Downloaded 14 times






















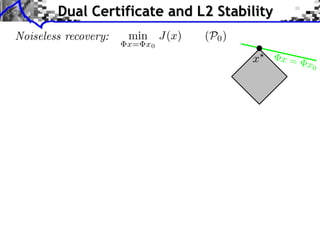
![Noiseless recovery: min
x= x0
J(x) (P0)
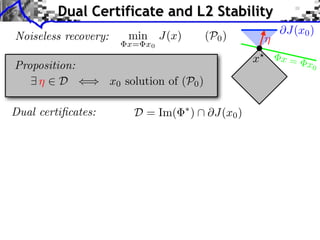
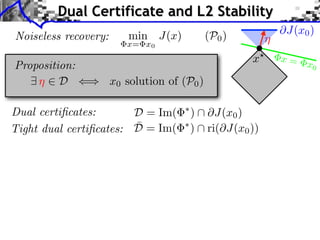
Dual certificates:
Tight dual certificates:
x = x0
⌘
Proposition:
D = Im( ⇤
) @J(x0)
¯D = Im( ⇤
) ri(@J(x0))
9 ⌘ 2 D () x0 solution of (P0)
Dual Certificate and L2 Stability
@J(x0)
x?
Theorem:
[Fadili et al. 2013] for ⇠ ||w|| one has ||x?
x0|| = O(||w||)
If 9 ⌘ 2 ¯D and ker( ) Tx0 = {0}](https://image.slidesharecdn.com/2013-07-02-sampta-gauges-130709141101-phpapp01/85/Model-Selection-with-Piecewise-Regular-Gauges-33-320.jpg)
![Noiseless recovery: min
x= x0
J(x) (P0)
Dual certificates:
Tight dual certificates:
x = x0
⌘
Proposition:
! The constants depend on N . . .
D = Im( ⇤
) @J(x0)
¯D = Im( ⇤
) ri(@J(x0))
9 ⌘ 2 D () x0 solution of (P0)
Dual Certificate and L2 Stability
@J(x0)
x?
Theorem:
[Fadili et al. 2013] for ⇠ ||w|| one has ||x?
x0|| = O(||w||)
If 9 ⌘ 2 ¯D and ker( ) Tx0 = {0}](https://image.slidesharecdn.com/2013-07-02-sampta-gauges-130709141101-phpapp01/85/Model-Selection-with-Piecewise-Regular-Gauges-34-320.jpg)
![Noiseless recovery: min
x= x0
J(x) (P0)
Dual certificates:
Tight dual certificates:
x = x0
⌘
Proposition:
[Grassmair 2012]: J(x?
x0) = O(||w||).
[Grassmair, Haltmeier, Scherzer 2010]: J = || · ||1.
! The constants depend on N . . .
D = Im( ⇤
) @J(x0)
¯D = Im( ⇤
) ri(@J(x0))
9 ⌘ 2 D () x0 solution of (P0)
Dual Certificate and L2 Stability
@J(x0)
x?
Theorem:
[Fadili et al. 2013] for ⇠ ||w|| one has ||x?
x0|| = O(||w||)
If 9 ⌘ 2 ¯D and ker( ) Tx0 = {0}](https://image.slidesharecdn.com/2013-07-02-sampta-gauges-130709141101-phpapp01/85/Model-Selection-with-Piecewise-Regular-Gauges-35-320.jpg)





![⌘0 = argmin
⌘= ⇤q,⌘T =e
||q||
⌘ 2 D ()
We assume ker( ) T = {0} and J piecewise regular.
and J (⌘) = 1
Minimal-norm Certificate
Proposition:
||w|| = O(⌫x0 ) and ⇠ ||w||,Theorem:
the unique solution x?
of P (y) for y = x0 + w satisfies
Tx? = Tx0
and ||x?
x0|| = O(||w||) [Vaiter et al. 2013]
One has
⌘ = ⇤
q
⌘T = e
Minimal-norm pre-certificate:
⇢
T = Tx0
e = ex0
⌘0 = ( +
T )⇤
e
If ⌘0 2 ¯D,](https://image.slidesharecdn.com/2013-07-02-sampta-gauges-130709141101-phpapp01/85/Model-Selection-with-Piecewise-Regular-Gauges-41-320.jpg)
![[Fuchs 2004]: J = || · ||1.
[Bach 2008]: J = || · ||1,2 and J = || · ||⇤.
[Vaiter et al. 2011]: J = ||D⇤
· ||1.
⌘0 = argmin
⌘= ⇤q,⌘T =e
||q||
⌘ 2 D ()
We assume ker( ) T = {0} and J piecewise regular.
and J (⌘) = 1
Minimal-norm Certificate
Proposition:
||w|| = O(⌫x0 ) and ⇠ ||w||,Theorem:
the unique solution x?
of P (y) for y = x0 + w satisfies
Tx? = Tx0
and ||x?
x0|| = O(||w||) [Vaiter et al. 2013]
One has
⌘ = ⇤
q
⌘T = e
Minimal-norm pre-certificate:
⇢
T = Tx0
e = ex0
⌘0 = ( +
T )⇤
e
If ⌘0 2 ¯D,](https://image.slidesharecdn.com/2013-07-02-sampta-gauges-130709141101-phpapp01/85/Model-Selection-with-Piecewise-Regular-Gauges-42-320.jpg)
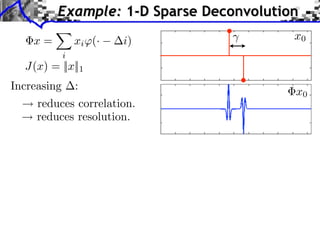
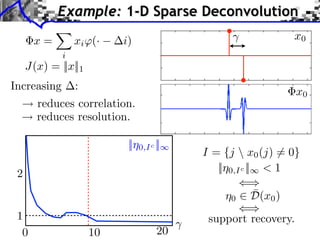

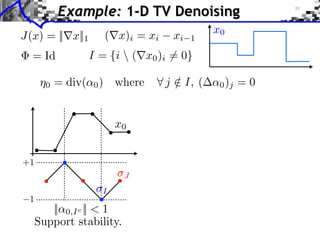
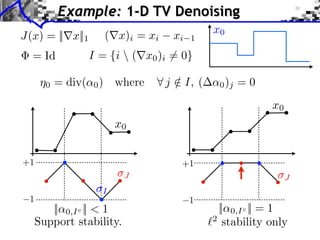
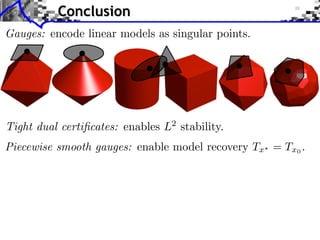
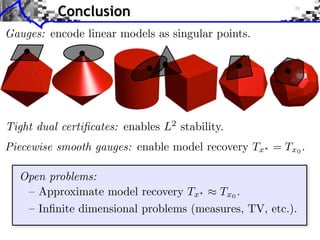

The document discusses model selection and gauge decomposition in inverse problems, focusing on how to recover a signal from noisy observations using regularized inversion methods. It highlights various stability performances and the conditions required for effective data fidelity and regularity in model spaces. The analysis covers concepts such as sparsity, low-rank matrices, and dual certificates related to optimization problems.





















































































