advantages and challenges of using commodity systems for big data, emphasizing the evolution of databases and the need for efficient query processing. The presentation includes insights on architecture, various data management approaches, and resources for attendees to explore Hadoop further.


























































![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Nikola Vasiljevic - Player segmentation by combat playstyles ...](https://cdn.slidesharecdn.com/ss_thumbnails/mnvbf0yvrwaqsipzrrv3-2-nikola-vasiljevic-player-segmentation-by-playstyles-in-action-shooter-games-260114111931-b4d766cd-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Ivica Milaric - The Future of Gaming and AI Tools.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/tijgzsmgse2kj2y5pzzp-5-ivica-milaric-the-future-of-gaming-x-ai-tools-260114111931-87c2b3ac-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragan Jerosimovic - The Anatomy of a Narrative Simulation.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/vzputuprdqr6zwbrwdcw-1-dragan-jerosimovic-the-anatomy-of-a-narrative-simulation-260114111931-9d04fba2-thumbnail.jpg?width=640&height=640&fit=bounds)



