Download as PDF, PPTX









![Power of data. Simplicity of design. Speed of innovation.
IBM Spark
spark.tc
spark.tc
Power of data. Simplicity of design. Speed of innovation.
IBM Spark
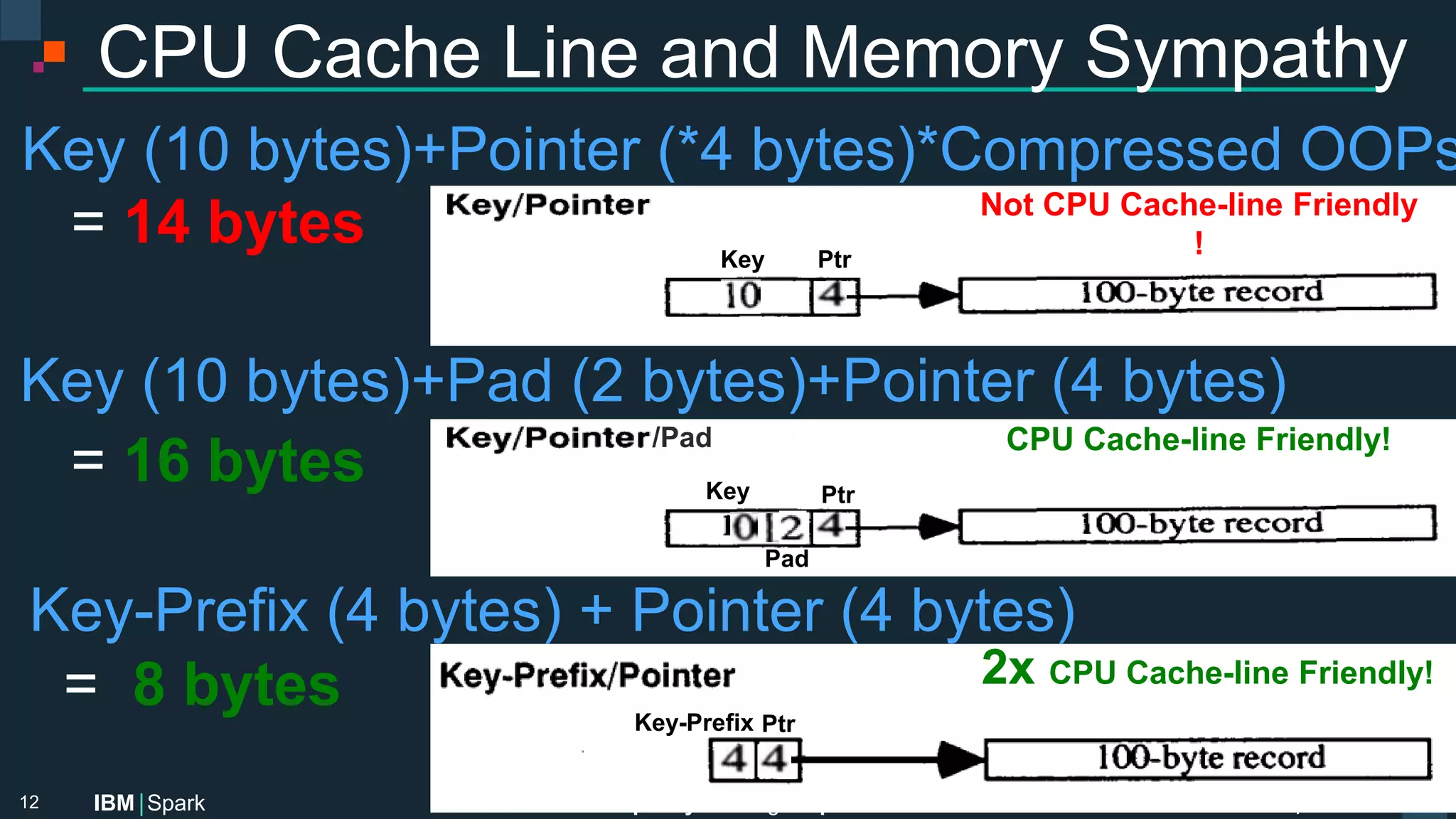
AlphaSort Technique: Sort 100 Bytes Recs
11
Value
Ptr
Key
Dereference Not Required!
AlphaSort
List [(Key, Pointer)]
Key is directly available for comparison
Naïve
List [Pointer]
Must dereference key for comparison
Ptr
Dereference for Key Comparison
Key](https://image.slidesharecdn.com/advancedapachesparkmeetup-projecttungsten-nov122015-151113030443-lva1-app6891/75/Advanced-Apache-Spark-Meetup-Project-Tungsten-Nov-12-2015-11-2048.jpg)

![Power of data. Simplicity of design. Speed of innovation.
IBM Spark
spark.tc
spark.tc
Power of data. Simplicity of design. Speed of innovation.
IBM Spark
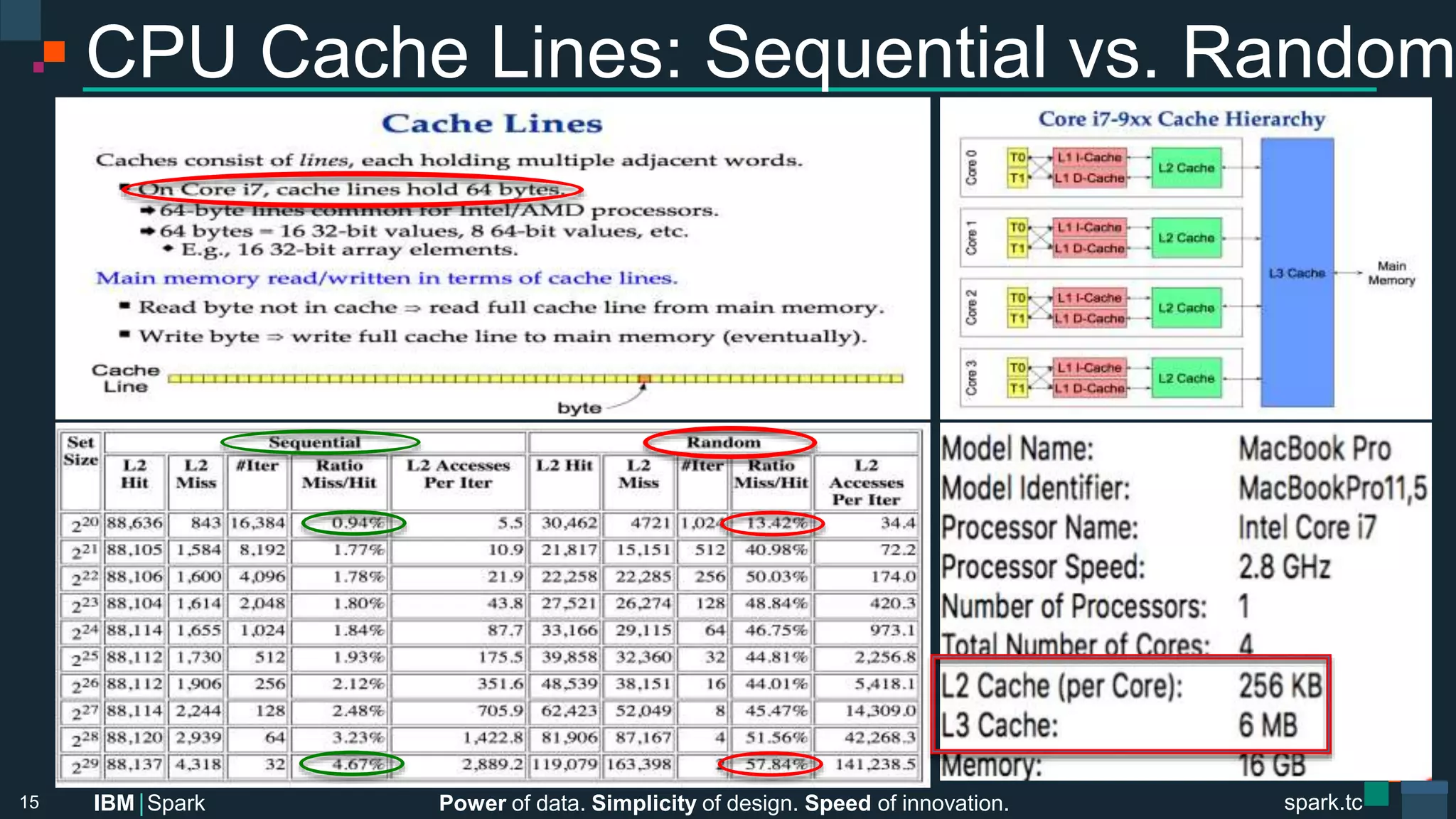
CPU Cache Naïve Matrix Multiplication
// Dot product of each row & column vector
for (i <- 0 until numRowA)
for (j <- 0 until numColsB)
for (k <- 0 until numColsA)
res[ i ][ j ] += matA[ i ][ k ] * matB[ k ][ j ];
16
Bad: Row-wise traversal,
not using CPU cache line,
ineffective pre-fetching](https://image.slidesharecdn.com/advancedapachesparkmeetup-projecttungsten-nov122015-151113030443-lva1-app6891/75/Advanced-Apache-Spark-Meetup-Project-Tungsten-Nov-12-2015-16-2048.jpg)
![Power of data. Simplicity of design. Speed of innovation.
IBM Spark
spark.tc
spark.tc
Power of data. Simplicity of design. Speed of innovation.
IBM Spark
CPU Cache Friendly Matrix Multiplication
// Transpose B
for (i <- 0 until numRowsB)
for (j <- 0 until numColsB)
matBT[ i ][ j ] = matB[ j ][ i ];
// Modify dot product calculation for B Transpose
for (i <- 0 until numRowsA)
for (j <- 0 until numColsB)
for (k <- 0 until numColsA)
res[ i ][ j ] += matA[ i ][ k ] * matBT[ j ][ k ];
17
Good: Full CPU cache line,
effective prefetching
OLD: res[ i ][ j ] += matA[ i ][ k ] * matB [ k ] [ j ];
Reference j
before k](https://image.slidesharecdn.com/advancedapachesparkmeetup-projecttungsten-nov122015-151113030443-lva1-app6891/75/Advanced-Apache-Spark-Meetup-Project-Tungsten-Nov-12-2015-17-2048.jpg)











![Power of data. Simplicity of design. Speed of innovation.
IBM Spark
spark.tc
spark.tc
Power of data. Simplicity of design. Speed of innovation.
IBM Spark
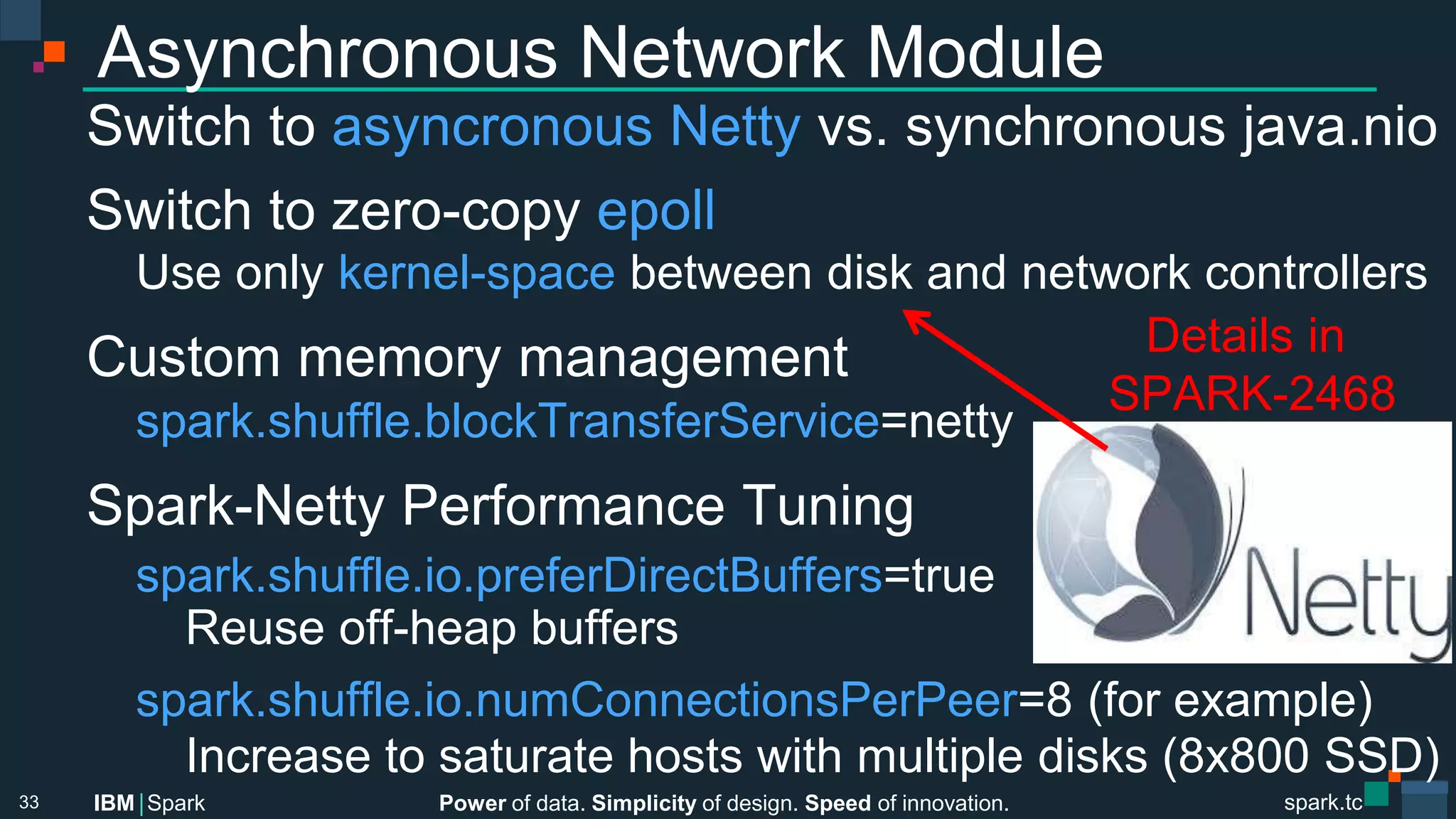
Custom Algorithms and Data Structures
Optimized for sort & shuffle workloads
o.a.s.util.collection.TimSort[K,V]
Based on JDK 1.7 TimSort
Performs best with partially-sorted runs
Optimized for elements of (K,V) pairs
Sorts impl of SortDataFormat (ie. KVArraySortDataFormat)
o.a.s.util.collection.AppendOnlyMap
Open addressing hash, quadratic probing
Array of [(K, V), (K, V)]
Good memory locality
Keys never removed, values only append
34](https://image.slidesharecdn.com/advancedapachesparkmeetup-projecttungsten-nov122015-151113030443-lva1-app6891/75/Advanced-Apache-Spark-Meetup-Project-Tungsten-Nov-12-2015-34-2048.jpg)





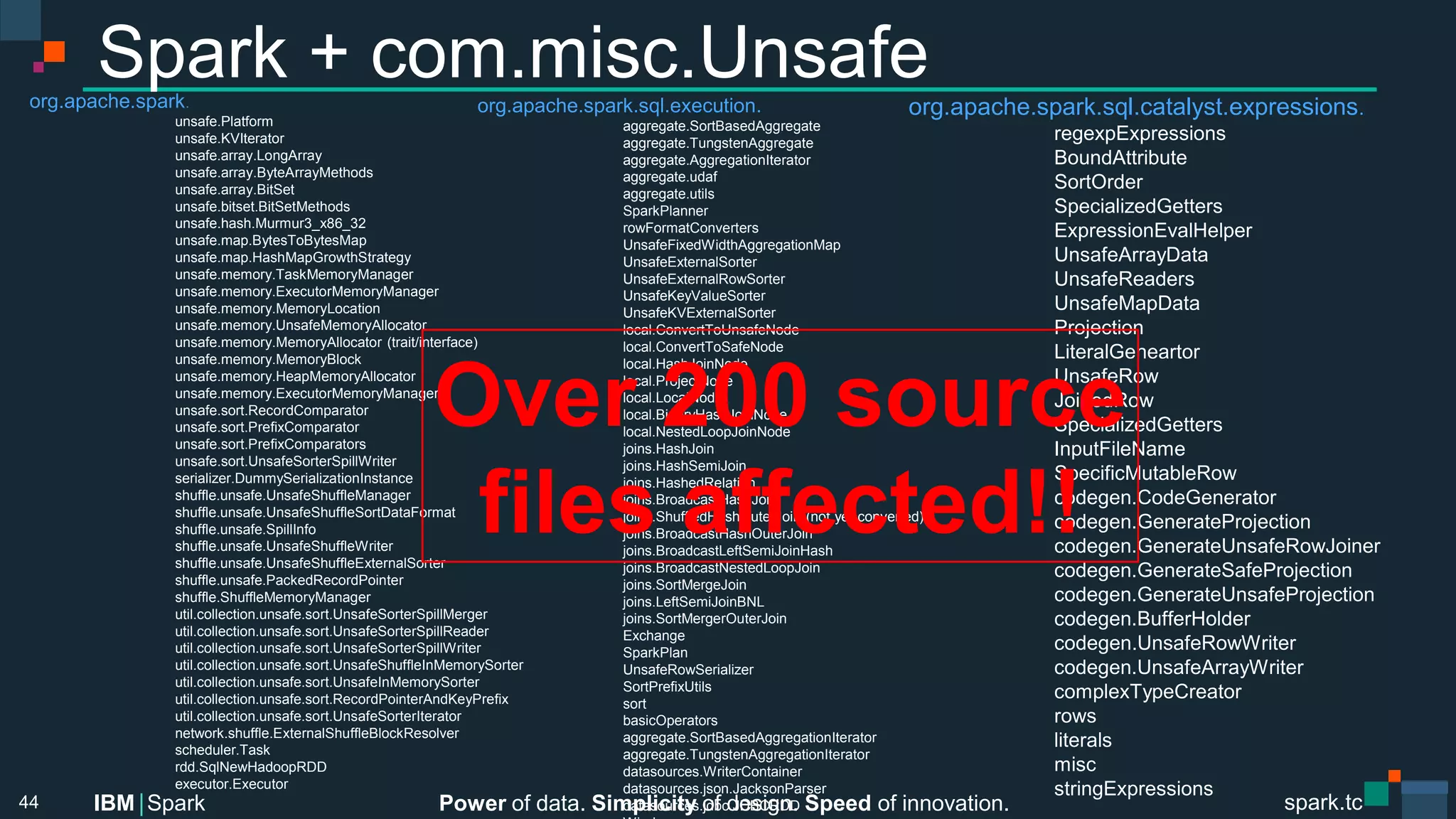
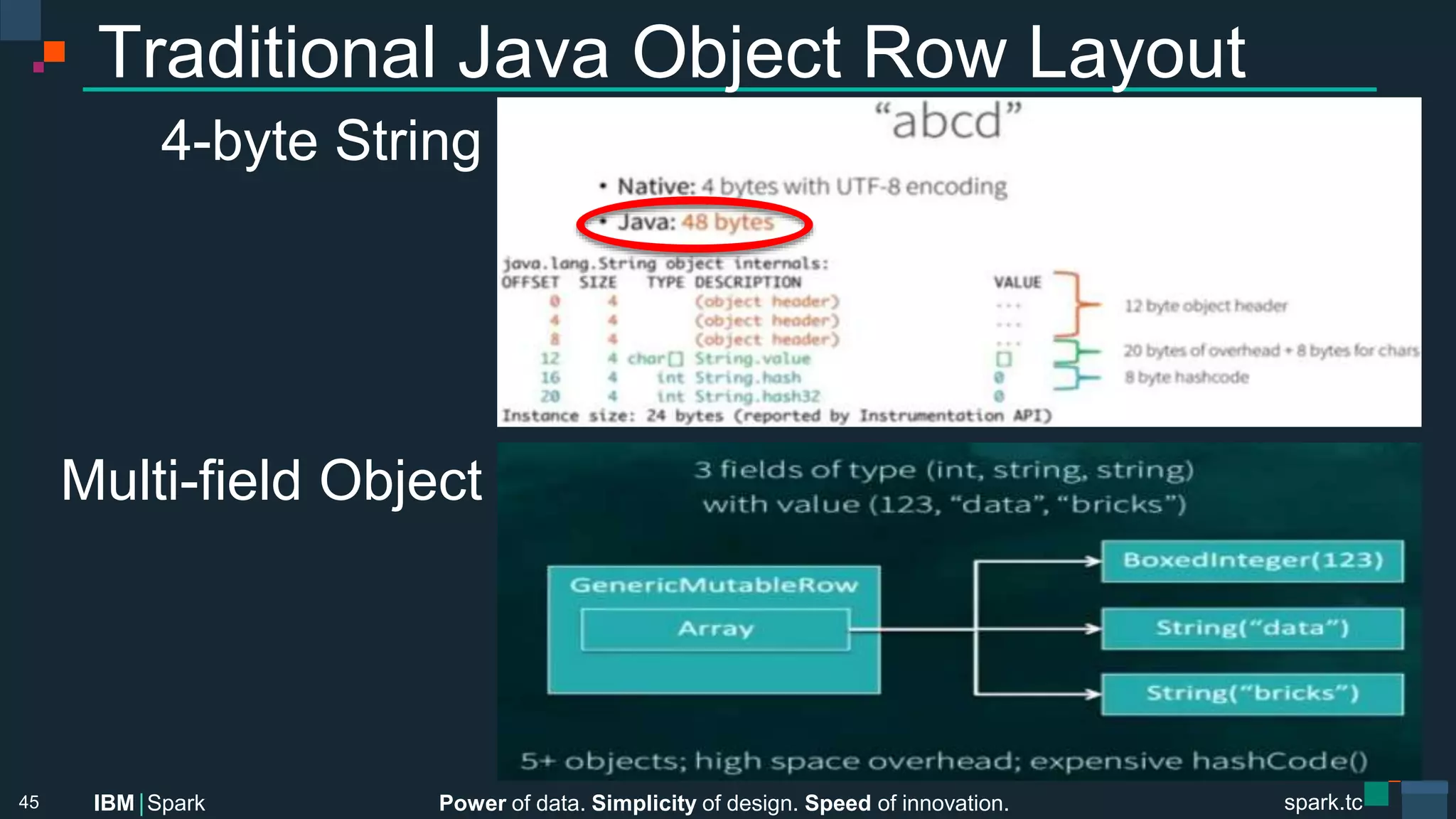
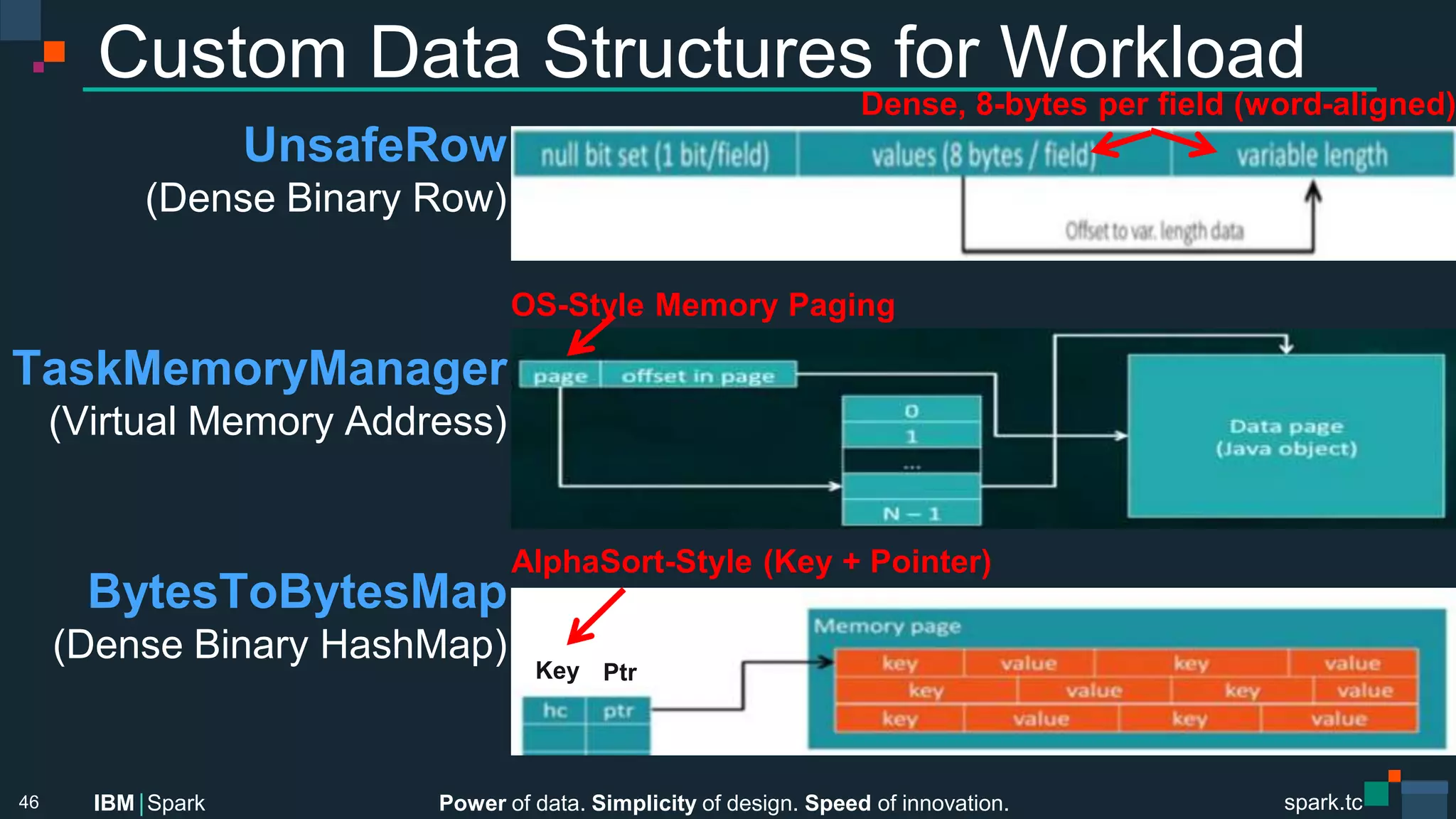
![Power of data. Simplicity of design. Speed of innovation.
IBM Spark
spark.tc
spark.tc
Power of data. Simplicity of design. Speed of innovation.
IBM Spark
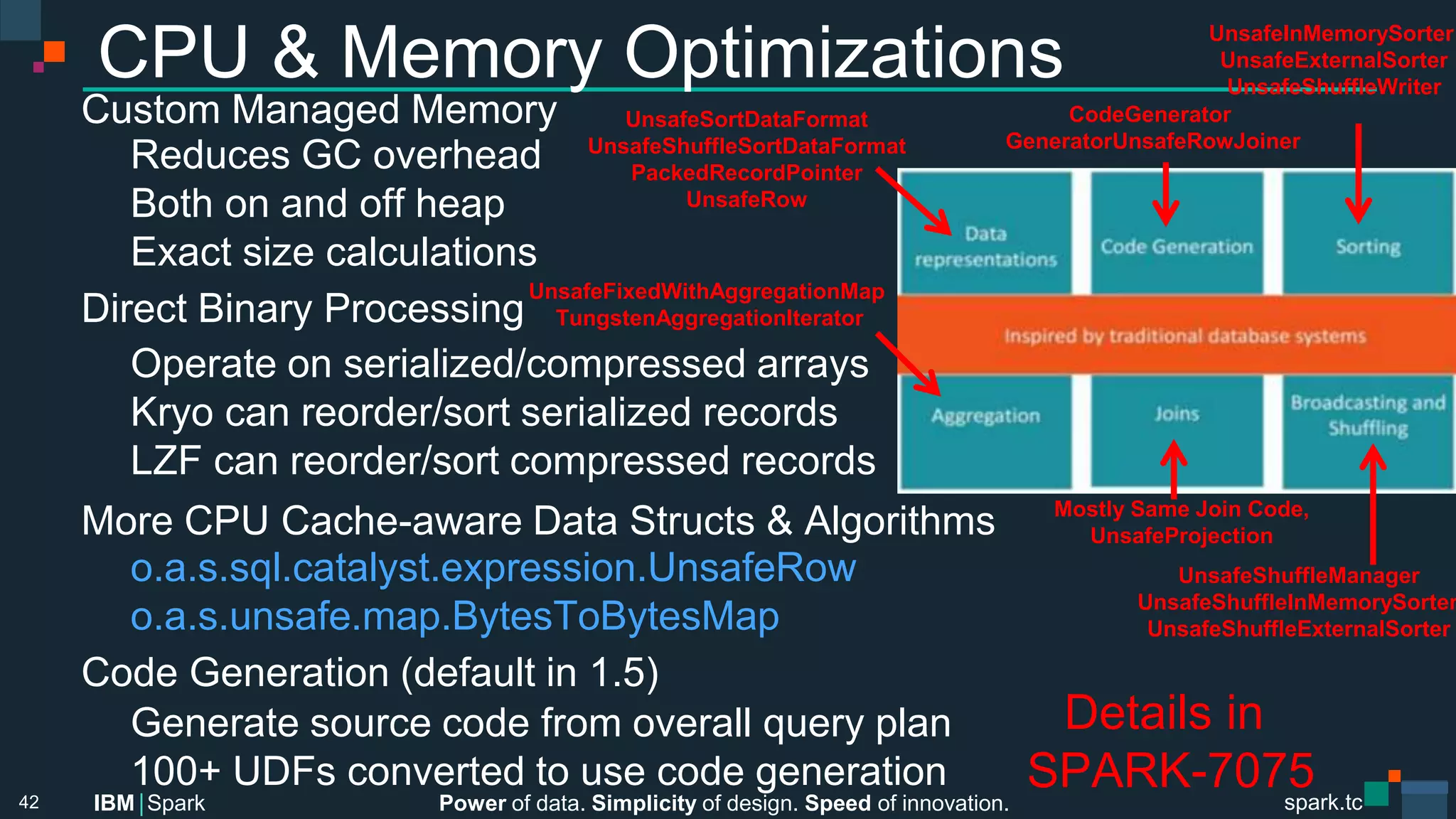
Custom Memory Management
o.a.s.memory.
TaskMemoryManager & MemoryConsumer
Memory management: virtual memory allocation, pageing
Off-heap: direct 64-bit address
On-heap: 13-bit page num + 27-bit page offset
o.a.s.shuffle.sort.
PackedRecordPointer
64-bit word
(24-bit partition key, (13-bit page num, 27-bit page offset))
o.a.s.unsafe.types.
UTF8String
Primitive Array[Byte]
48
2^13 pages * 2^27 page size = 1 TB RAM per Task](https://image.slidesharecdn.com/advancedapachesparkmeetup-projecttungsten-nov122015-151113030443-lva1-app6891/75/Advanced-Apache-Spark-Meetup-Project-Tungsten-Nov-12-2015-48-2048.jpg)









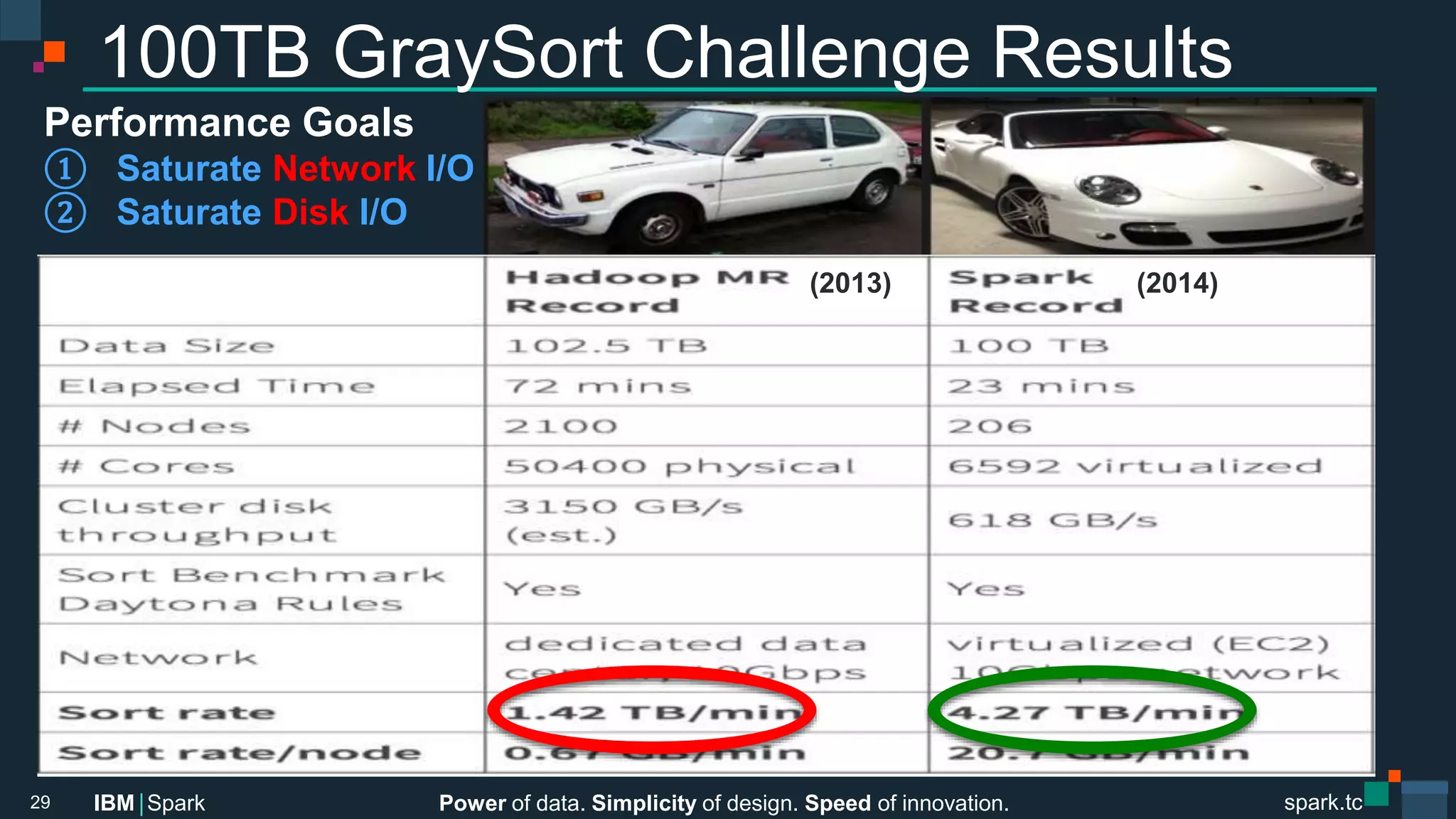
The document summarizes a presentation given by Chris Fregly on Project Tungsten and optimizations in Apache Spark. It discusses techniques like using off-heap memory, minimizing cache misses, and saturating I/O to sort 100 terabytes of data in Spark. The presentation also covered a recap of the "100TB GraySort challenge" where custom data structures and algorithms were used to optimize sorting and shuffling of data.





















































































