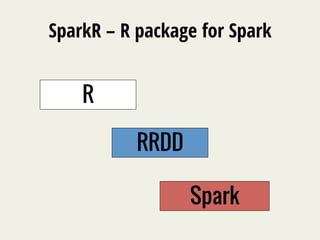
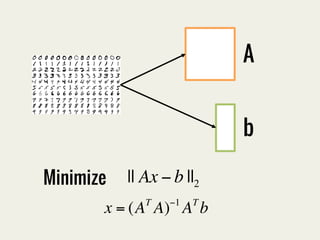
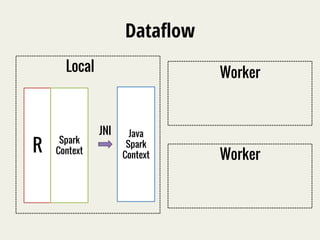
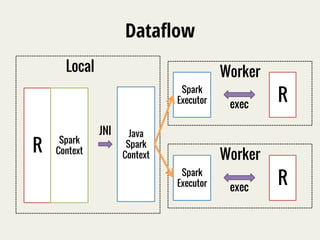
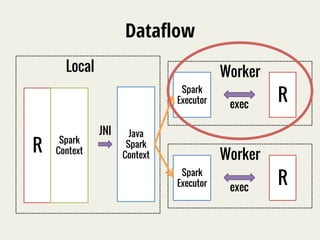
The document discusses SparkR, which enables interactive data science using R on Apache Spark clusters. SparkR allows users to create and manipulate resilient distributed datasets (RDDs) from R and run R analytics functions in parallel on large datasets. It provides examples of using SparkR for tasks like word counting on text data and digit classification using the MNIST dataset. The API is designed to be similar to PySpark for ease of use.










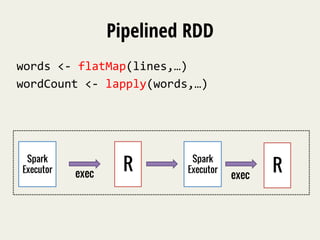
![Example: word_count.R
library(SparkR)
lines
<-‐
textFile(sc,
“hdfs://my_text_file”)
words
<-‐
flatMap(lines,
function(line)
{
strsplit(line,
"
")[[1]]
})
wordCount
<-‐
lapply(words,
function(word)
{
list(word,
1L)
})](https://image.slidesharecdn.com/e4p5z1b4thurensvl2lt-signature-9f1097b540f1c004e6501073d62b3a70af4704a05c67c402ba256f1c4f6d4951-poli-141121182858-conversion-gate02/85/SparkR-Enabling-Interactive-Data-Science-at-Scale-11-320.jpg)
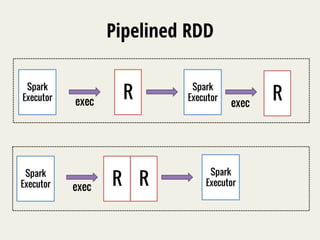
![Example: word_count.R
library(SparkR)
lines
<-‐
textFile(sc,
“hdfs://my_text_file”)
words
<-‐
flatMap(lines,
function(line)
{
strsplit(line,
"
")[[1]]
})
wordCount
<-‐
lapply(words,
function(word)
{
list(word,
1L)
})
counts
<-‐
reduceByKey(wordCount,
"+",
2L)
output
<-‐
collect(counts)](https://image.slidesharecdn.com/e4p5z1b4thurensvl2lt-signature-9f1097b540f1c004e6501073d62b3a70af4704a05c67c402ba256f1c4f6d4951-poli-141121182858-conversion-gate02/85/SparkR-Enabling-Interactive-Data-Science-at-Scale-12-320.jpg)









































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)













