Download as PDF, PPTX













![Function: ˜f : x 2 R2
7! f(x) 2 R
Discrete image: f 2 RN
, N = n2
f[i1, i2] = ˜f(i1/n, i2/n) rf[i] ⇡ r ˜f(i/n)
˜f(x + ") = ˜f(x) + hrf(x), "iR2 + O(||"||2
R2 )
r ˜f(x) = (@1
˜f(x), @2
˜f(x)) 2 R2
Gradient: Images vs. Functionals](https://image.slidesharecdn.com/course-signal-inverse-pbm-variational-130615133703-phpapp01/85/Signal-Processing-Course-Inverse-Problems-Regularization-14-320.jpg)
![Function: ˜f : x 2 R2
7! f(x) 2 R
Discrete image: f 2 RN
, N = n2
f[i1, i2] = ˜f(i1/n, i2/n)
Functional: J : f 2 RN
7! J(f) 2 R
J(f + ⌘) = J(f) + hrJ(f), ⌘iRN + O(||⌘||2
RN )
rf[i] ⇡ r ˜f(i/n)
˜f(x + ") = ˜f(x) + hrf(x), "iR2 + O(||"||2
R2 )
r ˜f(x) = (@1
˜f(x), @2
˜f(x)) 2 R2
rJ : RN
7! RN
Gradient: Images vs. Functionals](https://image.slidesharecdn.com/course-signal-inverse-pbm-variational-130615133703-phpapp01/85/Signal-Processing-Course-Inverse-Problems-Regularization-15-320.jpg)
![Function: ˜f : x 2 R2
7! f(x) 2 R
Discrete image: f 2 RN
, N = n2
f[i1, i2] = ˜f(i1/n, i2/n)
Functional: J : f 2 RN
7! J(f) 2 R
Sobolev:
rJ(f) = (r⇤
r)f = f
J(f) =
1
2
||rf||2
J(f + ⌘) = J(f) + hrJ(f), ⌘iRN + O(||⌘||2
RN )
rf[i] ⇡ r ˜f(i/n)
˜f(x + ") = ˜f(x) + hrf(x), "iR2 + O(||"||2
R2 )
r ˜f(x) = (@1
˜f(x), @2
˜f(x)) 2 R2
rJ : RN
7! RN
Gradient: Images vs. Functionals](https://image.slidesharecdn.com/course-signal-inverse-pbm-variational-130615133703-phpapp01/85/Signal-Processing-Course-Inverse-Problems-Regularization-16-320.jpg)
![rJ(f) = div
✓
rf
||rf||
◆
If 8 n, rf[n] 6= 0,
If 9n, rf[n] = 0, J not di↵erentiable at f.
Total Variation Gradient
||rf||
rJ(f)](https://image.slidesharecdn.com/course-signal-inverse-pbm-variational-130615133703-phpapp01/85/Signal-Processing-Course-Inverse-Problems-Regularization-17-320.jpg)
![rJ(f) = div
✓
rf
||rf||
◆
If 8 n, rf[n] 6= 0,
Sub-di↵erential:
If 9n, rf[n] = 0, J not di↵erentiable at f.
Cu = ↵ 2 R2⇥N
(u[n] = 0) ) (↵[n] = u[n]/||u[n]||)
@J(f) = { div(↵) ; ||↵[n]|| 6 1 and ↵ 2 Crf }
Total Variation Gradient
||rf||
rJ(f)](https://image.slidesharecdn.com/course-signal-inverse-pbm-variational-130615133703-phpapp01/85/Signal-Processing-Course-Inverse-Problems-Regularization-18-320.jpg)
![−10 −8 −6 −4 −2 0 2 4 6 8 10
−2
0
2
4
6
8
10
12
−10 −8 −6 −4 −2 0 2 4 6 8 10
−2
0
2
4
6
8
10
12
p
x2 + "2
|x|
Regularized Total Variation
||u||" =
p
||u||2 + "2 J"(f) =
P
n ||rf[n]||"](https://image.slidesharecdn.com/course-signal-inverse-pbm-variational-130615133703-phpapp01/85/Signal-Processing-Course-Inverse-Problems-Regularization-19-320.jpg)
![−10 −8 −6 −4 −2 0 2 4 6 8 10
−2
0
2
4
6
8
10
12
−10 −8 −6 −4 −2 0 2 4 6 8 10
−2
0
2
4
6
8
10
12
rJ"(f) = div
✓
rf
||rf||"
◆
p
x2 + "2
|x|
rJ" ⇠ /" when " ! +1
Regularized Total Variation
||u||" =
p
||u||2 + "2 J"(f) =
P
n ||rf[n]||"
rJ"(f)](https://image.slidesharecdn.com/course-signal-inverse-pbm-variational-130615133703-phpapp01/85/Signal-Processing-Course-Inverse-Problems-Regularization-20-320.jpg)





















![Mask M, = diagi(1i2M )
Example: InpaintingFigure 3 shows iterations of the algorithm 1 to solve the inpainting problem
on a smooth image using a manifold prior with 2D linear patches, as defined in
16. This manifold together with the overlapping of the patches allow a smooth
interpolation of the missing pixels.
Measurements y Iter. #1 Iter. #3 Iter. #50
Fig. 3. Iterations of the inpainting algorithm on an uniformly regular image.
5 Manifold of Step Discontinuities
In order to introduce some non-linearity in the manifold M, one needs to go
log10(||f(k)
f( )
||/||f0||)
k k
E(f(k)
)
M
( f)[i] =
⇢
0 if i 2 M,
f[i] otherwise.](https://image.slidesharecdn.com/course-signal-inverse-pbm-variational-130615133703-phpapp01/85/Signal-Processing-Course-Inverse-Problems-Regularization-43-320.jpg)



![TV" regularization: (assuming 1 /2 ker( ))
f?
= argmin
f2RN
E(f) =
1
2
|| f y|| + J"
(f)
Total Variation Regularization
||u||" =
p
||u||2 + "2 J"(f) =
P
n ||rf[n]||"](https://image.slidesharecdn.com/course-signal-inverse-pbm-variational-130615133703-phpapp01/85/Signal-Processing-Course-Inverse-Problems-Regularization-47-320.jpg)
![TV" regularization: (assuming 1 /2 ker( ))
f(k+1)
= f(k)
⌧krE(f(k)
)
rE(f) = ⇤
( f y) + rJ"(f)
rJ"(f) = div
✓
rf
||rf||"
◆
Convergence: requires ⌧ ⇠ ".
Gradient descent:
f?
= argmin
f2RN
E(f) =
1
2
|| f y|| + J"
(f)
Total Variation Regularization
||u||" =
p
||u||2 + "2 J"(f) =
P
n ||rf[n]||"](https://image.slidesharecdn.com/course-signal-inverse-pbm-variational-130615133703-phpapp01/85/Signal-Processing-Course-Inverse-Problems-Regularization-48-320.jpg)
![TV" regularization: (assuming 1 /2 ker( ))
f(k+1)
= f(k)
⌧krE(f(k)
)
rE(f) = ⇤
( f y) + rJ"(f)
rJ"(f) = div
✓
rf
||rf||"
◆
Convergence: requires ⌧ ⇠ ".
Gradient descent:
f?
= argmin
f2RN
E(f) =
1
2
|| f y|| + J"
(f)
Newton descent:
f(k+1)
= f(k)
H 1
k rE(f(k)
) where Hk = @2
E"(f(k)
)
Total Variation Regularization
||u||" =
p
||u||2 + "2 J"(f) =
P
n ||rf[n]||"](https://image.slidesharecdn.com/course-signal-inverse-pbm-variational-130615133703-phpapp01/85/Signal-Processing-Course-Inverse-Problems-Regularization-49-320.jpg)


![Noiseless problem: f?
2 argmin
f
J"
(f) s.t. f 2 H
Contraint: H = {f ; f = y}.
f(k+1)
= ProjH
⇣
f(k)
⌧krJ"(f(k)
)
⌘
ProjH(f) = argmin
g=y
||g f||2
= f + ⇤
( ⇤
) 1
(y f)
Inpainting: ProjH(f)[i] =
⇢
f[i] if i 2 M,
y[i] otherwise.
Projected gradient descent:
f(k) k!+1
! f?
a solution of (?).
(?)
Projected Gradient Descent
Proposition: If rJ" is L-Lipschitz and 0 < ⌧k < 2/L,](https://image.slidesharecdn.com/course-signal-inverse-pbm-variational-130615133703-phpapp01/85/Signal-Processing-Course-Inverse-Problems-Regularization-52-320.jpg)



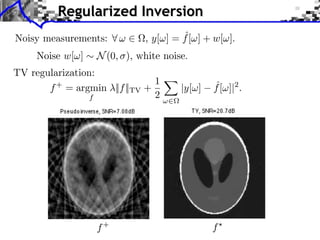
This document discusses regularization techniques for inverse problems. It introduces variational priors like Sobolev and total variation to regularize inverse problems. Gradient descent and proximal gradient methods are presented to minimize regularization functionals for problems like denoising. Conjugate gradient and projected gradient descent are discussed for solving the regularized inverse problems. Total variation priors are shown to better recover edges compared to Sobolev priors. Non-smooth optimization methods may be needed to handle non-differentiable total variation functionals.