Downloaded 176 times


![#MDBW17
WHO AM I?
{ "name": "Daniel Coupal",
"jobs_at_MongoDB": [
{ "job": "Senior Curriculum Engineer",
"from": new Date("2016-11") },
{ "job": "Senior Technical Service Engineer",
"from": new Date("2013-11") }
],
"previous_jobs": [
"Consultant",
"Developer",
"Manager Quality & Tools Team",
"Manager Software Team",
"Tools Developer"
],
"likes": [ "food", "beers", "movies", "MongoDB"
]
}](https://image.slidesharecdn.com/grandday11140-1220danielcoupaladvancedschemadesignpatterns-170623161353/85/Advanced-Schema-Design-Patterns-2-320.jpg)


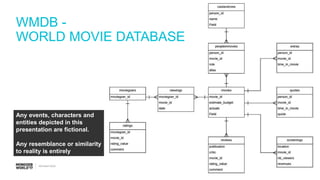
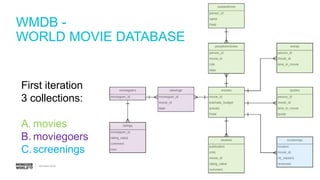


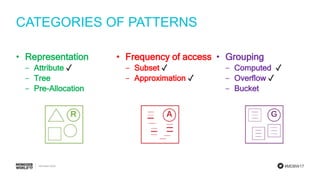






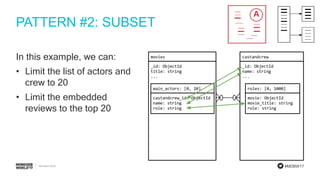





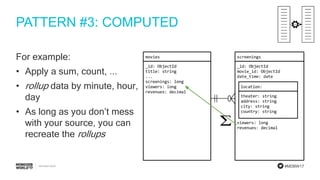



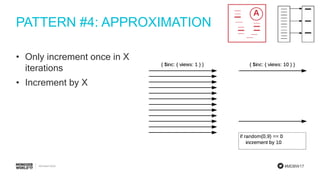




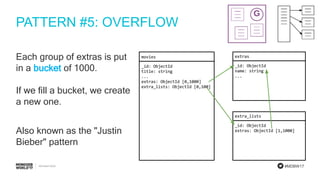










The document discusses schema design patterns for MongoDB databases. It introduces common patterns like attributes, subset, computed, and approximation. Attributes store optional fields as field-value pairs to index them easily. Subset duplicates a small subset of dependent documents to reduce working set size. Computed pre-calculates values to avoid repeated computations. Approximation uses fewer stronger writes by incrementing values less frequently. The talk aims to provide a common methodology for modeling schemas using these reusable patterns.























































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)


















![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)












