Downloaded 29 times




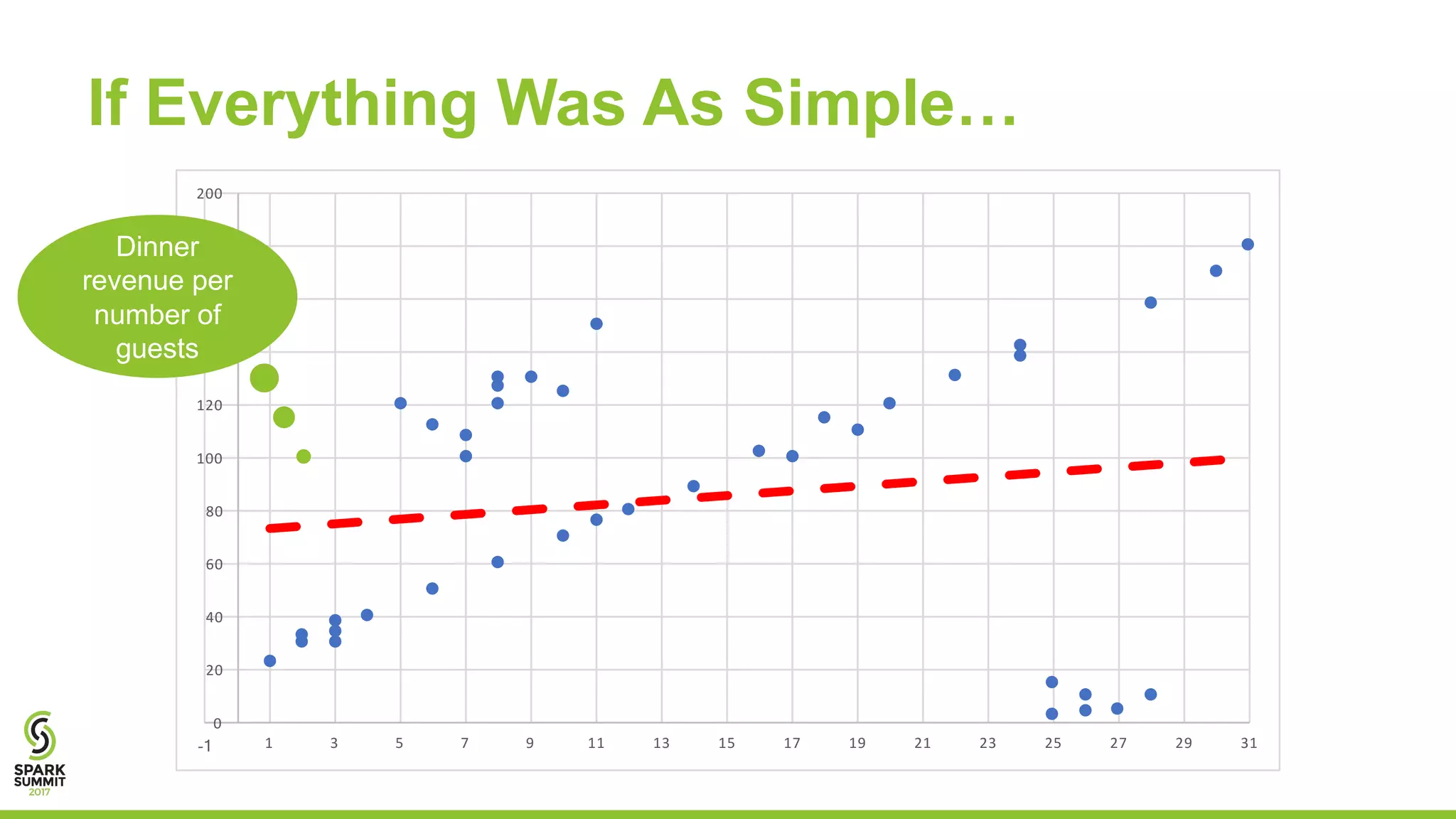
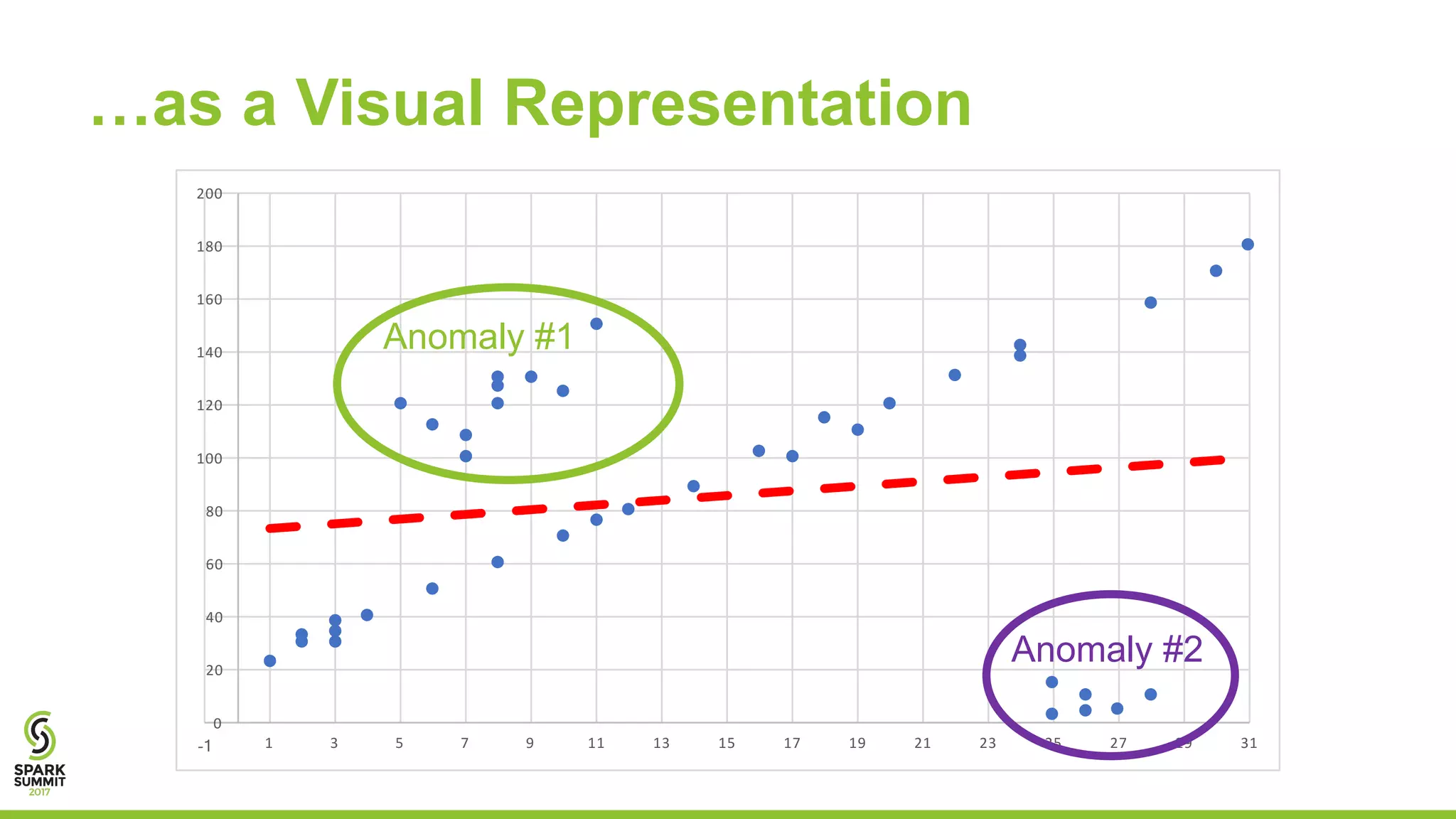
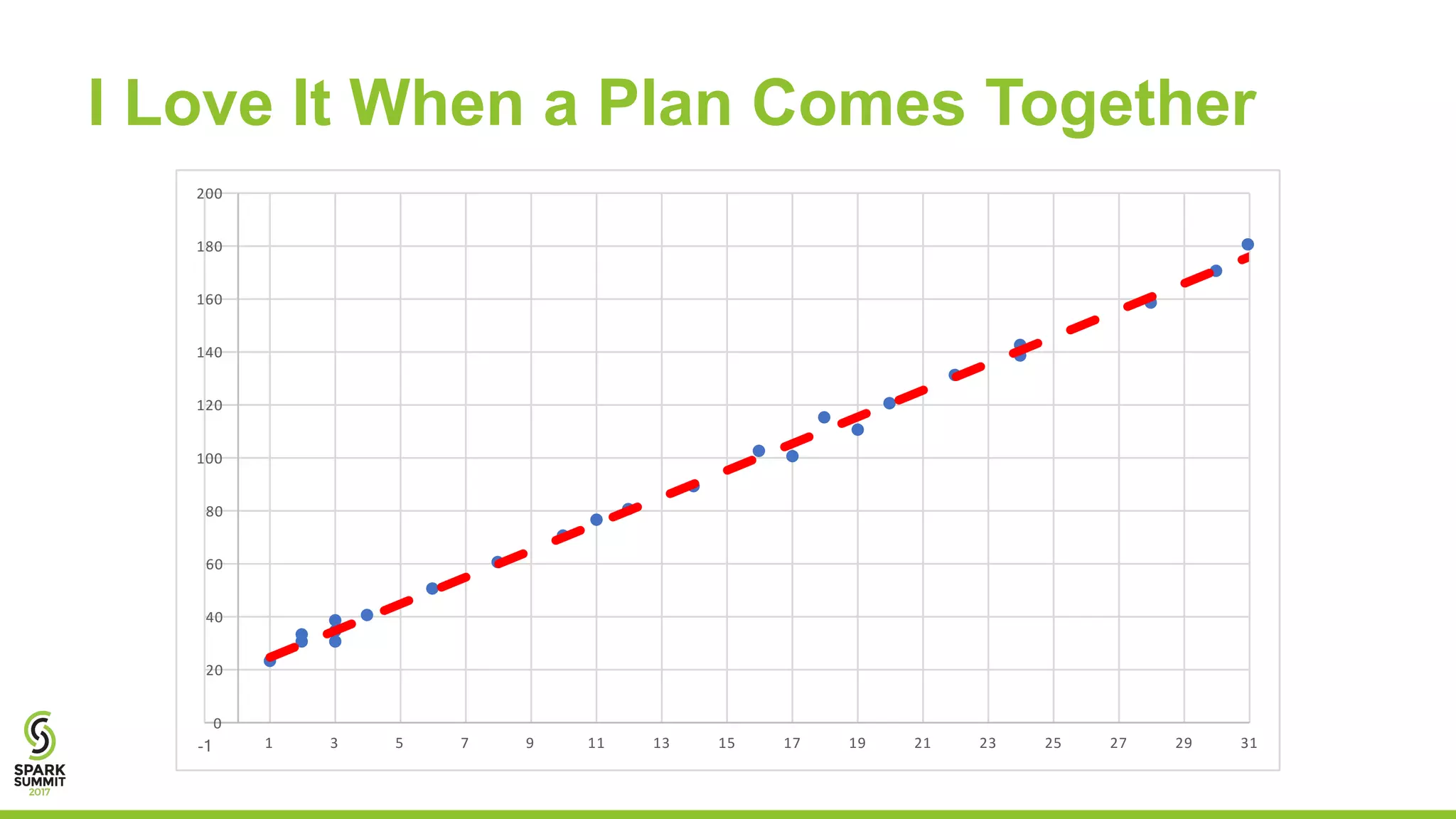












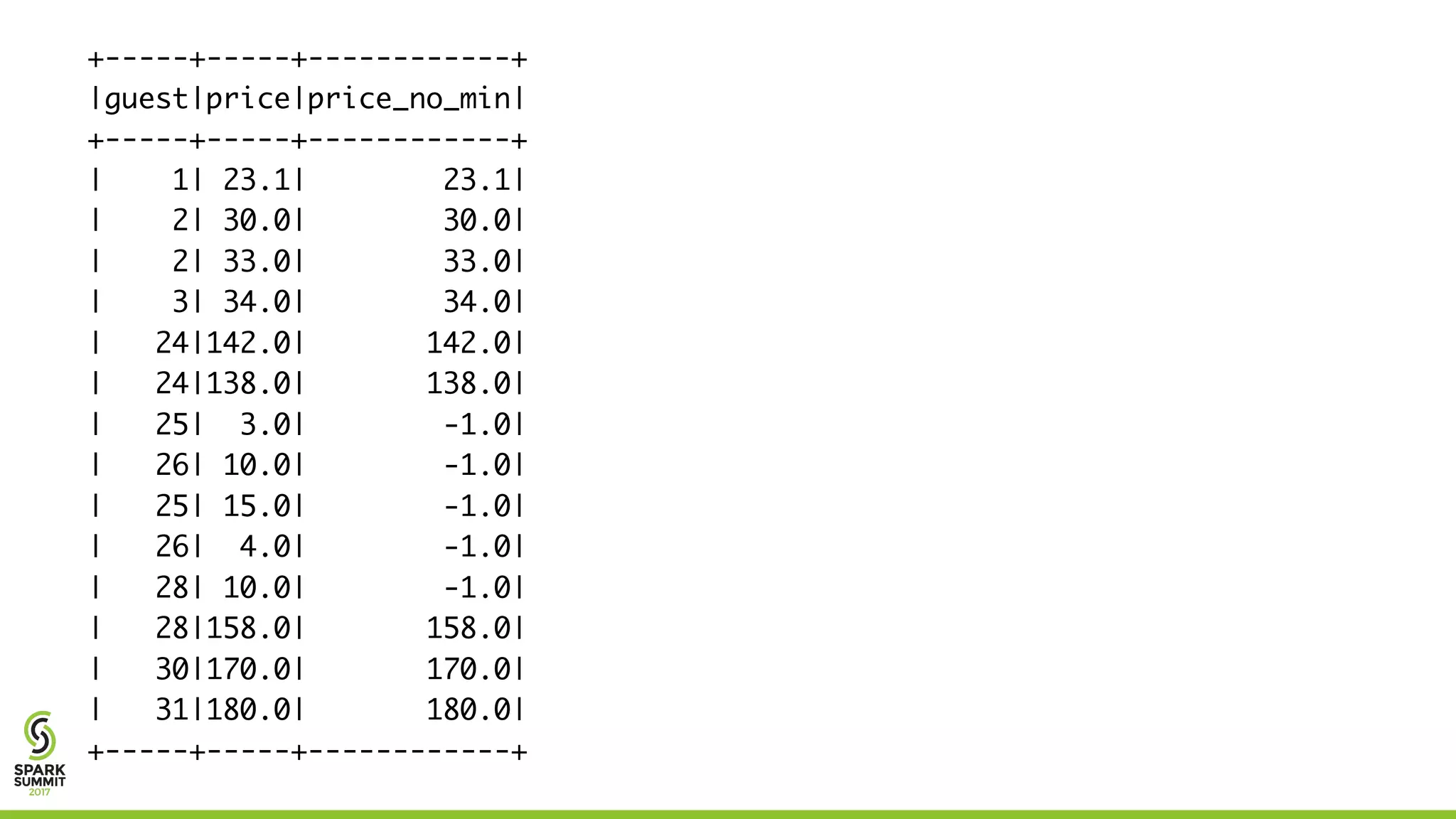





![+-----+-----+-----+--------+------------------+
|guest|price|label|features| prediction|
+-----+-----+-----+--------+------------------+
| 1| 23.1| 23.1| [1.0]|24.563807596513133|
| 2| 30.0| 30.0| [2.0]|29.595283312577884|
| 2| 33.0| 33.0| [2.0]|29.595283312577884|
| 3| 34.0| 34.0| [3.0]| 34.62675902864264|
| 3| 30.0| 30.0| [3.0]| 34.62675902864264|
| 3| 38.0| 38.0| [3.0]| 34.62675902864264|
| 4| 40.0| 40.0| [4.0]| 39.65823474470739|
| 14| 89.0| 89.0| [14.0]| 89.97299190535493|
| 16|102.0|102.0| [16.0]|100.03594333748444|
| 20|120.0|120.0| [20.0]|120.16184620174346|
| 22|131.0|131.0| [22.0]|130.22479763387295|
| 24|142.0|142.0| [24.0]|140.28774906600245|
+-----+-----+-----+--------+------------------+
Prediction for 40.0 guests is 220.79136052303852](https://image.slidesharecdn.com/229jeangeorgesperrin-170615200356/75/The-Key-to-Machine-Learning-is-Prepping-the-Right-Data-with-Jean-Georges-Perrin-28-2048.jpg)













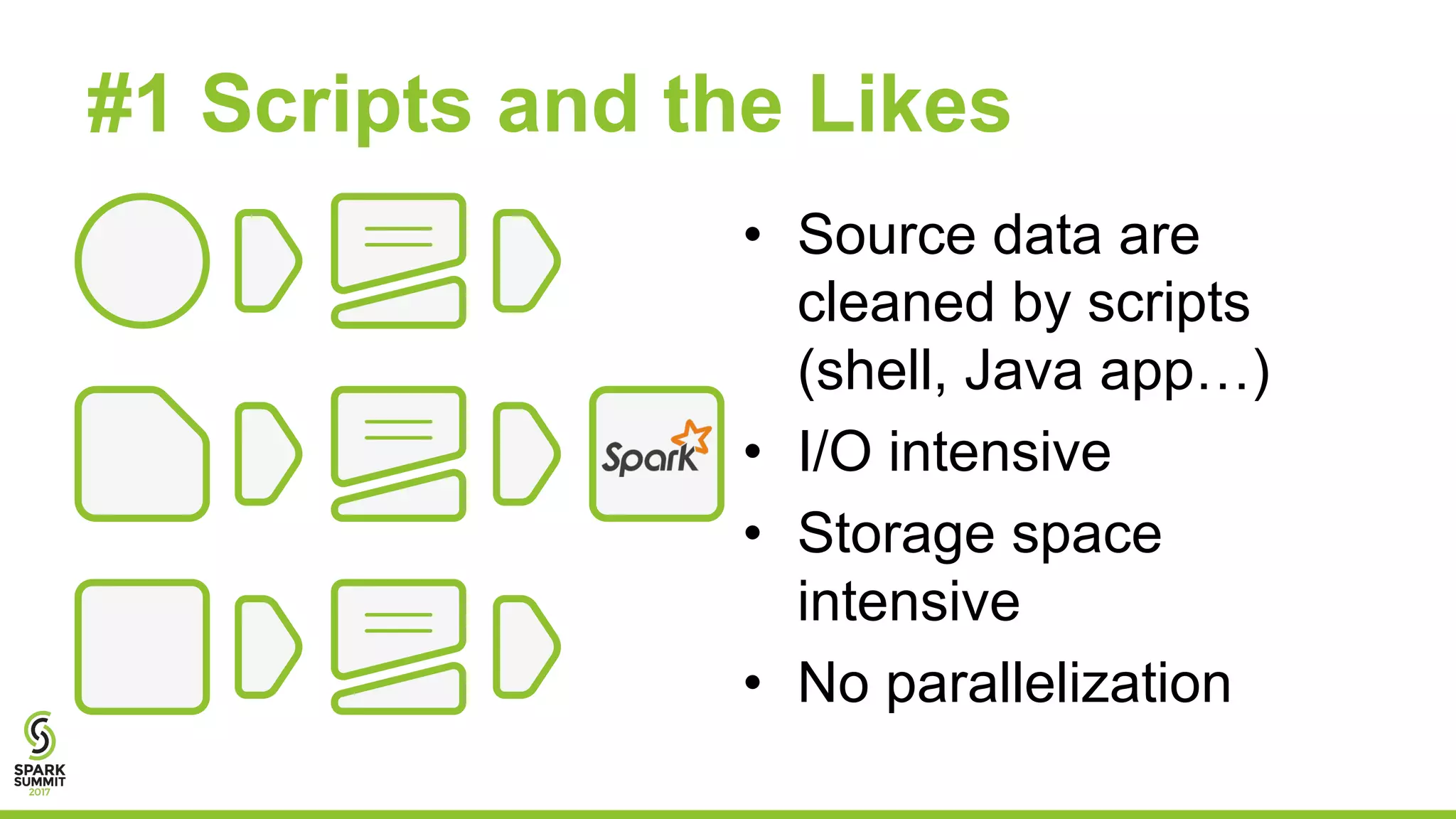
The document discusses preparing data for machine learning by applying data quality techniques in Spark. It introduces concepts of data quality and machine learning data formats. The main part shows how to use User Defined Functions (UDFs) in Spark SQL to automate transforming raw data into the required formats for machine learning, making the process more efficient and reproducible.




































































![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Vladimir Jelic - The AI-Driven Security Shift From Reactive D...](https://cdn.slidesharecdn.com/ss_thumbnails/6g5gj25mtjwayniqem1t-6-251209104645-7a5a5fc6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)



