Downloaded 216 times





![<86>May 15 20:29:59 rh6-x64-test-template sshd[32632]: Accepted publickey for jdoe from 10.3.1.1 port 62902
ssh2
RSyslog
<86>May 15 20:29:59 rh6-x64-test-template sshd[32632]: Accepted publickey for jdoe from 10.3.1.1 port 62902
ssh2
Kafka (topic=rawUnStructured)
Spark (Apply Regex match/extract, map to JSON)
topic=NormalizedStructured
JSON = {
"srcIP": "10.3.1.1",
"srcPort": "62902",
"serviceType": "authentication",
"regexMatch":
"sshdAcceptedSessionsLinux",
"user": "jdoe",
"product": "Linux",
"@version": "1",
"@timestamp": "2015-05-15T20:30:53.714Z"
}
Kafka
topic=sshdAcceptedSessionsLinux
JSON = {
"srcIP": "10.3.9.1",
"srcPort": "62902",
"serviceType": "authentication",
"regexMatch": "sshdAcceptedSessionsLinux",
"user": "jdoe",
"product": "Linux",
"@version": "1",
"@timestamp": "2015-05-15T20:30:53.714Z"
}
topic=srcIP
1.1.1.1
2.2.2.2
4.4.4.4
topic=User
joe
jane
doe
john …..
topic=dstIP
10.1.1.1
10.2.2.2
7.2.2.2
3.3.3.3](https://image.slidesharecdn.com/07shreedharanjain-150624014141-lva1-app6892/85/Tagging-and-Processing-Data-in-Real-Time-Hari-Shreedharan-and-Siddhartha-Jain-Cloudera-and-Salesforce-7-320.jpg)






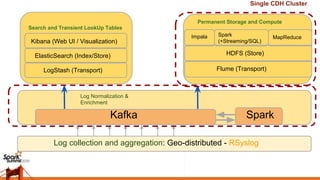
This document discusses using Spark Streaming to process and normalize log streams in real time from 100k events per second to over 1 million per second. It proposes using RSyslog to collect logs from multiple sources into Kafka, then using Spark Streaming to apply regex matching and extract fields to normalize the data into a structured JSON format and write it to additional Kafka topics for storage and further processing. The solution was able to process 3 billion events per day with less than 20 seconds of end-to-end delay at peak throughput.































































































![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Laila Kakar - Leveraging AI for Strategic Excellence: Enhanci...](https://cdn.slidesharecdn.com/ss_thumbnails/eykmhrtsqmaaftwkexh7-dsc-lailakakar-1-260119101520-5f3b5616-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Milovan Jovicic - Beyond AI's Reach: The Enduring Value of Ev...](https://cdn.slidesharecdn.com/ss_thumbnails/pyeij0hurgwq5jugmtnv-2-milovan-jovicic-beyond-ais-reach-the-enduring-value-of-evergreen-design-v2-260120105856-d6ee57e5-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)
