Downloaded 249 times








![Indexing
# sources for mysql binary logs
sources:
- name : airslave
host : localhost
port : 11
user : spinaltap
password: spinaltap
- name : calendar_db
host : localhost
port : 11
user : spinaltap
password: spinaltap
!
destinations:
- name : kafka
clazzName :
com.airbnb.spinaltap.destination.kafka.KafkaDestination
!
pipes:
- name : search
sources : [“airslave", "calendar_db"]
tables : ["production:listings,calendar_db:schedule2s"]
destination : kafka
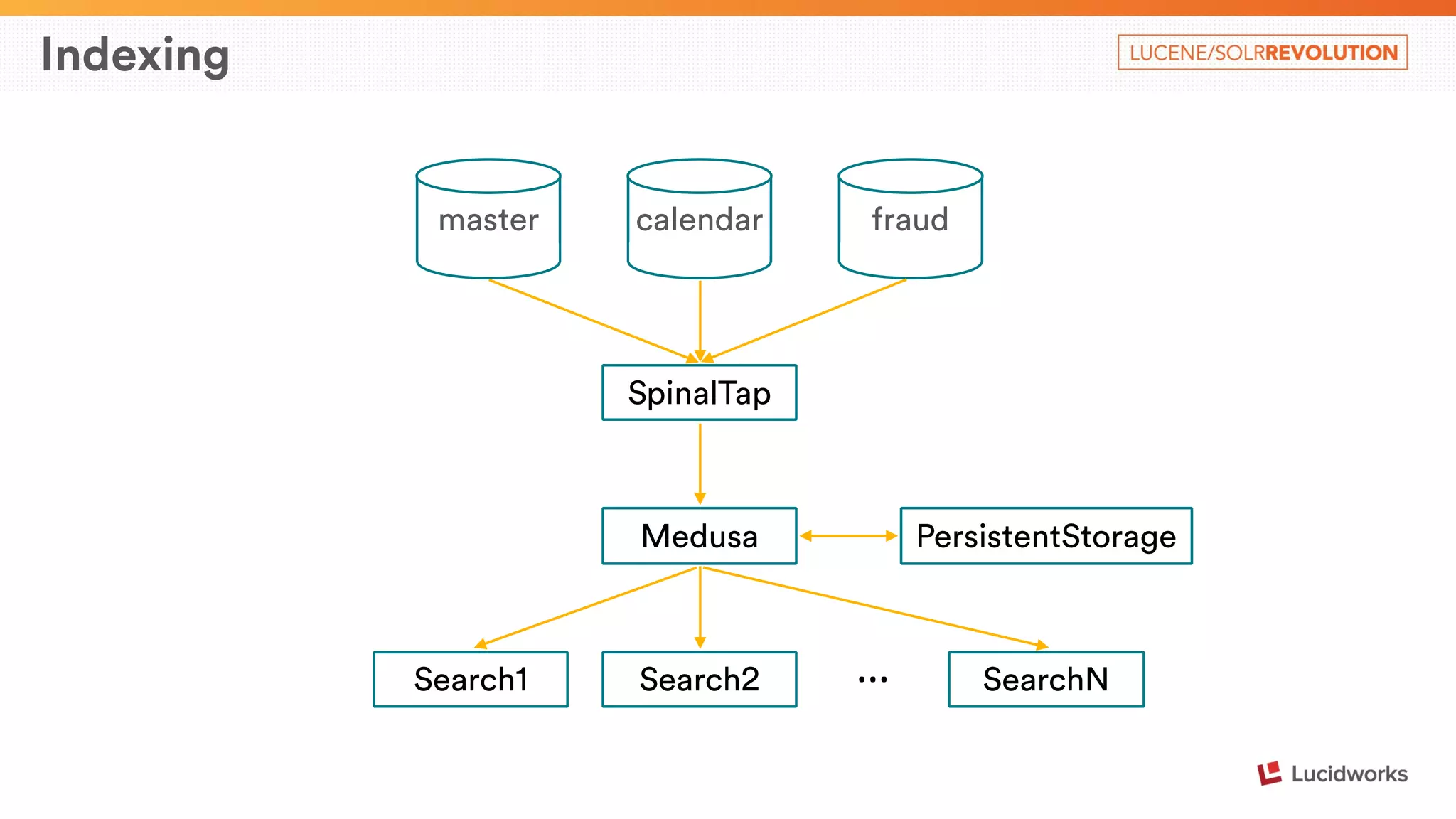
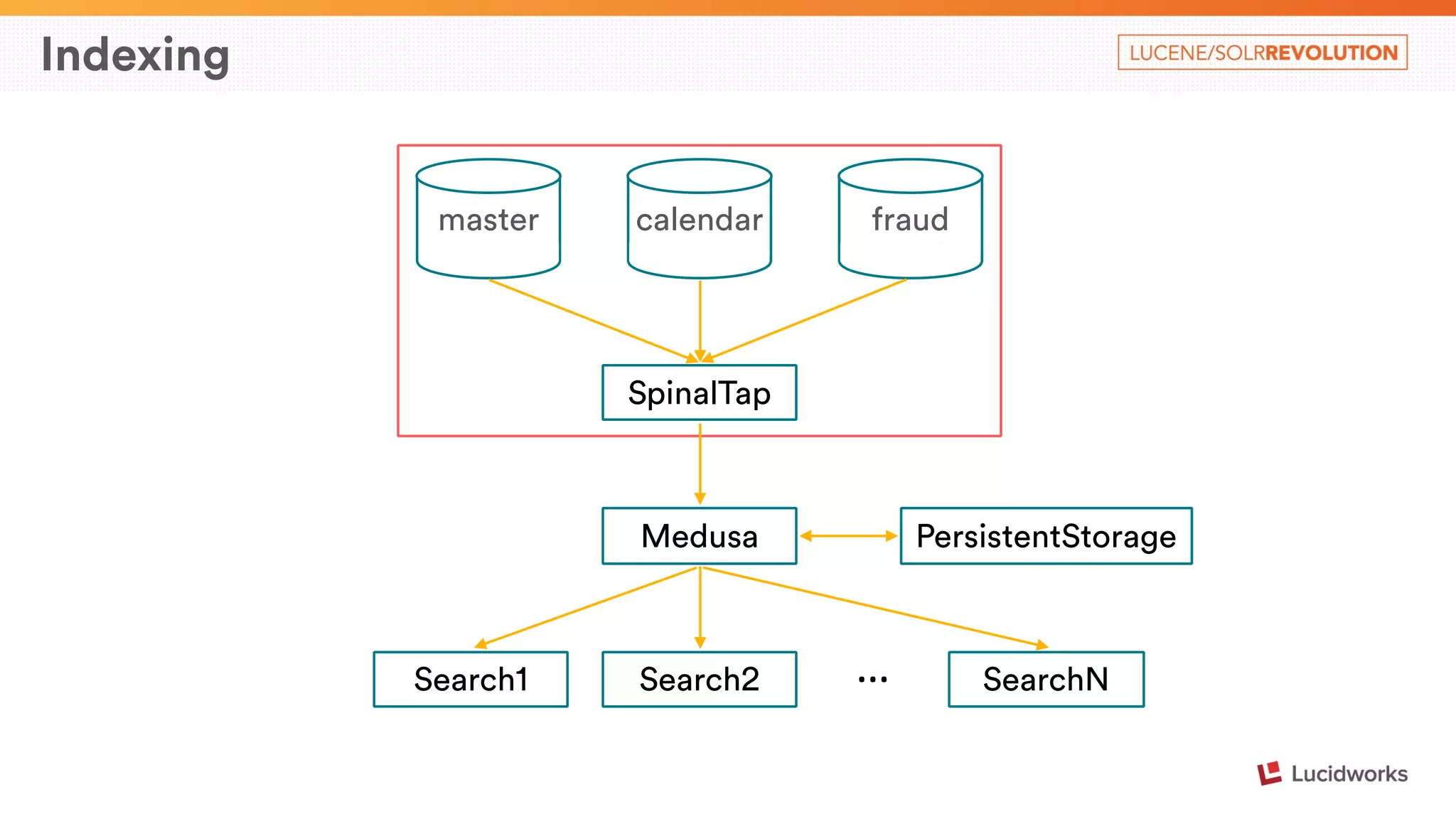
SpinalTap Pipes
____________________________
Each pipe connects one or more binlog sources (MySQL) with a
destination (e.g. Kafka)
Configured via YAML files](https://image.slidesharecdn.com/airbnbsearcharchitecture-maximcharkov-141124123614-conversion-gate01/75/Airbnb-Search-Architecture-Presented-by-Maxim-Charkov-Airbnb-13-2048.jpg)
![Indexing
{
"seq" : 3,
"binlogpos" : "mysql-bin.000002:5217:5273",
"id" : -1857589909002862756,
"type" : 2,
"table" : {
"id" : 70,
"name" : "users",
"db" : "my_db",
"columns" : [ {
"name" : "name",
"type" : 15,
"ispk" : false
}, {
"name" : "age",
"type" : 2,
"ispk" : false
} ]
},
"rows" : [ {
"1" : {
"name" : "eric",
"age" : 31,
},
"2" : {
"name" : "eric",
"age" : 28,
}
} ]
}
SpinalTap Mutations
____________________________
Each binlog entry is parsed and converted into one of three
event types: “Insert”, “Delete” or “Update”
“Insert” and “Delete” carry the entire row to be inserted or
deleted
“Update” mutations contain both the old and the current row
Additional information: unique id, sequence number, column
and table metadata](https://image.slidesharecdn.com/airbnbsearcharchitecture-maximcharkov-141124123614-conversion-gate01/75/Airbnb-Search-Architecture-Presented-by-Maxim-Charkov-Airbnb-14-2048.jpg)

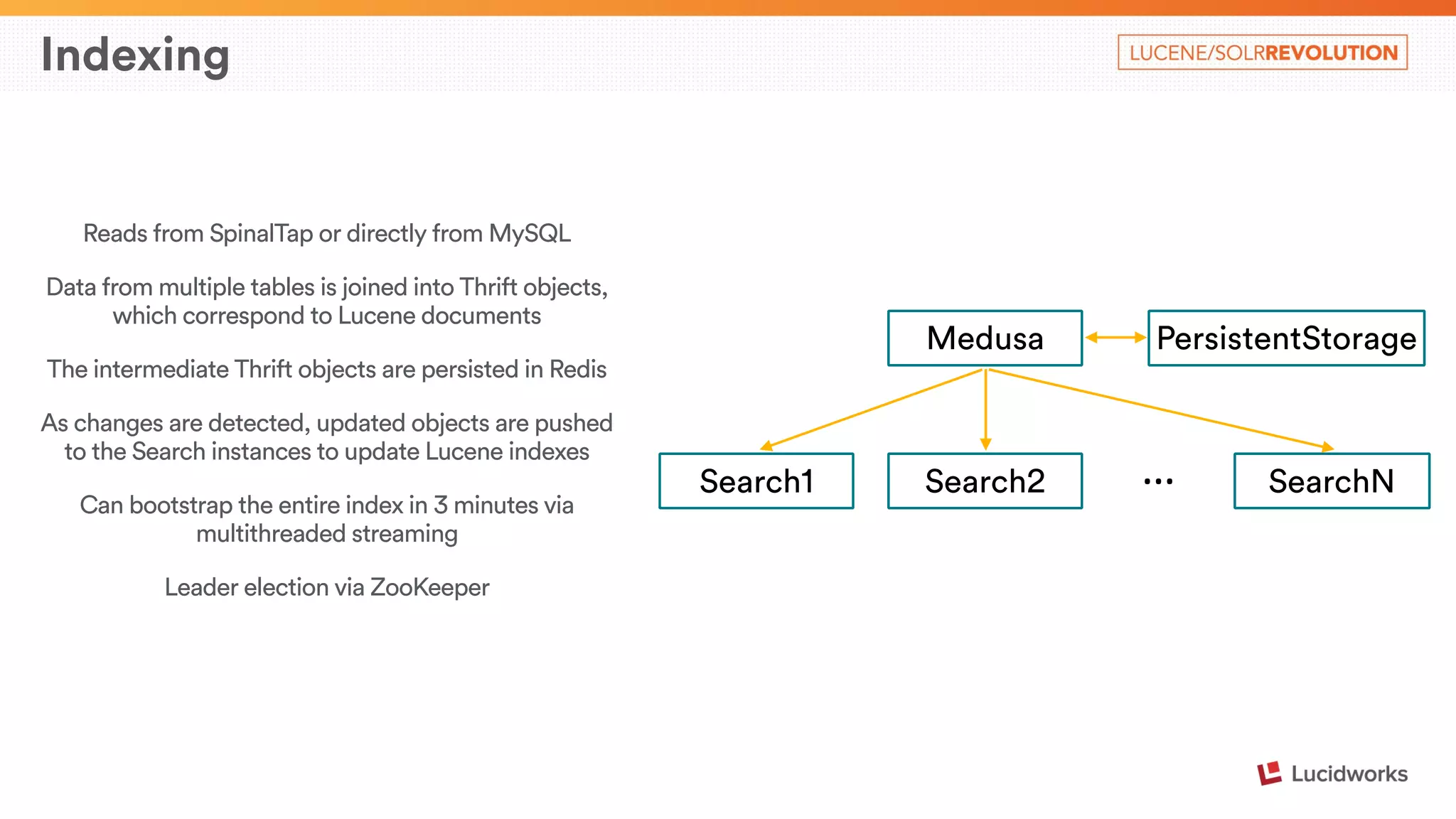


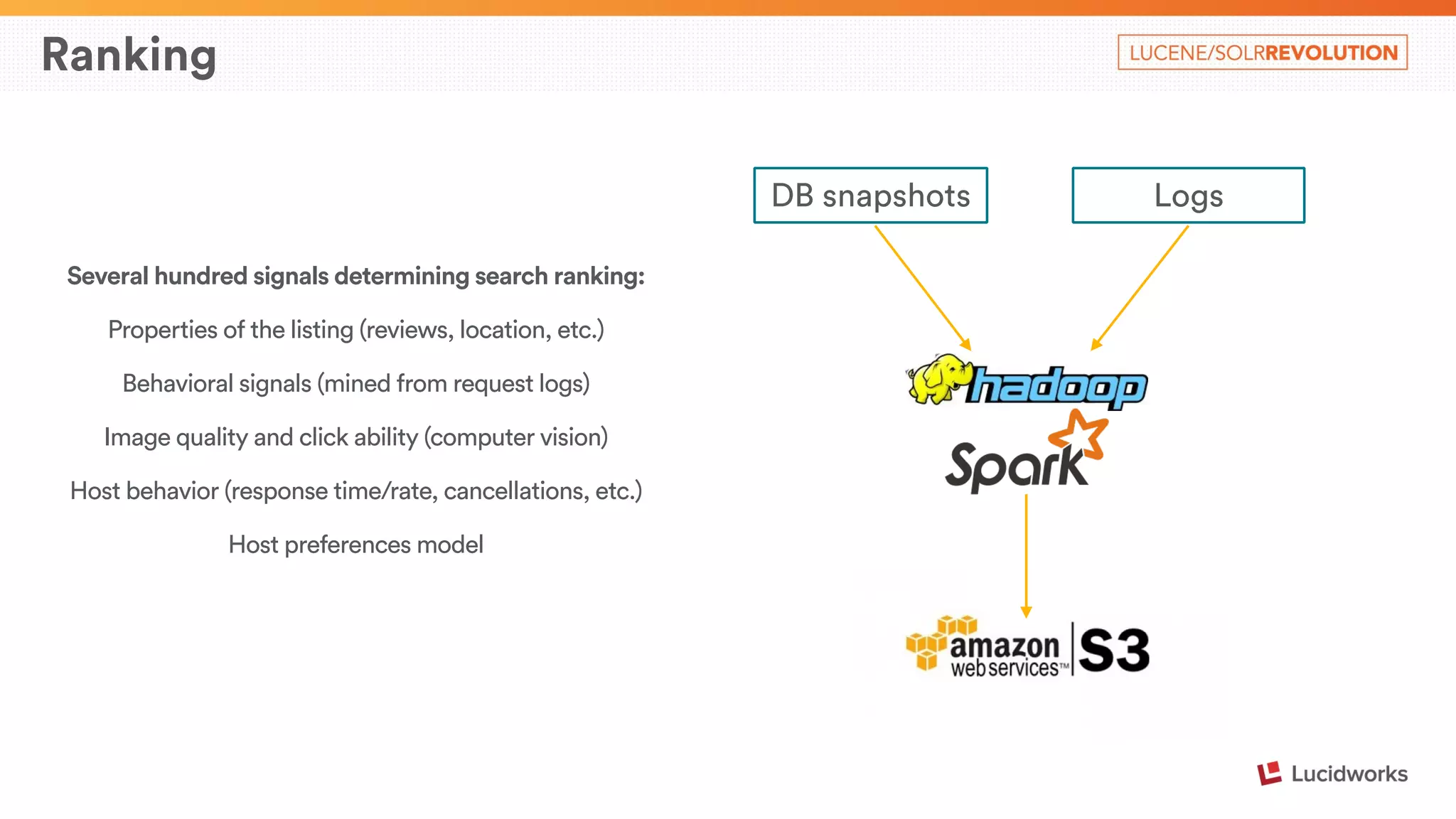

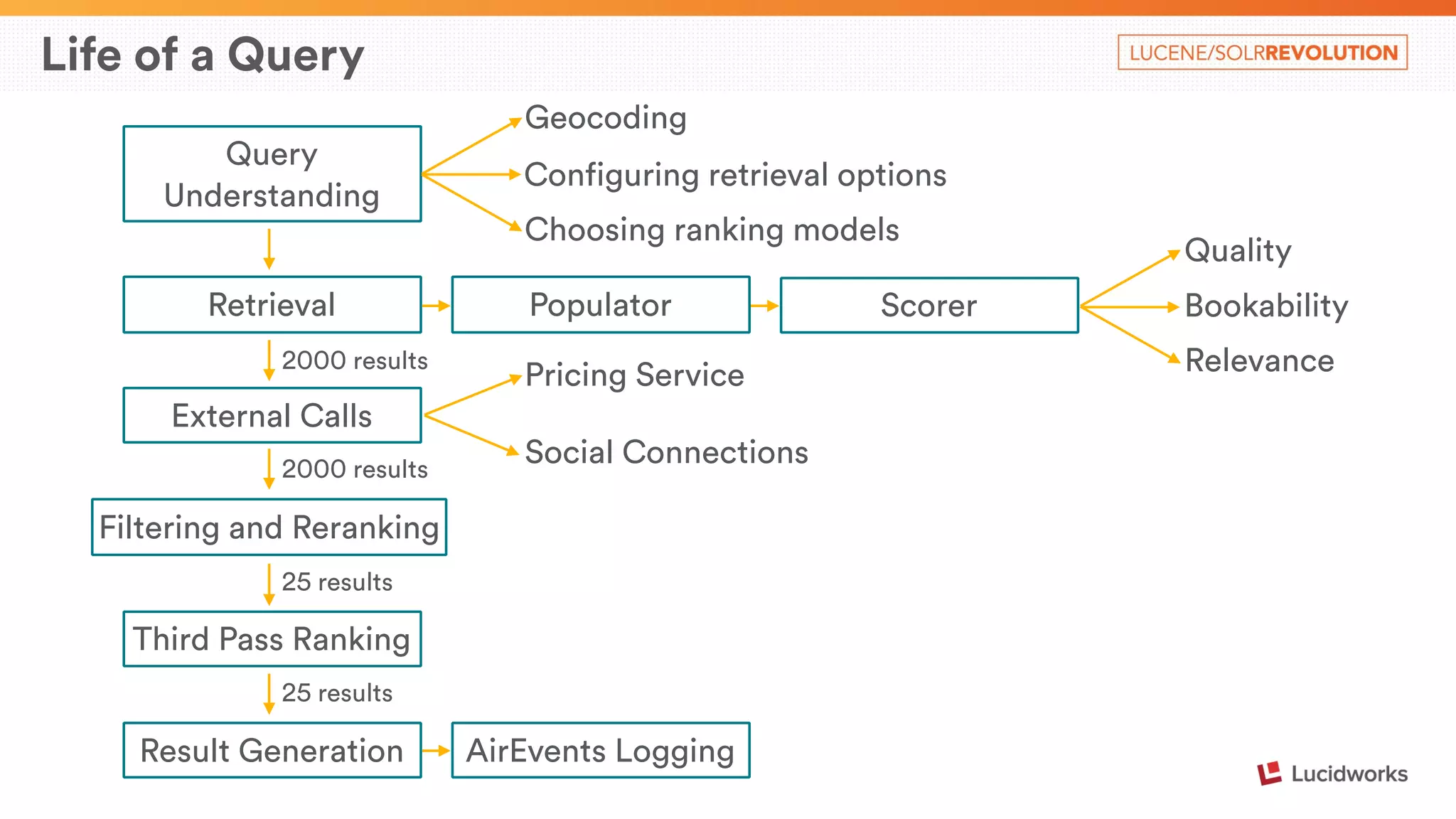

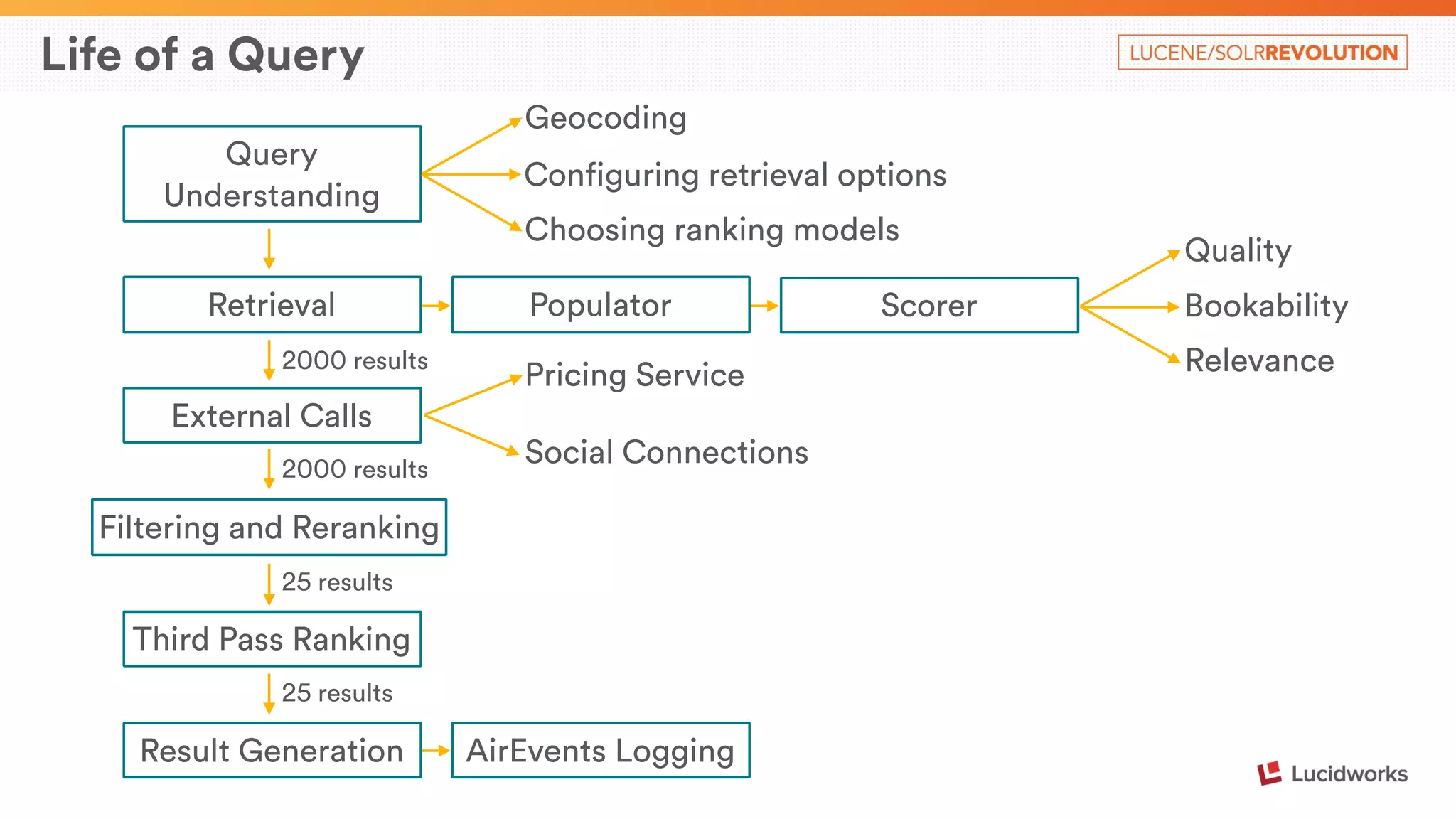
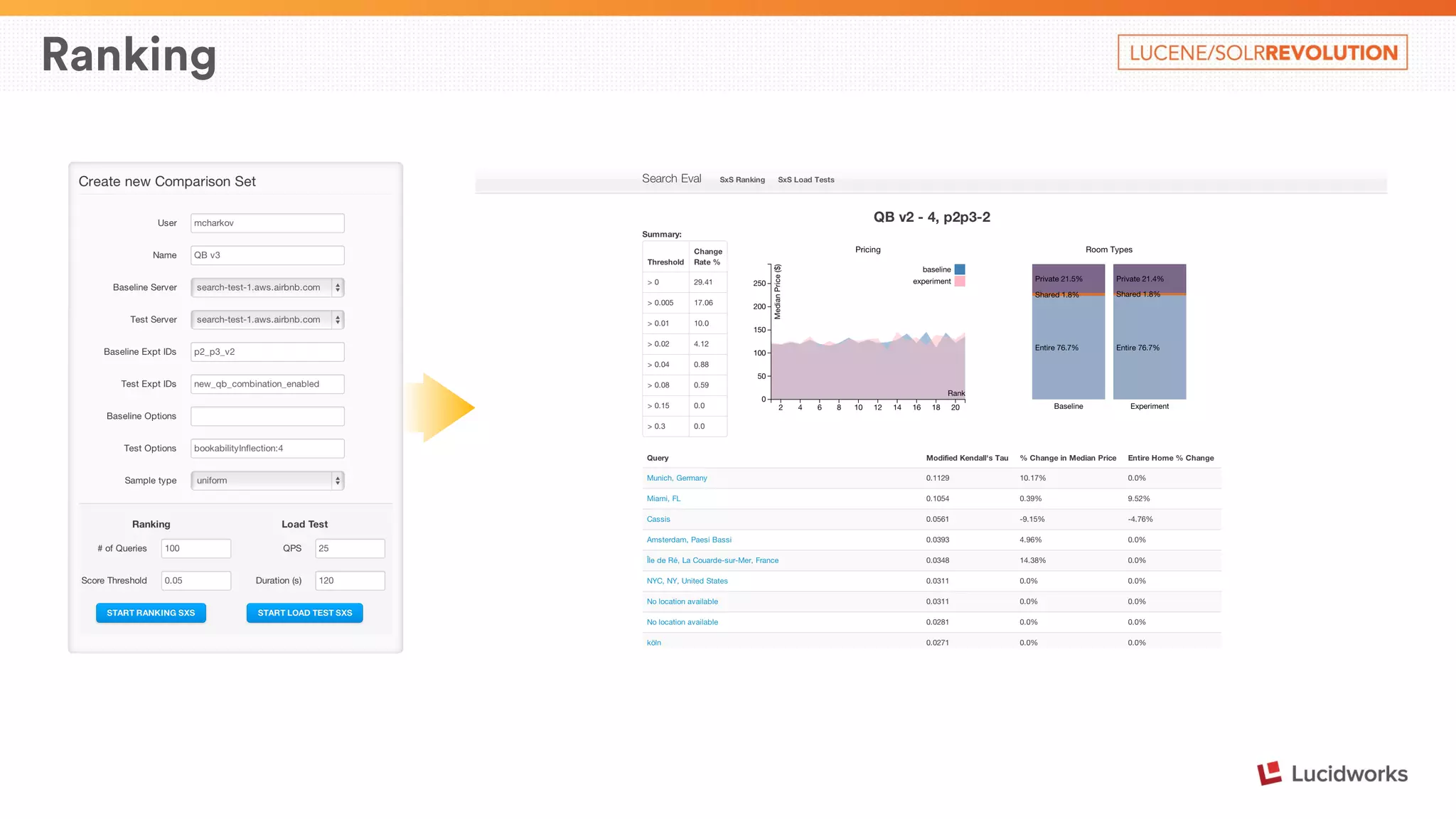
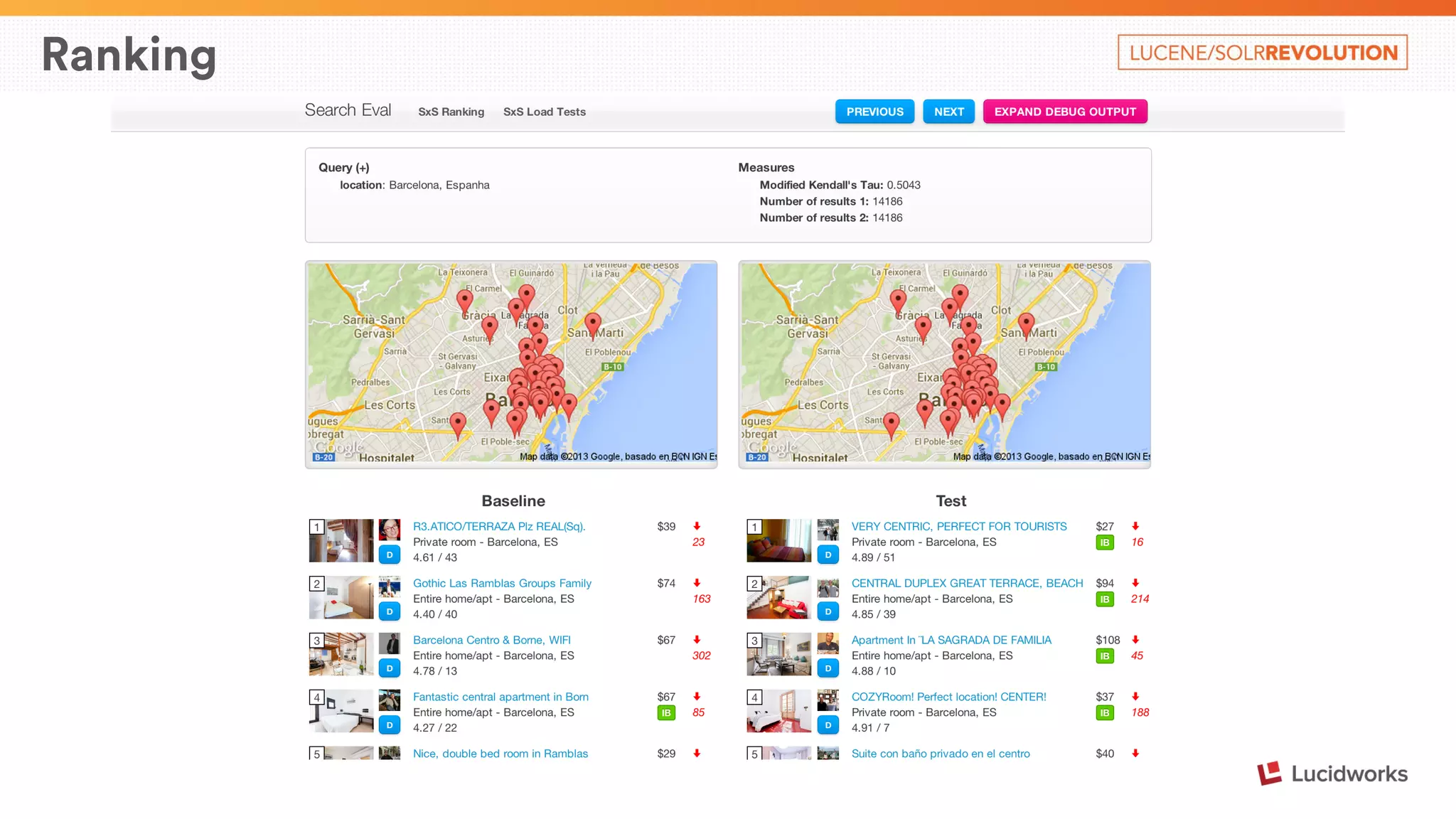
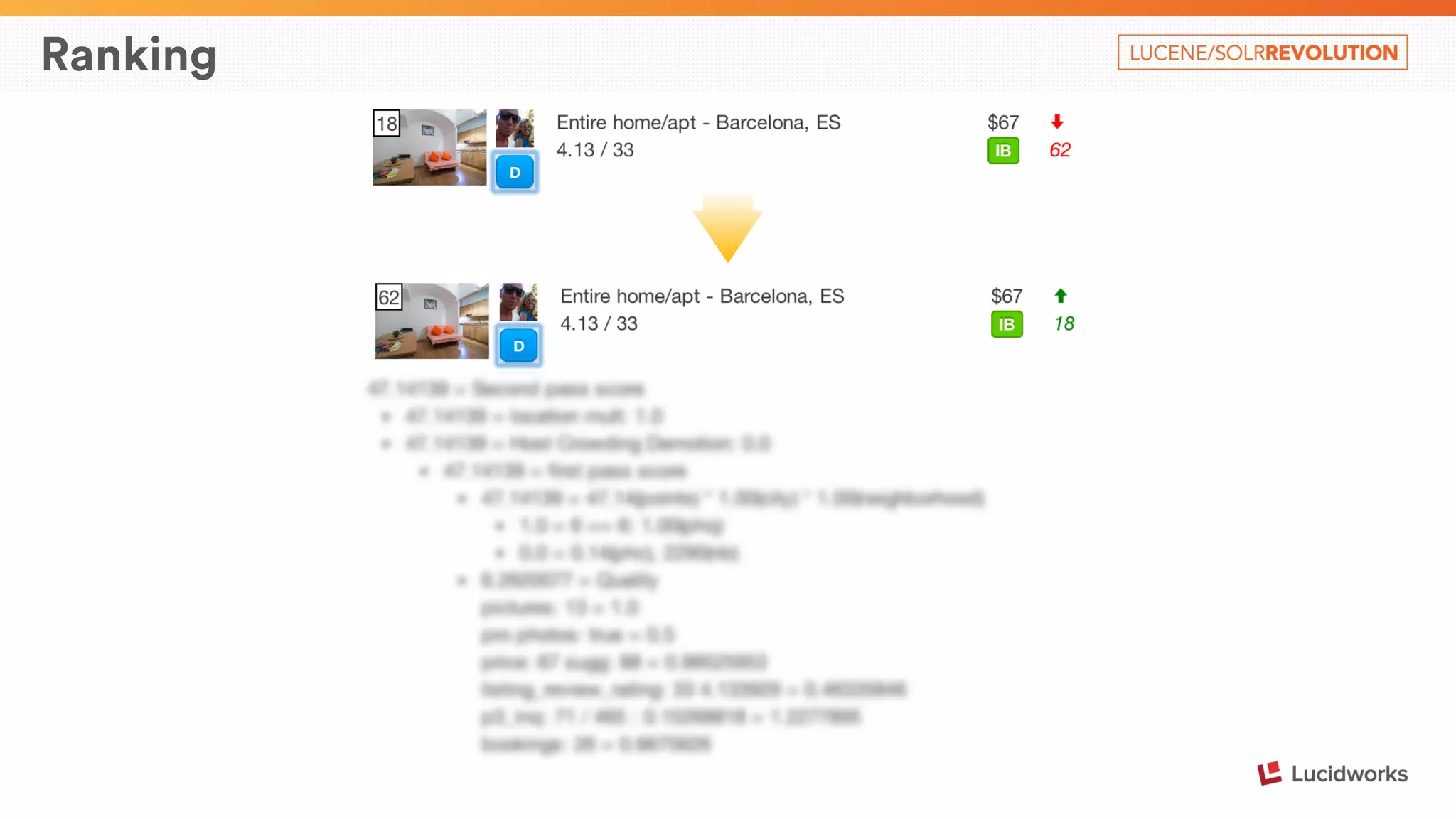
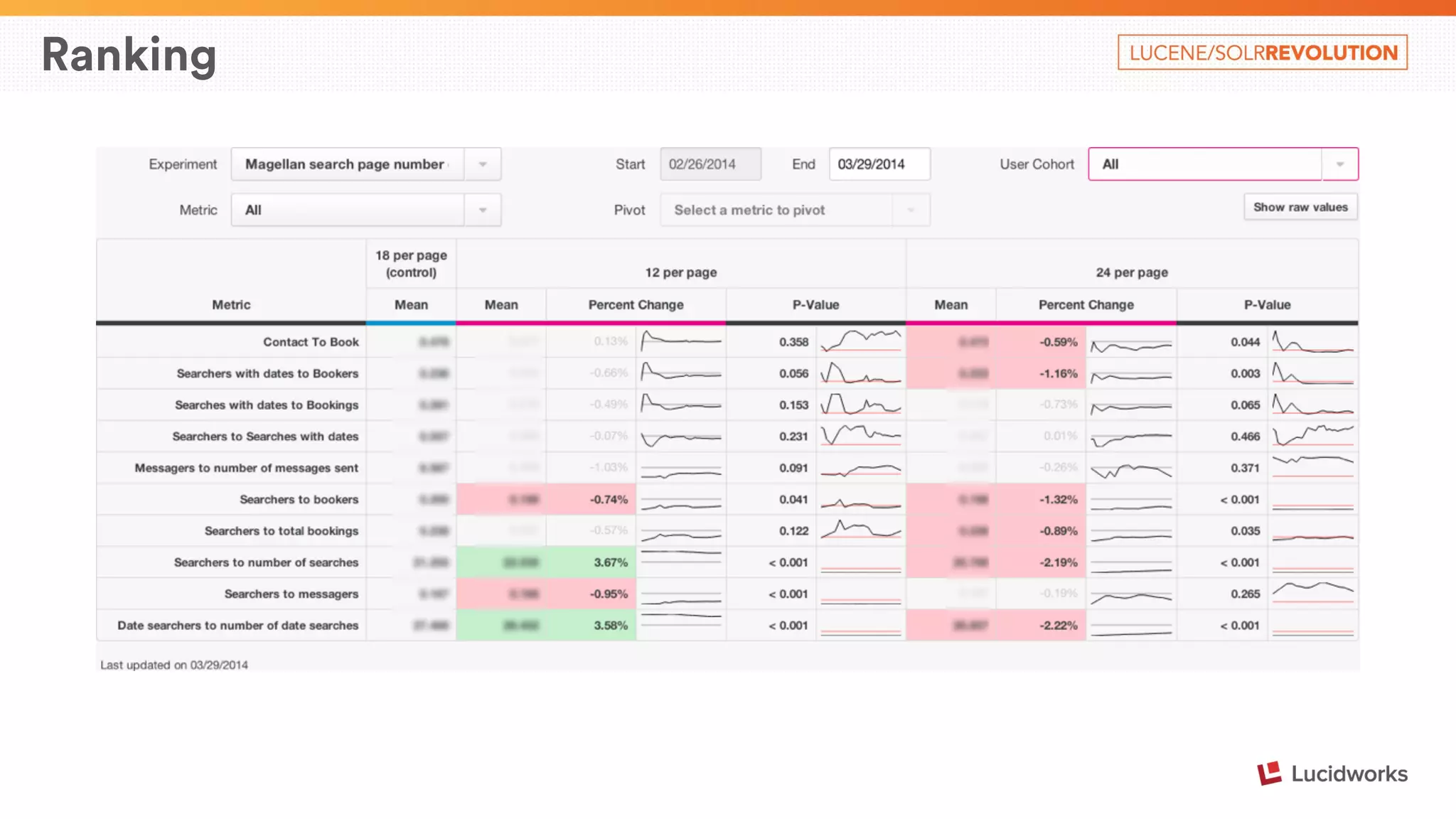



The document describes Airbnb's search architecture. It discusses how Airbnb indexes over 800,000 listings across 190 countries using Lucene and maintains the index in real-time. It also covers the various components involved in ranking search results, including over 150 ranking signals, loading ranking models, and performing second pass ranking on results.



























![[KAIST 채용설명회] 데이터 엔지니어는 무슨 일을 하나요?](https://cdn.slidesharecdn.com/ss_thumbnails/temp-180502031907-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[Webinar] Intelligent Policing. Leveraging Data to more effectively Serve Com...](https://cdn.slidesharecdn.com/ss_thumbnails/insightdrivenpolicingv2-201027222903-thumbnail.jpg?width=640&height=640&fit=bounds)
































