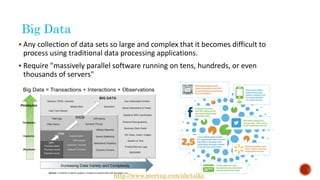
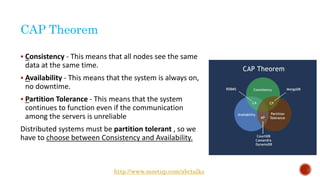
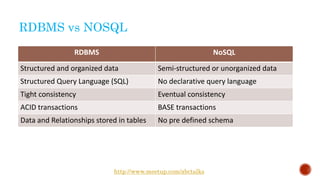
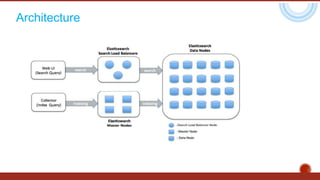
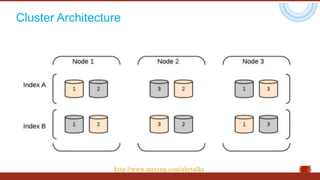
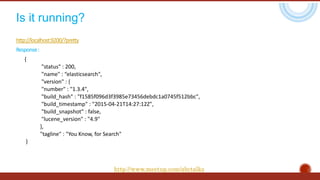
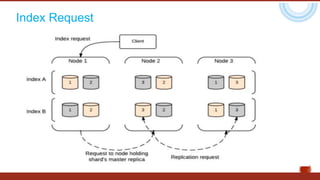
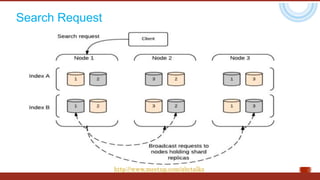
The document discusses the concept of big data, highlighting its characteristics like volume, variety, and velocity, as well as the evolution of NoSQL databases designed to handle large and complex datasets. It provides an introduction to Elasticsearch, a distributed open-source search engine built on Apache Lucene, detailing its features, architecture, and operational capabilities such as horizontal scaling and RESTful API usage. Comparisons between RDBMS and NoSQL databases, as well as the CAP theorem, are also explored in relation to data processing needs and architectural considerations.



















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)










