Downloaded 99 times


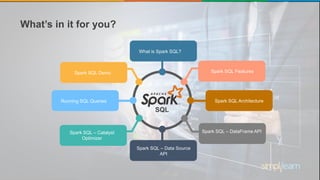




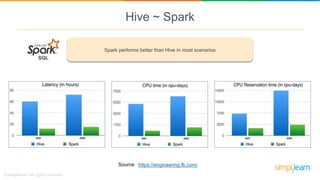




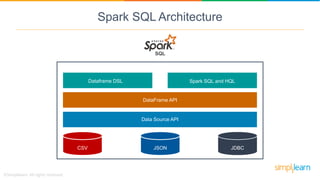
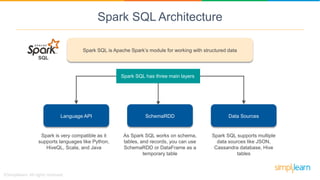



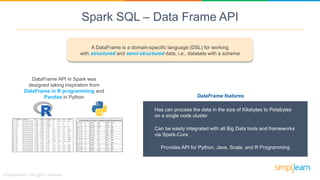



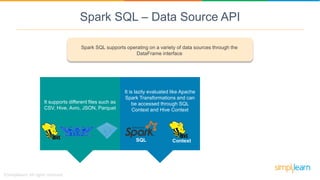
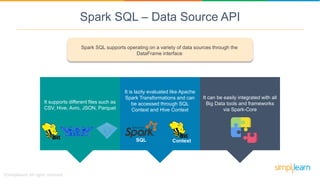


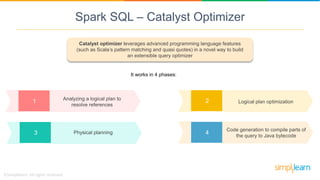




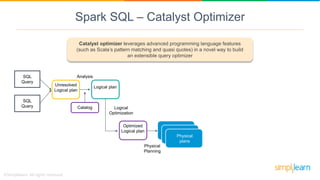
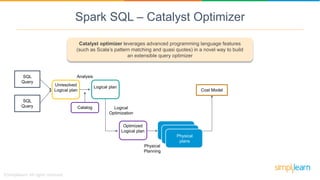
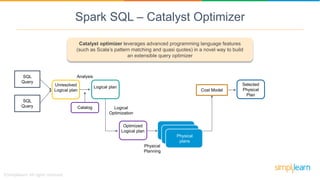
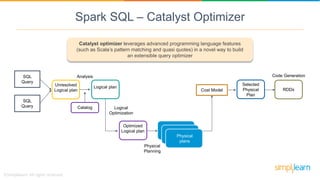





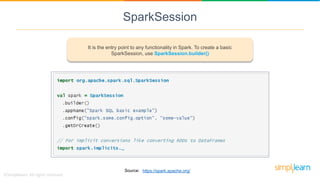
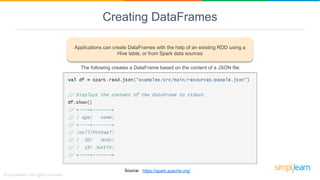









Spark SQL is a module of Apache Spark designed for handling structured and semi-structured data, improving upon the limitations of Apache Hive by offering better performance and fault tolerance. It features a robust architecture with support for multiple programming languages and data sources, leveraging DataFrames and a Catalyst optimizer for efficient query execution. Users can run SQL queries and process large datasets seamlessly using Spark's integrated capabilities.























































































