Download to read offline


















![NumPy: A Powerful Data Container for Python
innfinision.net
Large Data Analyze with PyTables
NumPy provides a very powerful, object oriented, multi dimensional data container:
●
array[index]: retrieves a portion of a data container
●
(array1**3 / array2) - sin(array3): evaluates potentially complex
expressions
● numpy.dot(array1, array2): access to optimized BLAS (*GEMM) functions](https://image.slidesharecdn.com/pytables-150201024554-conversion-gate02/75/PyTables-22-2048.jpg)

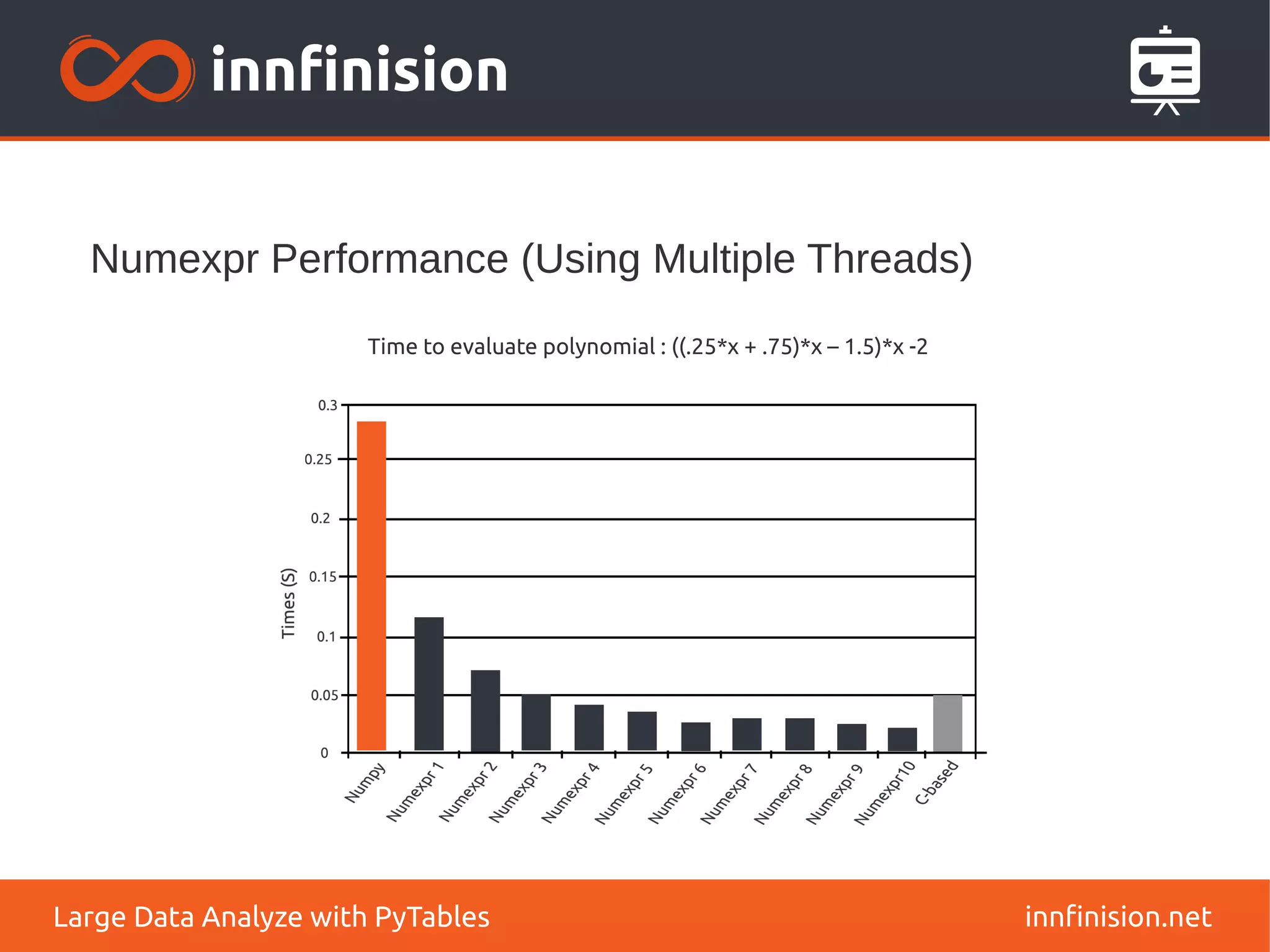



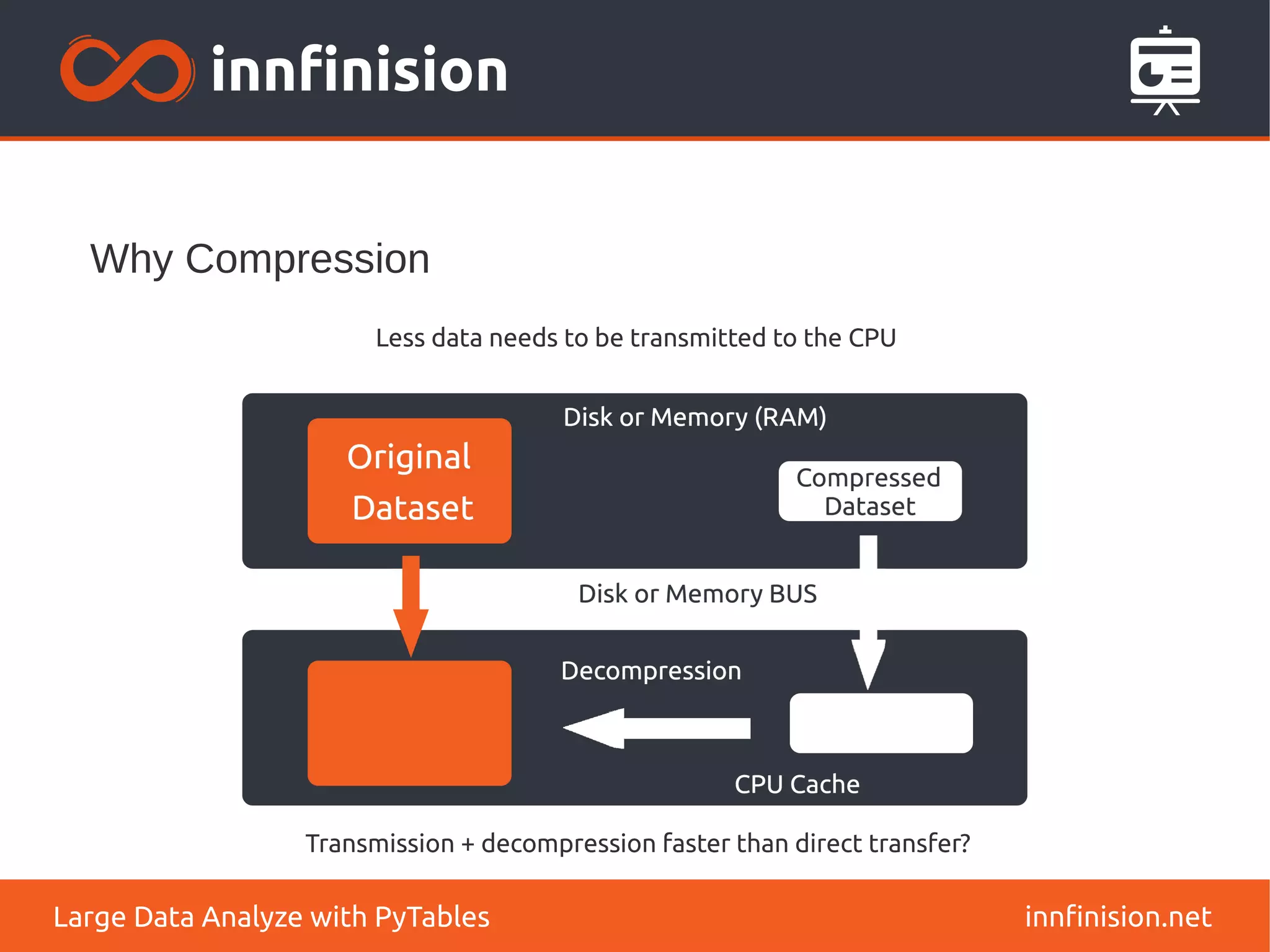
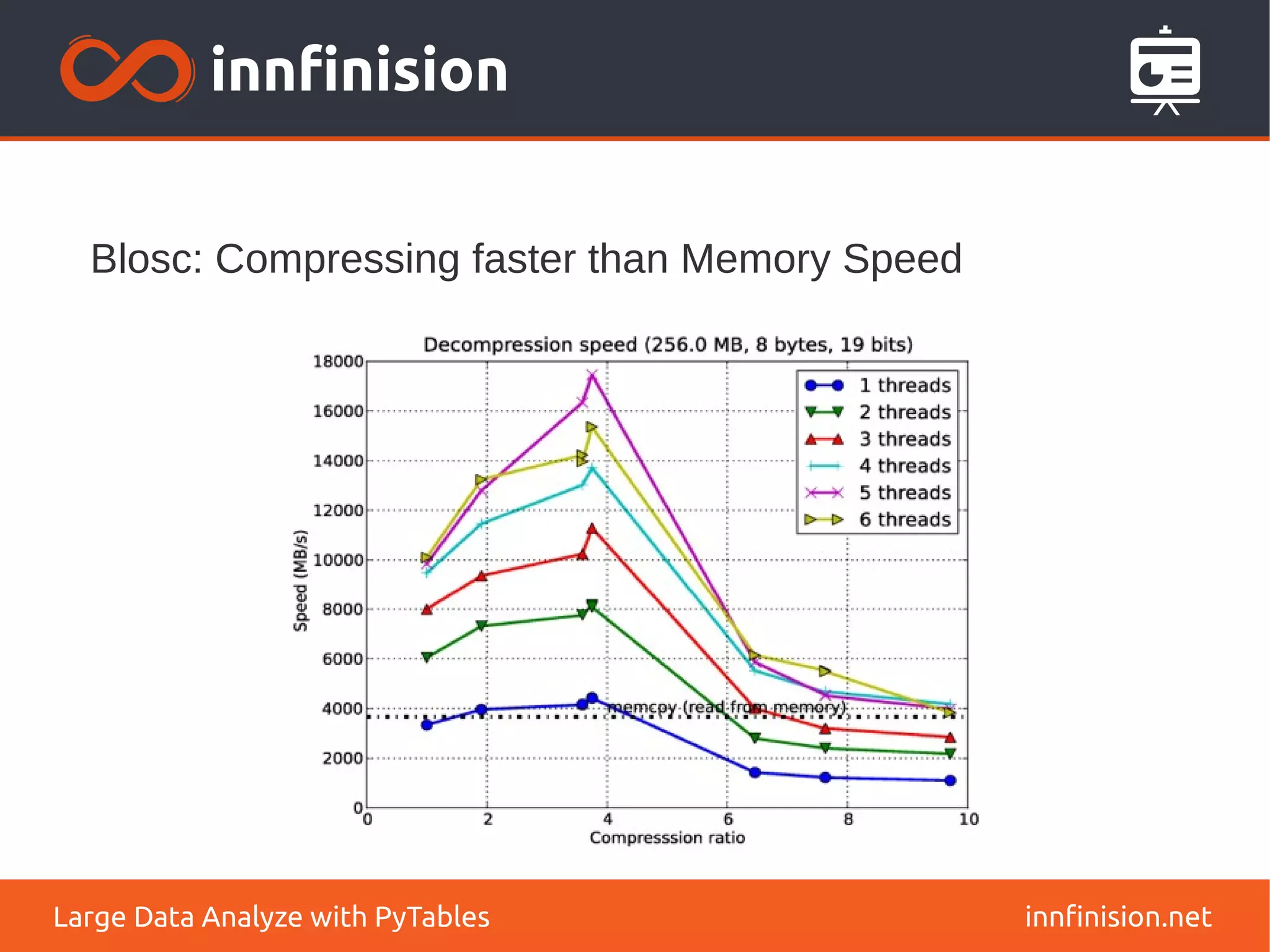





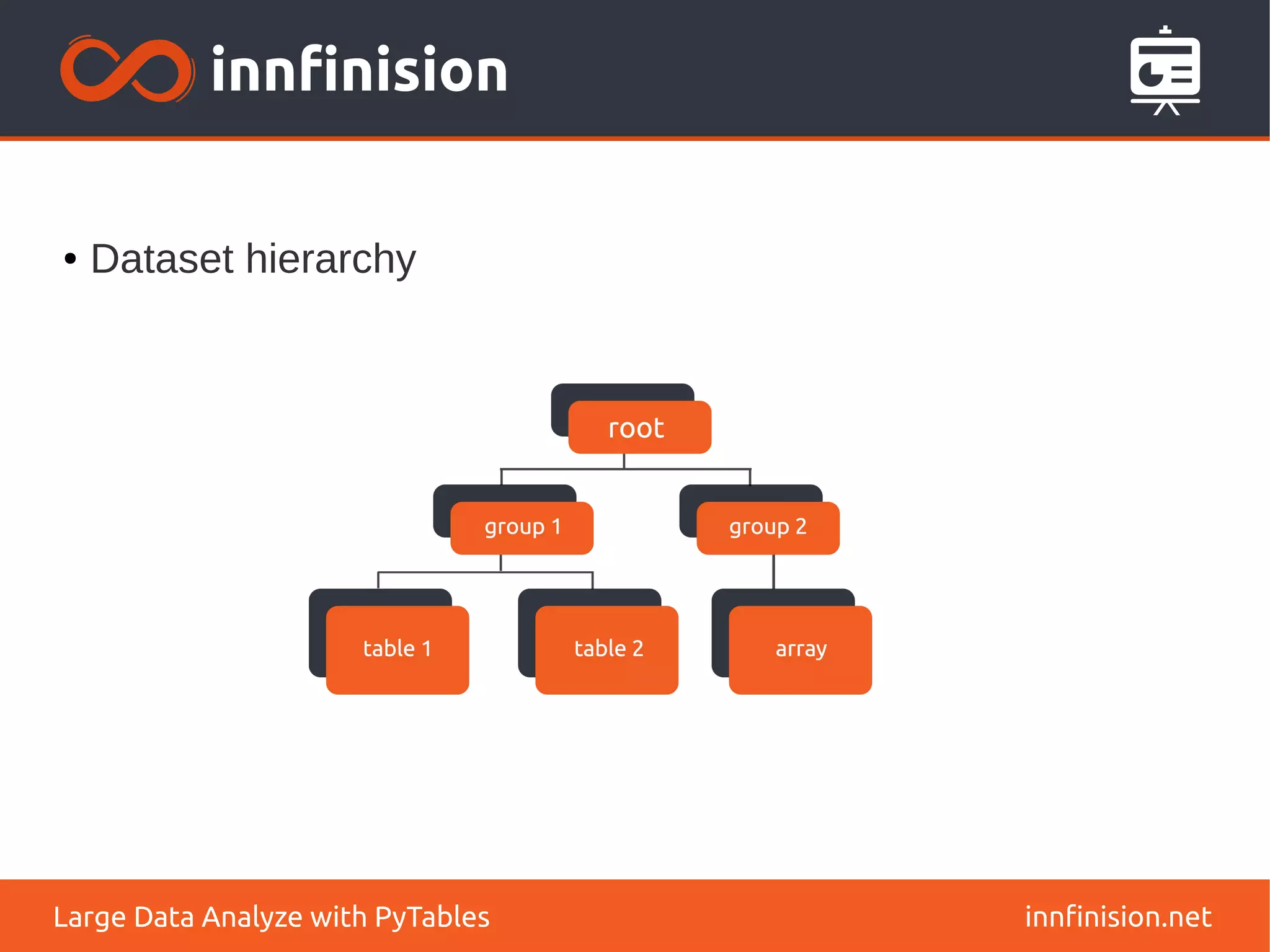


![Different query modes
innfinision.net
Large Data Analyze with PyTables
Regular query:
●
[ r[‘c1’] for r in table
if r[‘c2’] > 2.1 and r[‘c3’] == True)) ]
In-kernel query:
●
[ r[‘c1’] for r in table.where(‘(c2>2.1)&(c3==True)’) ]
Indexed query:
●
table.cols.c2.createIndex()
●
table.cols.c3.createIndex()
●
[ r[‘c1’] for r in table.where(‘(c2>2.1)&(c3==True)’) ]](https://image.slidesharecdn.com/pytables-150201024554-conversion-gate02/75/PyTables-39-2048.jpg)



This document discusses the use of PyTables for large data analysis, detailing its capabilities for managing hierarchical datasets and efficient data manipulation. It highlights the challenges posed by CPU, memory, and disk speed mismatches, introduces high-performance libraries, and explains the advantages of using NumPy and data compression techniques. Additionally, it describes the HDF5 format and emphasizes PyTables' fast querying capabilities, enabling effective data retrieval and analysis.































































![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milan Zdravkovic - The road less traveled in District Heating...](https://cdn.slidesharecdn.com/ss_thumbnails/nfaboniqwsz4ucyctnmy-2-milan-zdravkovic-dsc2025-the-road-less-traveled-in-district-heating-operation-251208151905-f56388a5-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Sara Polak - The Ancient Operating System: What Archaeology T...](https://cdn.slidesharecdn.com/ss_thumbnails/3vch2p6tttdnwhsgazoz-3-sara-polak-smart-cities-251208152532-64404202-thumbnail.jpg?width=640&height=640&fit=bounds)
