Download as PDF, PPTX
















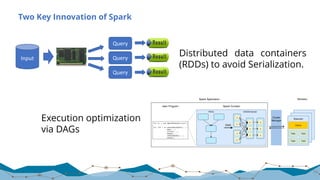

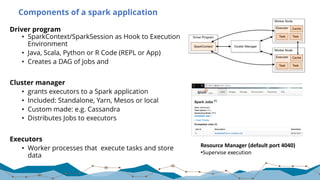







![Spark SQL
Spark SQL uses DataFrames (Typed Data Containers) for SQL
Hive:
c = HiveContext(sc)
rows = c.sql(“select * from titanic”)
rows.filter(rows[‘age’] > 25).show()
JSON:
c.read.format(‘json’).load(’file:///root/tweets.json”).registerTe
mpTable(“tweets”)
c.sql(“select text, user.name from tweets”)
39
28.01.17](https://image.slidesharecdn.com/20170126bigdataprocessing-170203193510/85/20170126-big-data-processing-39-320.jpg)






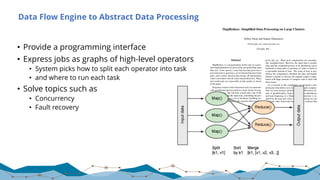
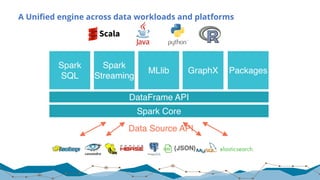
![Expressive APIs
51
case class Word (word: String, frequency: Int)
val lines: DataStream[String] = env.fromSocketStream(...)
lines.flatMap {line => line.split(" ")
.map(word => Word(word,1))}
.window(Time.of(5,SECONDS)).every(Time.of(1,SECONDS))
.groupBy("word").sum("frequency")
.print()
val lines: DataSet[String] = env.readTextFile(...)
lines.flatMap {line => line.split(" ")
.map(word => Word(word,1))}
.groupBy("word").sum("frequency")
.print()
DataSet API (batch):
DataStream API (streaming):](https://image.slidesharecdn.com/20170126bigdataprocessing-170203193510/85/20170126-big-data-processing-51-320.jpg)
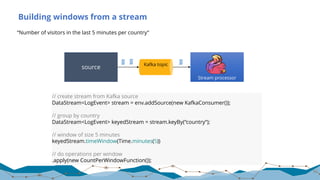
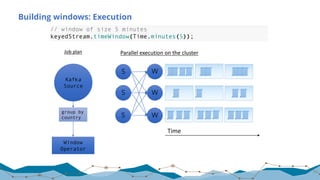
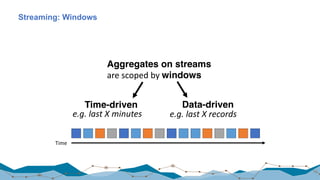

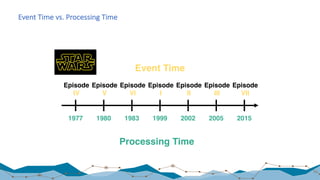


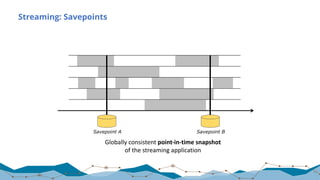

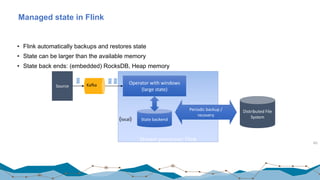



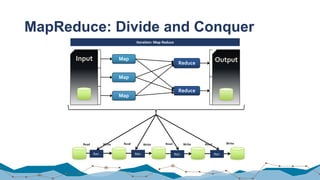
![Yahoo! Benchmark
• Count ad impressions grouped by campaign
• Compute aggregates over a 10 second window
• Emit window aggregates to Redis every second for query
70
Full Yahoo! article: https://yahooeng.tumblr.com/post/135321837876/benchmarking-
streaming-computation-engines-at
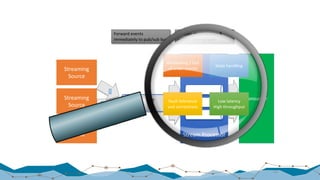
“Storm […] and Flink […] show sub-second latencies at relatively high
throughputs with Storm having the lowest 99th percentile latency.
Spark streaming 1.5.1 supports high throughputs, but at a relatively higher
latency.”
(Quote from the blog post’s executive summary)](https://image.slidesharecdn.com/20170126bigdataprocessing-170203193510/85/20170126-big-data-processing-70-320.jpg)
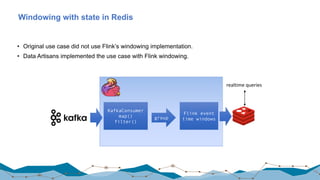



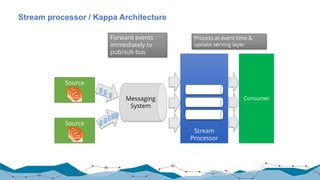
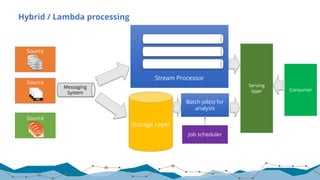
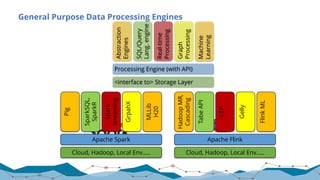
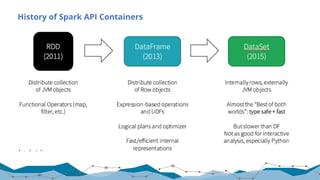
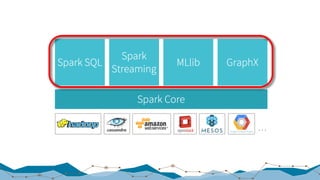
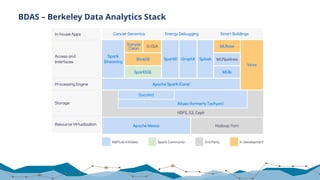
The document discusses big data processing techniques and technologies, focusing on architectures like Apache Spark and Apache Flink. It details the evolution of data processing engines, data processing patterns, components, and their advantages over previous frameworks. Additionally, it covers implementation details, programming interfaces, and performance metrics relevant to data processing tasks across varied industries.











































































































